Apache Kafka Connector Setup
Version 23.4.8839
Version 23.4.8839
Apache Kafka Connector Setup
The Apache Kafka connector allows you to integrate Apache Kafka into your data flow by pushing or pulling data from Apache Kafka. Follow the steps below to connect CData Arc to Apache Kafka.
Establish a Connection
To allow Arc to use data from Apache Kafka, you must first establish a connection to Apache Kafka. There are two ways to establish this connection:
- Add a Apache Kafka connector to your flow. Then, in the Settings tab, click Create next to the Connection drop-down list.
- Open the Arc Settings page, then open the Connections tab. Click Add, select Apache Kafka, and click Next.
Notes:
- The login process is only required the first time the connection is created.
- Connections to Apache Kafka can be re-used across multiple Apache Kafka connectors.
Enter Connection Settings
After opening a new connection dialogue, follow these steps:
-
Provide the requested information:
- Name — The static name of the connection.
- Type — This is always set to Apache Kafka.
- Auth Scheme — The authorization scheme to use for the connection. Options are Auto, None, Plain, Scram, and Kerberos.
- User — (All schemes except None) The Apache Kafka username to use for logging in.
- Password — (All schemes except None) The password for the user entered above.
- Bootstrap Servers — The host/port pair to use for establishing the initial connection to Apache Kafka. If you are connecting to Confluent Cloud, you can find this on the Cluster settings.
-
Optionally, click Advanced to open the drop-down menu of advanced connection settings. In most cases, you should not need these.
-
Click Test Connection to ensure that Arc can connect to Apache Kafka with the provided information. If an error occurs, check all fields and try again.
-
Click Add Connection to finalize the connection.
-
In the Connection drop-down list of the connector configuration pane, select the newly-created connection.
-
In the Topic field, enter the Apache Kafka topic that you want to target.
-
Click Save Changes.
Select an Action
After establishing a connection to Apache Kafka, you must choose the action that the Apache Kafka connector should perform. The table below outlines each action and where it belongs in an CData Arc flow:
| Action | Description | Position in Flow |
|---|---|---|
| Produce | Accepts input data from a file or another connector and sends it to Apache Kafka. | End |
| Consume | Checks the queue for messages and sends any data that it gets down the flow through the Output path. | Middle |
Produce
The Produce action sends input data to Apache Kafka. This data can come from other connectors or from files that you manually upload to the Input tab of the Apache Kafka connector. The Apache Kafka connector sends the input data to the topic you entered in the Topic field of the Configuration section.
Consume
The Consume action checks for messages in the Apache Kafka queue for the topic you entered in the Topic field of the Configuration section. You must set the following fields for this action:
- Consumer Group ID: Specifies which group the consumers created by the connector should belong to.
- Read Duration: The length of time (in seconds) that the connector waits for messages to arrive. The connector waits the full duration, regardless of the number of messages received.
Data processed through the Consume connector goes to the Output tab and travels down to the next steps of the Arc flow.
Additional Connection Configuration
Automation Tab
Automation Settings
Settings related to the automatic processing of files by the connector.
- Send Whether files arriving at the connector are automatically sent.
- Retry Interval The number of minutes before a failed send is retried.
- Max Attempts The maximum number of times the connector processes the file. Success is measured based on a successful server acknowledgement. If you set this to 0, the connector retries the file indefinitely.
- Receive Whether the connector should automatically query the data source.
- Receive Interval The interval between automatic query attempts.
- Minutes Past the Hour The minutes offset for an hourly schedule. Only applicable when the interval setting above is set to Hourly. For example, if this value is set to 5, the automation service downloads at 1:05, 2:05, 3:05, etc.
- Time The time of day that the attempt should occur. Only applicable when the interval setting above is set to Daily, Weekly, or Monthly.
- Day The day on which the attempt should occur. Only applicable when the interval setting above is set to Weekly or Monthly.
- Minutes The number of minutes to wait before attempting the download. Only applicable when the interval setting above is set to Minute.
- Cron Expression A five-position string representing a cron expression that determines when the attempt should occur. Only applicable when the interval setting above is set to Advanced.
Performance
Settings related to the allocation of resources to the connector.
- Max Workers The maximum number of worker threads consumed from the threadpool to process files on this connector. If set, this overrides the default setting on the Settings > Automation page.
- Max Files The maximum number of files sent by each thread assigned to the connector. If set, this overrides the default setting on the Settings > Automation page.
Alerts Tab
Settings related to configuring alerts and Service Level Agreements (SLAs).
Connector Email Settings
Before you can execute SLAs, you need to set up email alerts for notifications. Clicking Configure Alerts opens a new browser window to the Settings page where you can set up system-wide alerts. See Alerts for more information.
Service Level Agreement (SLA) Settings
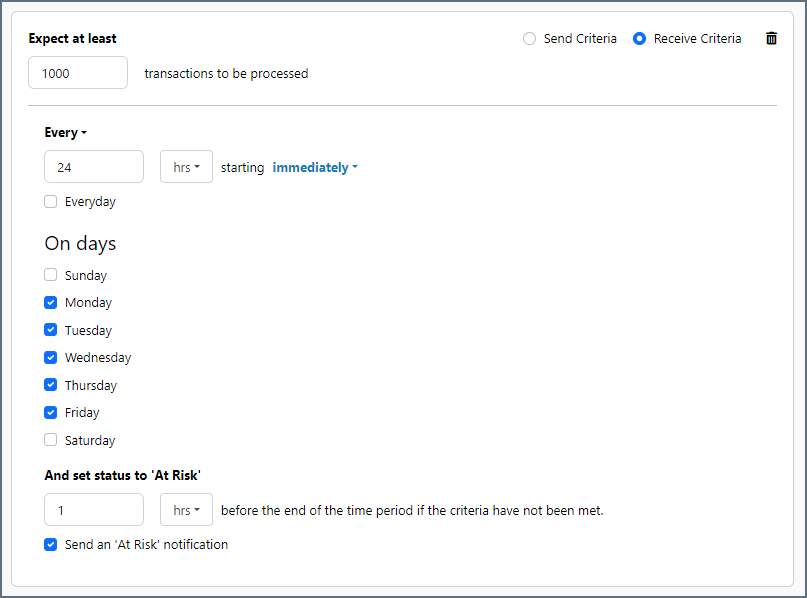
SLAs enable you to configure the volume you expect connectors in your flow to send or receive, and to set the time frame in which you expect that volume to be met. CData Arc sends emails to warn the user when an SLA is not met, and marks the SLA as At Risk, which means that if the SLA is not met soon, it will be marked as Violated. This gives the user an opportunity to step in and determine the reasons the SLA is not being met, and to take appropriate actions. If the SLA is still not met at the end of the at-risk time period, the SLA is marked as violated, and the user is notified again.
To define an SLA, click Add Expected Volume Criteria.
- If your connector has separate send and receive actions, use the radio buttons to specify which direction the SLA pertains to.
- Set Expect at least to the minimum number of transactions (the volume) you expect to be processed, then use the Every fields to specify the time frame.
- By default, the SLA is in effect every day. To change that, uncheck Everyday then check the boxes for the days of the week you want.
- Use And set status to ‘At Risk’ to indicate when the SLA should be marked as at risk.
- By default, notifications are not sent until an SLA is in violation. To change that, check Send an ‘At Risk’ notification.
The following example shows an SLA configured for a connector that expects to receive 1000 files every day Monday-Friday. An at-risk notification is sent 1 hour before the end of the time period if the 1000 files have not been received.
Advanced Tab
Message
- Save to Sent Folder Check this to copy files processed by the connector to the Sent folder for the connector.
- Sent Folder Scheme Instructs the connector to group messages in the Sent folder according to the selected interval. For example, the Weekly option instructs the connector to create a new subfolder each week and store all messages for the week in that folder. The blank setting tells the connector to save all messages directly in the Sent folder. For connectors that process many messages, using subfolders helps keep messsages organized and improves performance.
Optional Connection Properties
- Other Driver Settings Hidden properties that are used only in specific use cases.
Logging
- Log Level The verbosity of logs generated by the connector. When you request support, set this to Debug.
- Log Subfolder Scheme Instructs the connector to group files in the Logs folder according to the selected interval. For example, the Weekly option instructs the connector to create a new subfolder each week and store all logs for the week in that folder. The blank setting tells the connector to save all logs directly in the Logs folder. For connectors that process many transactions, using subfolders helps keep logs organized and improves performance.
- Log Messages Check this to have the log entry for a processed file include a copy of the file itself. If you disable this, you might not be able to download a copy of the file from the Input or Output tabs.
Miscellaneous
Miscellaneous settings are for specific use cases.
- Other Settings Enables you to configure hidden connector settings in a semicolon-separated list (for example,
setting1=value1;setting2=value2). Normal connector use cases and functionality should not require the use of these settings.