マッピングの設定
Version 25.3.9469
Version 25.3.9469
マッピングの設定
以下のXML Map マッピングページ画像には、画面上の各要素を説明するための注釈が付いています(EDI ドキュメントマッピングも同様です)。各番号は以下の説明に対応しています。
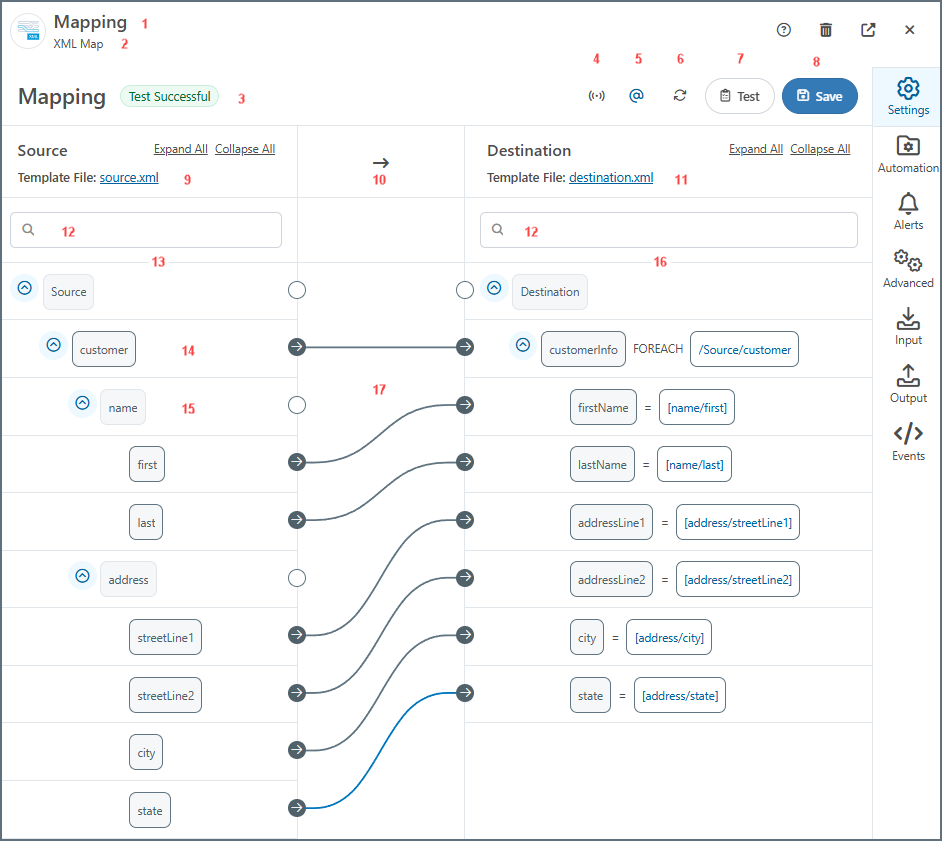
- ドキュメントまたはコネクタの名前。
- コネクタの種類。
- マッピングのステータス。値はテスト成功、テスト済み(エラー)、または未テスト。
- XML ストリーミングのON / OFF 切り替え(デフォルトはON)。ON にすると、マッピングエンジンはループ完了後に、マッピング内の最上位
Foreachの現在の反復のドキュメントオブジェクトモデル(DOM)を削除します。これにより、大規模なXML ドキュメントのパフォーマンスが大幅に向上します。マッピングエンジンがマッピングを解決できない場合、XML ストリーミングは自動的にOFF になります。 - マッピングの通常表示とコンパクト表示の切り替え(大きなテンプレートファイルではコンパクト表示が便利です)。
- XML 属性の表示 / 非表示の切り替え。
- マッピングをリフレッシュ。
- AI アシストマッピングツールを起動。
- マッピングをテストページを開く。テスト結果が3 に表示されます。(詳しくは、マッピングのテストを参照してください。
- マッピングを保存。
- 選択されたソーステンプレートファイル。
- マッピングの方向。
- 選択された宛先テンプレートファイル。
- ソース側と宛先側の検索バー。
- ソースXML の構造。
- 親ノードの名前。
- リーフノードの名前。
- 宛先ドキュメントの構造。
- 完了したマッピング。
ソースと宛先の理解
マッピングを定義するには、左側のペインからノードをクリックして、右側の対応するオブジェクトにドラッグします。ノードが選択されると、その接続線は青色になり、その他の線はすべて黒色になります。
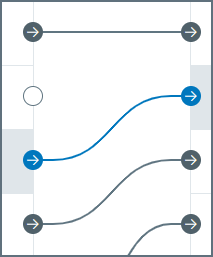
ソースまたは宛先ツリーで要素をドラッグ&ドロップすると、次の画像に示すように、ドロップノードの青い線の一方または両方が濃く / アクティブになります。両方がアクティブな場合、ドラッグされているノードはドロップノードの兄弟として作成されます。右の線のみがアクティブな場合、ドラッグされているノードはドロップノードの子として作成されます。次の画像では、N103 ノードがN104 の下からN102 ノードの直接の兄弟になるように移動されているため、青い線が両方とも強調表示されています。
マッピングを削除するには、マッピングの一端にマウスを合わせてマッピングを削除をクリックします。マッピングの定義が完了したら、保存をクリックします。
ノードのマッピング
親ノードとリーフノードは、XML データの階層構造を定義します。親ノードは関連する要素をグループ化し、リーフノードはマッピングされる実際のデータ値を表します。
- 親:リーフ要素を含むが値を持たないXML マッピングツリー内のノード。親ノードは、TPMC のテーブルノードに似ています。
- リーフ:値を含むが子要素を持たないノード。リーフノードは、TPMC のカラムノードに似ています。
次のセクションでは、親ノードとリーフノードのオプションについて詳しく説明します。
親ノード
XML 親要素
前述したように、マッピングエディタのツリーには2種類のノードがあります:
- 親ノードは、子を持ちますが値を持ちません。
- リーフノードは、値を持ちますが子を持ちません。
ソースの親ノードは、宛先の親ノードにのみドラッグできます。
ソースの親を宛先の親にドラッグすると、ソースノードと宛先ノードの間にForeach 関係が確立されます。これは、ソース要素が出現するたびに、宛先要素のすべての子を含む対応する宛先要素が生成されることを意味します。
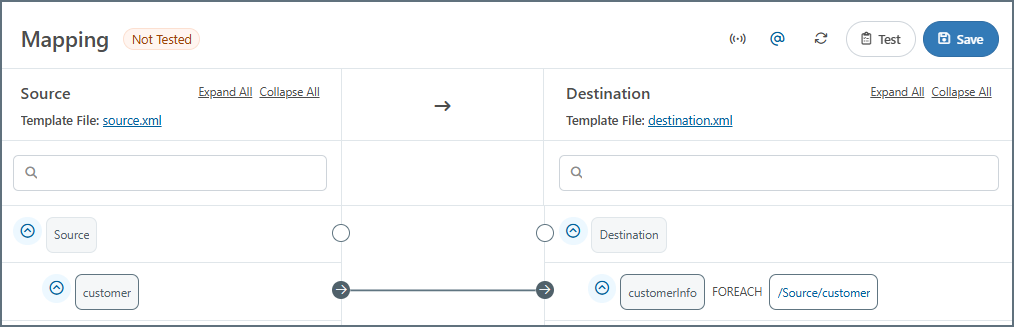
Foreach 関係が確立されると、下の画像に示すように、宛先にXPath が表示されます。入力XML 内のこのパスにある要素は、出力ノードとその子の新しいインスタンスを生成します。つまり、Foreach 関係は、マッピングエンジンにソース内の特定のXPath をループし、見つかった要素ごとにマッピングされた宛先構造を生成するように指示します。宛先ツリービュー内のXPath は、マッピングエンジンがループするXPath です。
仮想ループ
仮想ループは、出力XML に直接表示されない、宛先構造に追加できる特別なノードです。出力内の他の(非仮想)ノードの外観や値に影響するロジックを実装する機会を提供します。
親ノードが出力XML に表示されない点を除いて、親ノード間のForeach マッピングと同じように機能します。これにより、ソース内の繰り返し要素を、宛先の非階層構造にフラット化できます。具体例を使って説明しましょう。
次の入力XML を考えてみます:
<!-- example input -->
<Items>
<DataReading>
<Temperature>212.5</Temperature>
</DataReading>
<DataReading>
<Temperature>9.2</Temperature>
</DataReading>
<DataReading>
<Temperature>5.1</Temperature>
</DataReading>
</Items>
これは、すべての DataReading データを含むフラットな構造にマッピングする必要があります:
<!-- desired output -->
<Items>
<OutputData>
<TemperatureReading>212.5</TemperatureReading>
<TemperatureReading>9.2</TemperatureReading>
<TemperatureReading>5.1</TemperatureReading>
</OutputData>
</Items>
これは、ソース内の各 DataReading 要素に対応する宛先内のループノードとのForeach 関係を確立することで実現できます:
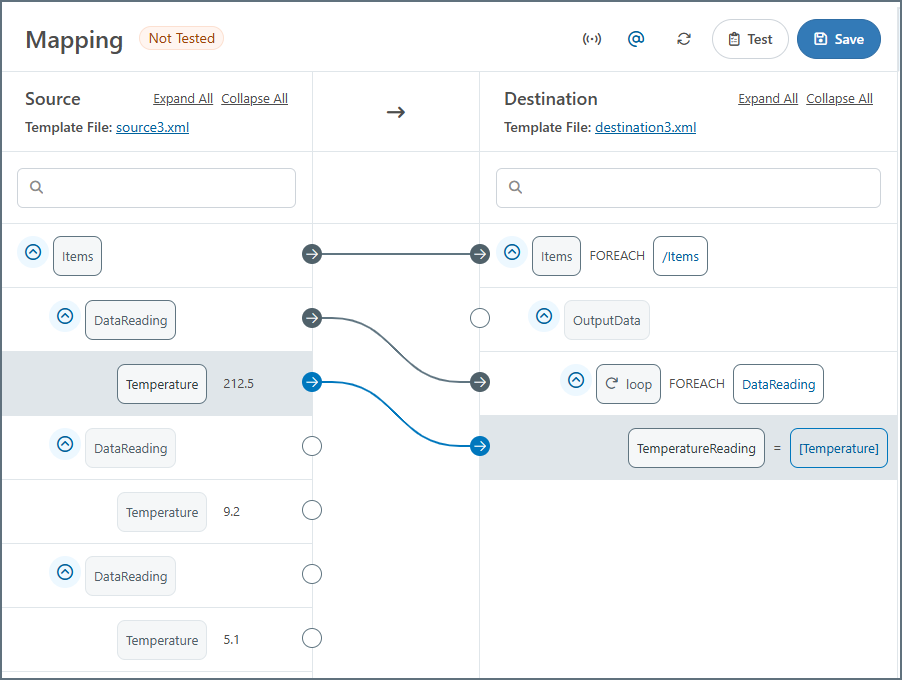
Foreach 関係が DataReading と OutputData の間に確立された場合、 OutputData 要素が結果内で繰り返されます。ループノードはこの階層の繰り返しを回避し、値を単一の OutputData 要素にフラット化します。
上記の例に示されているループノードを追加するには、以下の手順に従います:
- TemperatureReading ノードを右クリックするか省略記号をクリックし、ノードを選択 > ループを追加を選択します。ループにわかりやすい名前を付け、チェックマークをクリックして保存します。
- ソースの DataReading ノードをループにドラッグしてForeach 関係を作成します。
- ソースの Temperature ノードを宛先の TemperatureReading ノードにマッピングします。
仮想条件
仮想条件は、共有条件に基づいて出力要素をグループ化します。条件ノードのすべての子は、条件がtrue の場合は出力に表示され、条件がfalse の場合は表示されません。
これは、個々のノードに同じ条件を個別に追加することと機能的に同じです。多くの異なるノードに影響する条件の場合、一般的には、単一の条件ノードを作成して関連するすべての出力ノードをその条件ノードの子にする方が便利です。
条件仮想ノードを作成するには、次の手順に従います:
- 宛先ノードを右クリックするか省略記号をクリックし、ノードを選択 > 条件を追加を選択します。
- 新しい条件の横にあるファンネルアイコンをクリックして、条件ルールを作成します。詳しくは、条件エディタの使用を参照してください。
リーフノード
XML リーフ要素
ソースリーフを宛先リーフにドラッグすると、宛先要素にソース要素の値を入力するようマッピングエンジンに指示します。宛先ノードにドラッグ&ドロップすると、以下の画像に示すように、値が読み取られるXPath が宛先ツリービューに表示されます。
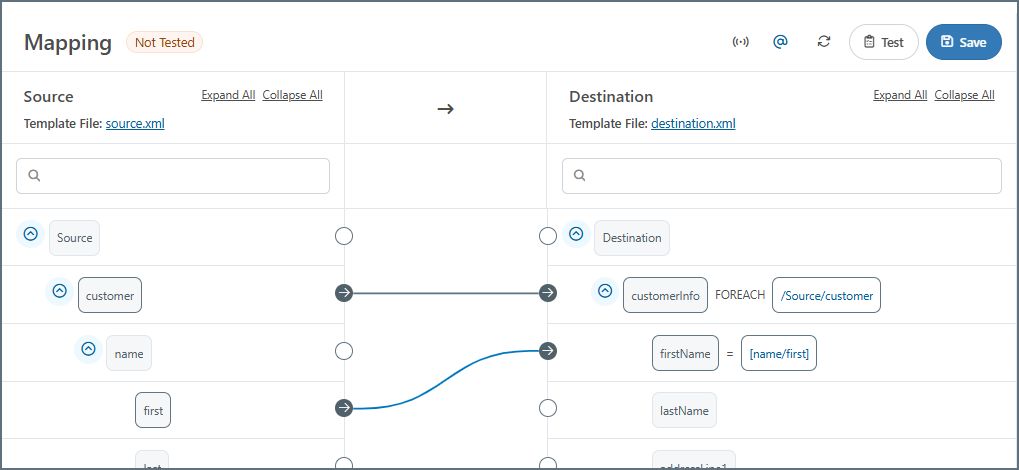
宛先ツリービューに表示されるXPath は、絶対または相対のいずれかです。絶対XPath はスラッシュ(/)で始まり、ドキュメントのルートから始まるソース内の完全なXPath を記述します。相対XPath はスラッシュで始まらず、親ノードに設定されたForeach ループを基準とします。
相対XPath は、複数のForeach ループに対して相対的であることができます(要素がそれぞれForeach 関係がマッピングされた複数の親を持つ限り)。任意の相対XPath の絶対XPath を見つけるには、ドキュメントの最上位から現在のノードに到達するまで、各親要素のForeach XPath を連結します。
XML 属性
要素値に加えてXML 属性を操作するには、マッピングページの上部にあるアトリビュートを表示設定がON になっていることを確認します( )。有効にすると、エディタには、その属性が属する要素の子として検出されたすべての属性が表示されます。
)。有効にすると、エディタには、その属性が属する要素の子として検出されたすべての属性が表示されます。
すべてのXML 属性名には@ プレフィックスが付けられます(@ 記号はXML 要素名では有効な文字ではありません)。この文字は表示のみを目的としており、属性の読み取りまたは書き込み時には削除されます。
ソースからXML 属性を読み取る
アトリビュートを表示トグルを有効にすると、XML ソース内のすべての属性がマッピングエディタにノードとして表示されます。これらの値は、他のノードと同様に宛先にドラッグ&ドロップできます。次の画像に示すように、ノードにはXML 要素ではなくXML 属性であることを示す@ プレフィックスが表示されます。
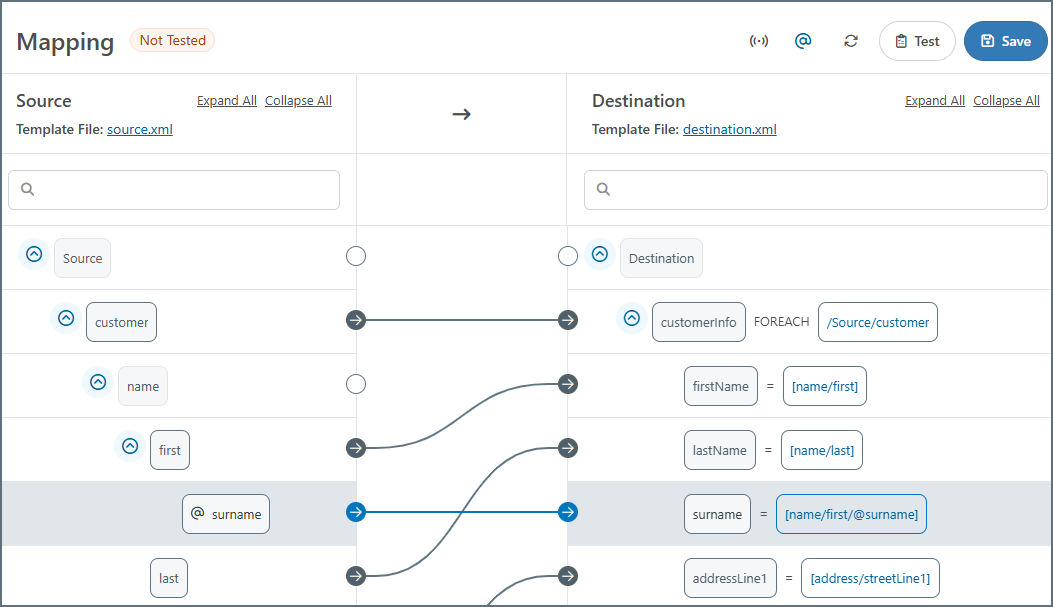
宛先にXML 属性を書き込む
XML 属性を含む宛先テンプレートでは、属性ノードは所属する要素の子として表示され、他の値と同様にマッピングできます。
宛先ノードに新しい属性を追加するには、ノードを右クリックするか省略記号をクリックして、ノードを追加 > アトリビュートを追加を選択します。
Note:属性名は常に@ プレフィックスで始まります(この文字は出力XML には含まれません)。
ヘッダー
ヘッダーノードを使用すると、マッピングの出力メッセージに値をヘッダーとしてマッピングできます。これらのヘッダーノードは出力XML には含まれません。代わりに、出力メッセージのメタデータメッセージヘッダーとして追加されます。これらのヘッダーはフロー全体を通じてメッセージに保持され、必要に応じて下流のコネクタで値を参照できます。これにより、アプリケーション内のデータの流れを簡単に追跡できます。ヘッダーノードは、ノード値エディターのメッセージヘッダータブに自動的に追加されます。ヘッダーノードを追加するには、既存のノードを右クリックするか、省略記号をクリックして、追加 > ヘッダーを追加を選択します。
ヘッダーノードは追跡されたヘッダーには追加されません。ノードの省略記号をクリックしてトラッキングを追加を選択することで、非ヘッダーの宛先ノードを追跡ヘッダーに追加できます。詳しくは、メッセージヘッダーを参照してください。
コードスクリプト
コードスクリプト仮想ノードを使用すると、出力値を返す必要のないカスタムArcScript を記述できます。多くの場合、これらのノードは変数または特別な_map アイテムを使用して、マッピングの後の段階で参照する必要があるものの、現在のコンテキストでは出力する必要がない値を格納します。
例えば、Map Item セクションで説明するシナリオは、仮想コードスクリプトノードの良い候補です。明細項目のコストの合計は、計算されるForeach ループの 外 で出力として返す必要があります。そのため、Foreach ループ 内 の仮想コードスクリプトノードで値を計算し、出力しないようにできます。その後、この値はループ 外 の非仮想ノードで出力として参照できます。
コードスクリプト仮想ノードを作成するには、以下の手順に従います:
- 宛先ノードを右クリックするか、省略記号をクリックして、ノードを追加 > コードスクリプトを追加を選択します。
- スクリプト名を入力します。
- スクリプトを入力します。エディタは入力中に式を検証するため、構文に問題がある場合は無効なスクリプトのメッセージが表示されます。終了したら、スクリプトを追加をクリックします。
変数ノード
マッピングのある時点で変数を設定し、その変数をマッピングの後半で再度参照することは有用です。詳細と例については、変数を参照してください。
ノードオプション
個々のノードを操作するには、ノードにカーソルを合わせて右クリックするか、省略記号をクリックして追加のオプションから選択します。オプションは、操作するノードの種類によって異なります。このセクションでは、親ノード、リーフノード、またはドキュメントノードを操作する際に使用できるオプションについて説明します。これらのノードの種類に関する詳細は、Table Nodes およびColumn Nodes を参照してください。
- ノード名を変更では、ノード名を変更できます。
- XPath を編集では、ノードのXPath を編集できます(すでに
Foreachとしてマッピングされている要素のみ)。 - ノードを削除では、ドキュメントからノードを削除できます。
- ノードを追加
- 兄弟を追加は、選択したノードと同じレベルにノードを追加します。
- アトリビュートを追加は、選択したノードにアトリビュートを追加します。
- 子を追加は、選択したノードの子としてノードを追加します。
- ヘッダーを追加は、値をマッピングできるヘッダーノードを作成します。マッピングされた値は出力ファイルに含まれませんが、マッピング出力メッセージのヘッダーとして追加されます。
- ループを追加は、選択したノードの上にループノードを作成し、そのノードはループノード内にネストされます。詳しくは、ループのマッピングを参照してください。
- 条件を追加は、条件エディタを開きます。ここで条件を追加して、条件がtrue の場合にのみデータが宛先にアップサートされるように設定できます。
- コードスクリプトを追加は、ターゲット要素の兄弟として新しいスクリプトコードを作成します。スクリプトを追加ウィンドウを使用して、スクリプトに名前を付け、カスタムArcScript を入力します。
- 変数を追加は、選択したノードの下に変数ノードを作成します。詳しくは、変数を参照してください。
- ノードを切り取りは、選択したノードを現在の場所から切り取ります。
- ノードをコピーは、選択したノードをコピーします。
- 子として貼り付けは、切り取ったまたはコピーしたノードを、選択したノードの子として貼り付けます。
- トラッキングを追加は、マッピングに追跡されたヘッダーを追加します。ノードでトラッキングが有効になっている場合はコンパスアイコンが表示されます。
ノードを編集を使用してノード値を編集ページを開くこともできます。ノード値エディタの使用を参照してください。
AI アシストマッピング
インスタンスでAI 設定をセットアップし、ソースと宛先のテンプレートファイルをアップロードまたは設定したら、OpenAI またはOllama を使用してマッピング構築を支援できます。この機能は、インテリジェントなマッピング提案を提供してマッピング設定の課題に対処し、正確なデータ変換の作成を大幅に容易にします。
AI でマッピング全体を生成するには、ページ上部の![]() アイコンをクリックします。
アイコンをクリックします。
または、ノードレベルでAI にマッピングを生成させることもできます。ソース側または宛先側の親ノードを右クリックするか省略記号を使用し、AI アシストマッピングを選択して、次のオプションのいずれかを選択します:
- ノードをマッピング
- 子ノードをマッピング
- ノードと子ノード
AI がマッピングを生成した後、必要に応じてそれらを調整できます。
ループのマッピング
親ノードのマッピングを作成すると、ソースノードと宛先ノードの間にForeach 関係が確立されます。これは、ソース要素が出現するたびに、宛先要素のすべてのリーフノードを含む対応する宛先要素が生成されることを意味します。リーフノードのマッピングを作成すると、宛先要素にソース要素の値を入力するようマッピングエンジンに指示します。
親ノード(Foreach ループ)をリーフノードよりも先にマッピングします。ループ関係を確立するには、ソースと宛先のXML 構造を理解する必要があります。ソース内の繰り返し要素が宛先でも繰り返し要素になる場合は、それらの要素をForeach 関係でマッピングする必要があります。
Foreach ループ内では、リーフ要素のXPath はマッピングされたForeach XPath を基準とします。
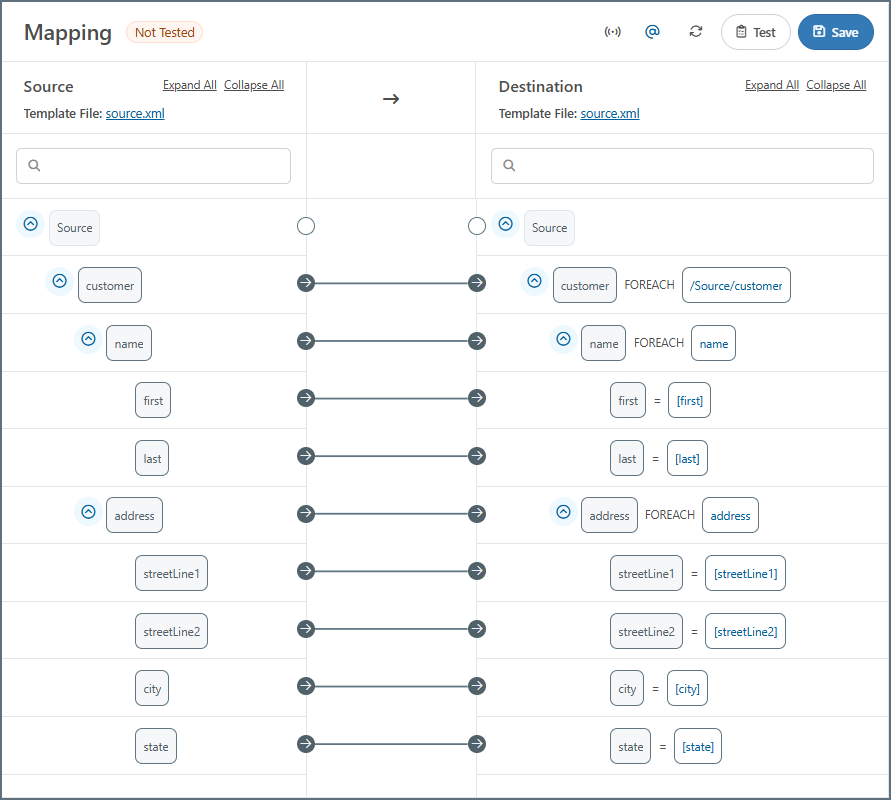
非常に簡単な例として、ネストされたXML 構造をフラットなXML 構造に変換する次のソースXML と宛先XML を考えてみましょう:
<Source>
<customer>
<name>
<first></first>
<last></last>
</name>
<address>
<streetLine1></streetLine1>
<streetLine2></streetLine2>
<city></city>
<state></state>
</address>
</customer>
</Source>
<Destination>
<customerInfo>
<firstName></firstName>
<lastName></lastName>
<addressLine1></addressLine1>
<addressLine2></addressLine2>
<city></city>
<state></state>
</customerInfo>
</Destination>
ソース内の customer 要素が繰り返されるたびに、宛先に customerInfo 要素が作成されるため、これらの親要素を一緒にマッピングしてForeach 関係を形成する必要があります。これにより、各リーフ要素のマッピングはシンプルになります:
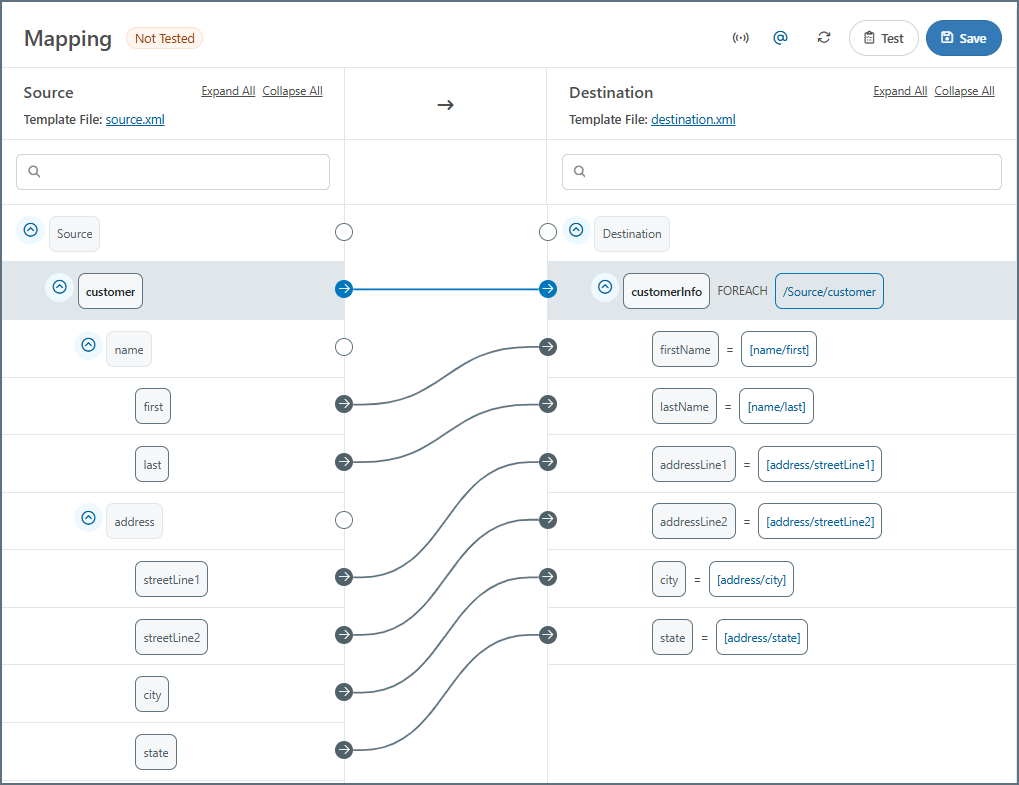
リーフ要素のXPath は、親要素のXPath(Foreach 関係を定義するXPath)を基準としていることに注意してください。
複数ループのマッピング
マッピングでは、多くの場合、同じドキュメント内に複数のForeach ループ関係が必要になります。ループのマッピングの原則は変わりません。宛先で繰り返し要素を生成するソース内の繰り返し親要素は、ループとしてマッピングする必要があります。外側のループを内側のループよりも先にマッピングします(つまり、構造の上部から下に向かって作業を進めます)。すべてのループ関係は、リーフ要素がマッピングされる前にマッピングされる必要があります。
一般的な例として、受信した発注書レポートを宛先データベースにマッピングする場合を考えます。このようなマッピングには、繰り返される可能性のある2つの異なる要素構造が含まれているため、それぞれにForeach 関係が必要です:(1) 1つのレポートに複数の個別注文が含まれている場合があり、(2) 1つの個別注文に複数の明細項目が含まれている場合があります。
インプット例
ソーステンプレートの構造は次のようになります:
<OrderReport>
<WebOrder>
<CustomerName>John Doe</CustomerName>
<PurchaseDate>12/21/22</PurchaseDate>
<Line>
<ItemName>Hammer</ItemName>
<ItemCost>1500</ItemCost>
<ItemQuantity>1</ItemQuantity>
<ItemDescription>Standard claw hammer</ItemDescription>
</Line>
<Line>
<ItemName>Nail</ItemName>
<ItemCost>10</ItemCost>
<ItemQuantity>20</ItemQuantity>
<ItemDescription>Ten penny nails</ItemDescription>
</Line>
<Subtotal>1700</Subtotal>
<TaxPercent>4</TaxPercent>
</WebOrder>
</OrderReport>
この例では、簡潔にするため WebOrder 要素は1つだけですが、同じ OrderReport に複数の WebOrder セクションが含まれている場合も、マッピングで処理する必要があります。
アウトプット例
このマッピングの出力は、データベース挿入のXML モデルと一致する必要があります。データベースの挿入のXML モデルは、データベースコネクタ(例:MySQL、SQLite、CData コネクタ)によって自動的に作成されます。Template Files from Database Connectors セクションでは、これらのXML モデルをXML Map コネクタのテンプレートファイルとして使用する方法について説明します。
適切なデータベース設計では、データを2つの別々のテーブル(注文用と明細項目用)に挿入することが推奨されます。このアプローチに適した入力マッピングを生成すると、次のようなテンプレート構造が得られます:
<Items>
<Order>
<FirstName></FirstName>
<LastName></LastName>
<Date></Date>
<OrderLine>
<Name></Name>
<Desc></Desc>
<Price></Price>
<Amount></Amount>
</OrderLine>
</Order>
</Items>
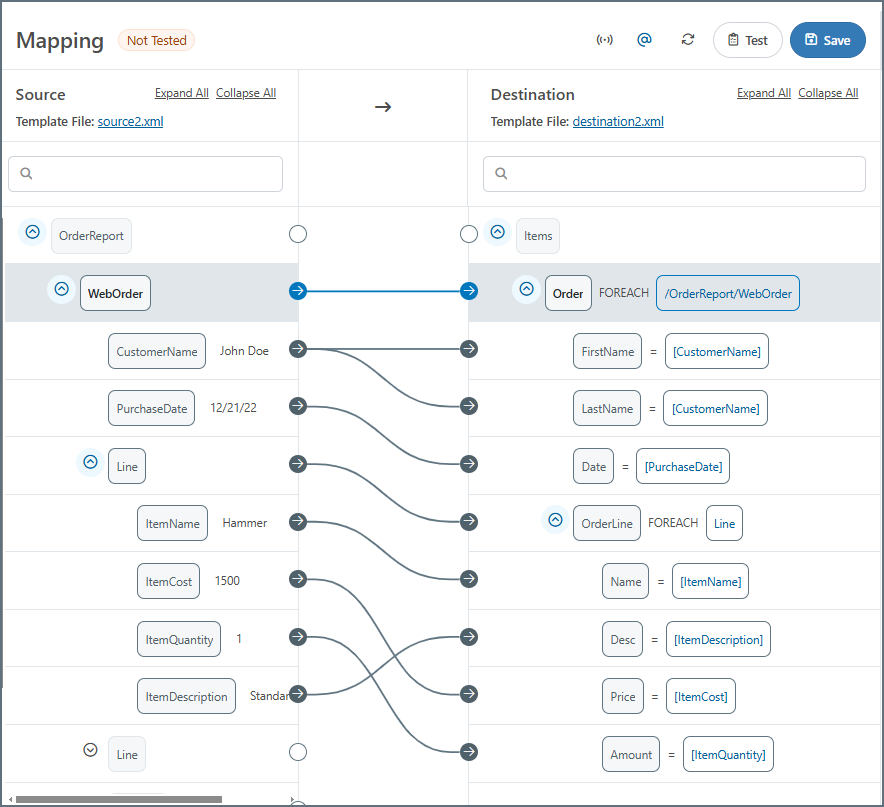
この例では、 Order 要素はOrders テーブルへの挿入を表し、 OrderLine 要素はLine Items テーブルへの挿入を表します。テンプレートは各テーブルを表す要素を1つだけ生成されますが、マッピング中に確立されるForeach 関係により、適切な数の挿入が作成されます。
Order の他の子( FirstName 、 LastName 、 Date )はOrders テーブルのカラムを表し、 OrderLine の子( SKU 、 Price など)はLine Items テーブルのカラムを表します。
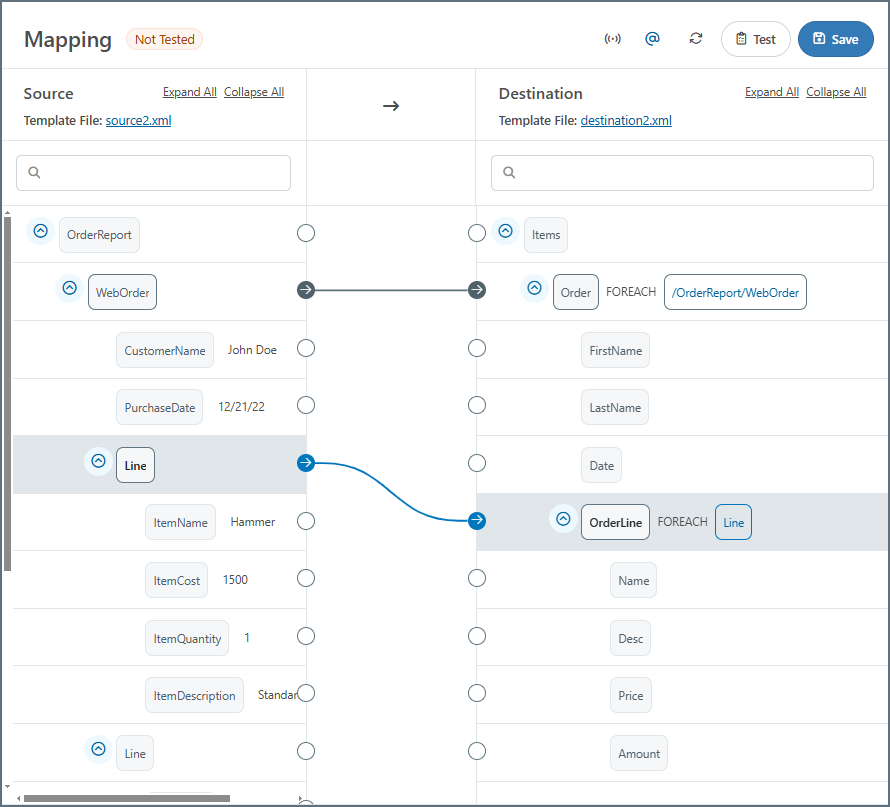
ループ関係の確立
ソースの WebOrder 要素はOrders テーブルへの新しい挿入となるため、宛先の Order 要素にドラッグします。同様に、ソースの Line 要素はLine Items テーブルへの新しい挿入となるため、宛先の OrderLine 要素にドラッグします。
これら2つのForeach 関係を確立すると、マッピングエディタは次のようになります:
ループ関係が確立され、宛先の不要な要素が削除されたら、リーフ要素をマッピングして宛先の値を埋めることができます:
不要な親ノード
Foreach 関係を確立する際は、マッピングされた要素のインスタンスがソースファイルと宛先ファイルに1つだけ存在すれば十分です。つまり、Foreach 関係は、出力要素の数を対応する入力要素の数と一致するように調整します。
この点を明確にするため、ループのマッピングの例で、ソースファイル(入力XML のテンプレート)に複数の customer 要素グループが存在する場合を考えてみます。customer (ソース)と customerInfo (宛先)の間に単一のForeach 関係を設定すると、 customerInfo 要素グループの数が、どの入力ファイルの customer 要素グループの数とも一致することが保証されます。このForeach 関係を確立するために必要な customer 要素は1つだけなので、他のすべての customer 要素はマッピングには無関係であり、無視または削除できます。
同様に、上の例の宛先ファイルに複数の customerInfo 要素がある場合は、1つを除いてすべて削除する必要があります。customer と customerInfo 間のForeach 関係により、XML 出力に適切な数の customerInfo 要素グループが表示されます。
マッピングのテスト
マッピングをテストボタンを使用して、マッピングが期待どおりに機能することを確認します。テストでは、以下に示すように、ソースファイルの値が宛先要素に入力されます:
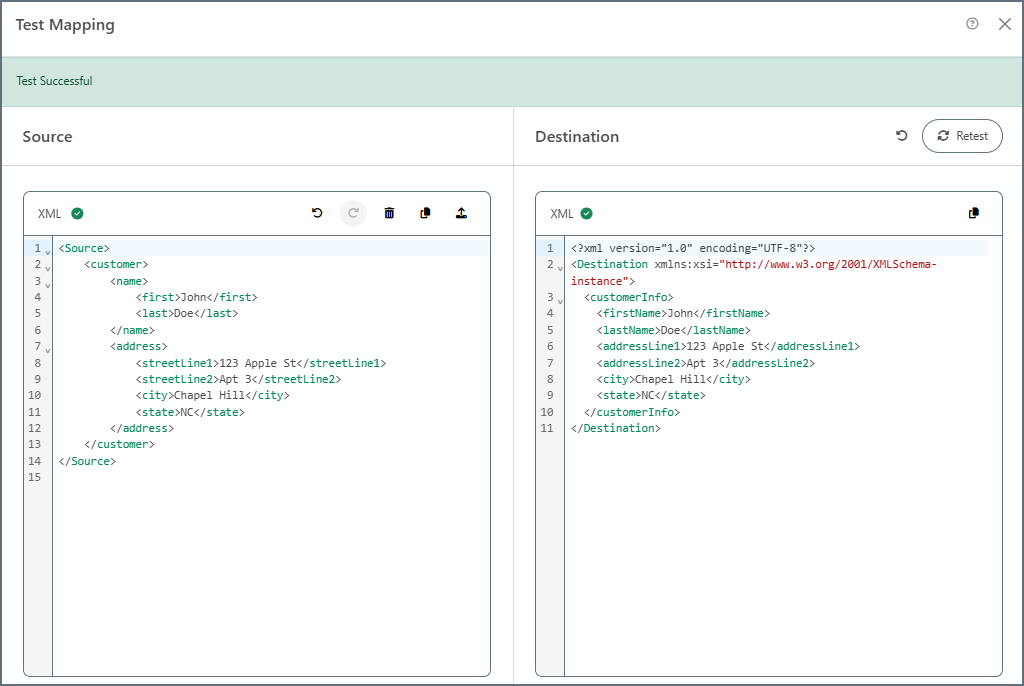
テストが失敗した場合、宛先ペインに失敗の理由が表示されます。
マッピングのベストプラクティス
Foreach ループは、宛先ファイル内の繰り返し要素をマッピングするための強力なツールです。ただし、適切な機能を確保し、パフォーマンスの問題を回避するために、以下のベストプラクティスに従うことが重要です:
-
大きなXML ファイルを使用する場合、ファイル全体をForeach ループとしてマッピングしないでください。このマッピング方式では、ファイル全体をメモリに読み込むようマッピングエンジンに指示するため、処理時間が長くなる可能性があります。
-
代わりに、ソースドキュメント全体の構造を念頭に置き、繰り返しがあることがわかっている要素(上記ループ関係の確立で説明)に対してのみForeach 関係を作成することがベストプラクティスです。このプラクティスにより、Foreach 関係に関連するパフォーマンスへの影響を最小限に抑えることができます。