CSV Connector
Version 23.4.8839
Version 23.4.8839
CSV Connector
The CSV connector converts comma-separated values (CSV) files into XML and generates CSV files from XML.
Overview
XML is the primary format that CData Arc uses to manipulate data within a flow. Therefore, it is useful to convert CSV files into XML as a staging step for further processing in the flow, or to convert XML to a CSV file after the XML has been manipulated. Both of these operations can be accomplished with the CSV connector.
For details on converting CSV into XML, see the Converting CSV to XML section. For details on converting XML into CSV, see the Converting XML to CSV section.
Connector Configuration
This section contains all of the configurable connector properties.
Settings Tab
Configuration
Settings related to the connector Id and description.
- Connector Id The static, unique identifier for the connector.
- Connector Type Displays the connector name and a description of what it does.
- Connector Description An optional field to provide a free-form description of the connector and its role in the flow.
Connector Settings
Settings related to the core operation of the connector.
- Column headers present Whether the CSV file contains a row of headers providing names or context to the values in the file.
- Record Name The name of elements representing a row in the CSV file when converting to XML. You can use the following macros:
%ConnectorID%, %FilenameNoExt%, %RegexFilename:%, and %Header:%.
See Converting CSV to XML for more details.
Other Settings
Settings not included in the previous categories.
- Local File Scheme A scheme for assigning filenames to messages that are output by the connector. You can use macros in your filenames dynamically to include information such as identifiers and timestamps. For more information, see Macros.
- Processing Delay The amount of time (in seconds) by which the processing of files placed in the Input folder is delayed. This is a legacy setting. Best practice is to use a File connector to manage local file systems instead of this setting.
Message
- Save to Sent Folder Check this to copy files processed by the connector to the Sent folder for the connector.
- Sent Folder Scheme Instructs the connector to group messages in the Sent folder according to the selected interval. For example, the Weekly option instructs the connector to create a new subfolder each week and store all messages for the week in that folder. The blank setting tells the connector to save all messages directly in the Sent folder. For connectors that process many messages, using subfolders helps keep messsages organized and improves performance.
Logging
- Log Level The verbosity of logs generated by the connector. When you request support, set this to Debug.
- Log Subfolder Scheme Instructs the connector to group files in the Logs folder according to the selected interval. For example, the Weekly option instructs the connector to create a new subfolder each week and store all logs for the week in that folder. The blank setting tells the connector to save all logs directly in the Logs folder. For connectors that process many transactions, using subfolders helps keep logs organized and improves performance.
- Log Messages Check this to have the log entry for a processed file include a copy of the file itself. If you disable this, you might not be able to download a copy of the file from the Input or Output tabs.
Miscellaneous
Miscellaneous settings are for specific use cases.
- Other Settings Enables you to configure hidden connector settings in a semicolon-separated list (for example,
setting1=value1;setting2=value2). Normal connector use cases and functionality should not require the use of these settings.
Automation Tab
Automation Settings
Settings related to the automatic processing of files by the connector.
- Send Whether messages arriving at the connector are automatically processed.
Performance
Settings related to the allocation of resources to the connector.
- Max Workers The maximum number of worker threads consumed from the threadpool to process files on this connector. If set, this overrides the default setting on the Settings > Automation page.
- Max Files The maximum number of files sent by each thread assigned to the connector. If set, this overrides the default setting on the Settings > Automation page.
Alerts Tab
Settings related to configuring alerts and Service Level Agreements (SLAs).
Connector Email Settings
Before you can execute SLAs, you need to set up email alerts for notifications. Clicking Configure Alerts opens a new browser window to the Settings page where you can set up system-wide alerts. See Alerts for more information.
Service Level Agreement (SLA) Settings
SLAs enable you to configure the volume you expect connectors in your flow to send or receive, and to set the time frame in which you expect that volume to be met. CData Arc sends emails to warn the user when an SLA is not met, and marks the SLA as At Risk, which means that if the SLA is not met soon, it will be marked as Violated. This gives the user an opportunity to step in and determine the reasons the SLA is not being met, and to take appropriate actions. If the SLA is still not met at the end of the at-risk time period, the SLA is marked as violated, and the user is notified again.
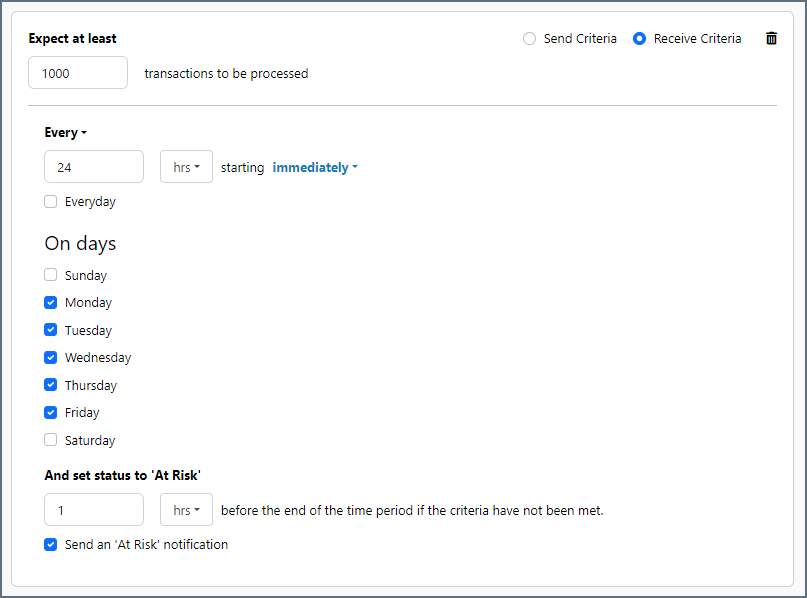
To define an SLA, click Add Expected Volume Criteria.
- If your connector has separate send and receive actions, use the radio buttons to specify which direction the SLA pertains to.
- Set Expect at least to the minimum number of transactions (the volume) you expect to be processed, then use the Every fields to specify the time frame.
- By default, the SLA is in effect every day. To change that, uncheck Everyday then check the boxes for the days of the week you want.
- Use And set status to ‘At Risk’ to indicate when the SLA should be marked as at risk.
- By default, notifications are not sent until an SLA is in violation. To change that, check Send an ‘At Risk’ notification.
The following example shows an SLA configured for a connector that expects to receive 1000 files every day Monday-Friday. An at-risk notification is sent 1 hour before the end of the time period if the 1000 files have not been received.
Converting CSV to XML
When a CSV file is transformed into XML, the resulting XML has the following structure:
<Items>
<Record>
<field_0></field_0>
<field_1></field_1>
<field_2></field_2>
</Record>
</Items>
Each row (record) in the original file becomes a child of the root element Items. The name of all record elements is determined by the Record Name option set in Connector Settings. Each record element then has child elements corresponding to the values in each row of the input file.
Some CSV files include a line of header information that provides context to the values in the file. When the First line is header information setting is enabled, this header line is parsed, and the parsed headers are used as the element names for the value elements (the children of the record elements). Otherwise, the value elements are given generic names such as field_0, field_1, and so on.
Converting XML to CSV
To convert XML to a CSV file, the input XML must have a ‘flat’ structure. This means that, disregarding the Items root element, the depth of the XML structure is two. For example:
<Items>
<film>
<title>Citizen Kane</title>
<year>1941</year>
<runtime>119</runtime>
</film>
<film>
<title>Sharknado</title>
<year>2013</year>
<runtime>86</runtime>
</film>
</Items>
The XML is interpreted as follows:
- Children of the root element are treated as records (rows) in the resulting file
- Children of each record element are treated as the values in each row
If the First line is header information option is enabled, a header row is inserted into the resulting CSV file with the names of each value element to provide context to the values. In the example above, this header row would consist of title, year, and runtime.
CSV Transformation: Using the XML Map Connector
Many data transformation flows use the CSV connector in conjunction with the XML Map Connector.
Often, data enters an Arc flow in CSV format and should exit the flow in some other format (for example, a database insert, an EDI file, or an insert into a CRM or ERP data source), or vice versa. Arc uses a single streamlined approach to these data transformation requirements:
- Model the input format as XML
- Model the output format as XML
- Use the XML Map connector to map between the input XML and the output XML
Therefore, the CSV connector is commonly adjacent to an XML Map connector in the flow:
- When CSV files are the input to the flow, the CSV connector converts a CSV file to XML and then passes that XML off to the XML Map connector to be transformed
- When CSV files are the output from the flow, the CSV connector receives XML from the XML Map connector and converts it into a CSV file
The CSV connector includes an Upload Test File feature to simplify the process of mapping the XML that represents a CSV file.
Upload Test File
An XML Map connector requires a sample XML structure for both the mapping input/source and the mapping output/destination. The Upload Test File feature makes it easy to use the CSV connector to generate a Source or Destination XML template.
Navigate to the Input tab of the CSV connector, click the More button, and choose Upload Test File. Browse to a local CSV file to instruct the connector to generate an internal XML model of this sample file.
Then, when an XML Map connector is connected to this CSV connector in the flow (and the flow changes are saved), the XML Map connector detects this internal XML model and uses it as a source file (if the CSV connector is before the XML Map connector in the flow) or a destination file (if the CSV connector is after the XML Map connector in the flow).
Note: The structure of this test file should be representative of future files. In other words, all of the CSV files processed by the CSV connector (and then the XML Map connector) should have the same columns as your test file. You might need to set up multiple CSV connectors and multiple XML Map connectors to handle distinct CSV structures.
Macros
Using macros in file naming strategies can enhance organizational efficiency and contextual understanding of data. By incorporating macros into filenames, you can dynamically include relevant information such as identifiers, timestamps, and header information, providing valuable context to each file. This helps ensure that filenames reflect details important to your organization.
CData Arc supports these macros, which all use the following syntax: %Macro%.
| Macro | Description |
|---|---|
| ConnectorID | Evaluates to the ConnectorID of the connector. |
| Ext | Evaluates to the file extension of the file currently being processed by the connector. |
| Filename | Evaluates to the filename (extension included) of the file currently being processed by the connector. |
| FilenameNoExt | Evaluates to the filename (without the extension) of the file currently being processed by the connector. |
| MessageId | Evaluates to the MessageId of the message being output by the connector. |
| RegexFilename:pattern | Applies a RegEx pattern to the filename of the file currently being processed by the connector. |
| Header:headername | Evaluates to the value of a targeted header (headername) on the current message being processed by the connector. |
| LongDate | Evaluates to the current datetime of the system in long-handed format (for example, Wednesday, January 24, 2024). |
| ShortDate | Evaluates to the current datetime of the system in a yyyy-MM-dd format (for example, 2024-01-24). |
| DateFormat:format | Evaluates to the current datetime of the system in the specified format (format). See Sample Date Formats for the available datetime formats |
| Vault:vaultitem | Evaluates to the value of the specified vault item. |
Examples
Some macros, such as %Ext% and %ShortDate%, do not require an argument, but others do. All macros that take an argument use the following syntax: %Macro:argument%
Here are some examples of the macros that take an argument:
- %Header:headername%: Where
headernameis the name of a header on a message. - %Header:mycustomheader% resolves to the value of the
mycustomheaderheader set on the input message. - %Header:ponum% resolves to the value of the
ponumheader set on the input message. - %RegexFilename:pattern%: Where
patternis a regex pattern. For example,%RegexFilename:^([\w][A-Za-z]+)%matches and resolves to the first word in the filename and is case insensitive (test_file.xmlresolves totest). - %Vault:vaultitem%: Where
vaultitemis the name of an item in the vault. For example,%Vault:companyname%resolves to the value of thecompanynameitem stored in the vault. - %DateFormat:format%: Where
formatis an accepted date format (see Sample Date Formats for details). For example,%DateFormat:yyyy-MM-dd-HH-mm-ss-fff%resolves to the date and timestamp on the file.
You can also create more sophisticated macros, as shown in the following examples:
- Combining multiple macros in one filename:
%DateFormat:yyyy-MM-dd-HH-mm-ss-fff%%EXT% - Including text outside of the macro:
MyFile_%DateFormat:yyyy-MM-dd-HH-mm-ss-fff% - Including text within the macro:
%DateFormat:'DateProcessed-'yyyy-MM-dd_'TimeProcessed-'HH-mm-ss%
CSV Operations
In addition to the Operations provided with Arc, connectors can provide operations that extend functionality into ArcScript.
These connector operations can be called just like any other ArcScript operation, except for two details:
- They must be called through the
connector.rscendpoint. - They must include an auth token.
For example, calling a connector operation using both of these rules might look something like this:
<arc:set attr="in.myInput" value="myvalue" />
<arc:call op="connector.rsc/opName" authtoken="admin:1j9P8v8b9K0x6g5R5t7k" in="in" out="out">
<!-- handle output from the op here -->
</arc:call>
Operations specific to the functionality of the CSV connector are listed below.
csvListRecords
Loops over every record in a specified CSV file or string. See Special Formatters for more details.
Required Parameters
- file: The path to the CSV file.
Optional Parameters
- data: If the CSV data exists as a string rather than stored in a CSV file, use this parameter instead of file.
- columns: The comma-separated list of columns to include in the output (if unspecified, all columns are included).
- requireheader: By default, the first row of data is interpreted as column headers; pass false to this parameter to use generic column names (for example, c1, c2, c3).
Output
Any script in a csvListRecords operation executes multiple times: once for each record/row in the input CSV file/data. Within the operation, individual CSV values are accessible using the csv formatter. This formatter takes a column name as a parameter, and outputs the value in that column for the current record.
For example, imagine the CSV input data contains a set of items purchased in an order, and the name of the item is held in the ItemName column. The following script generates XML containing each ItemName value in an Item element:
<ItemList>
<arc:call op="csvListRecords?file=myFile.csv">
<Item>[csv('ItemName')]</Item>
</arc:call>
</ItemList>