アーキテクチャ
Version 24.3.9159
Version 24.3.9159
アーキテクチャ
CData Arc は、ビジネスプロセスを統合するメッセージ駆動型のプラットフォームです。アプリケーション、データベース、外部メッセージシステムが互いにやり取りできるコミュニケーションハブを提供します。
デザイン原則と実装
Arc のアーキテクチャは、一連のコアとなるデザイン原則に則って決定されています。このセクションでは、Arc のデザインの3つの側面に着目します:
- CData が重視する原則と価値
- Arc の高度な理解に必要なコアとなるコンセプト
- アーキテクチャ上の判断と、その判断がデザイン原則をどう反映しているか
原則およびコンセプトセクションは、技術的な知識を持ったユーザーと一般のユーザー、両方に向けたものになっています。残りの実装のセクションは、エンジニアにArc のアーキテクチャを活用する方法を理解してもらうためのものです。
コアとなる原則
Arc のデザインにおいて鍵となる原則は次のものです:
- 透明性
- シンプルさ
- モジュール性
- 使いやすさ
連携プラットフォームで上記のデザイン原則を実装する方法は、Arc のアーキテクチャ以外にも存在します。次に実装のアイデアと、それがどのようにデザイン原則を反映するかを説明します。
コンセプト
大枠では、Arc のソリューションは3つの要素から構成されます:
- フロー
- コネクタ
- メッセージ
フロー
Arc フローは、一連の自動化されたデータ処理タスクを実行する設定済みのワークフローです。フローは複数のコネクタによって構成され、1つのコネクタが処理したデータが自動的にフロー内の次のコネクタに渡されるよう接続されます。
UI では、フローはフローページのワークスペースに保持されます。コネクタを空のキャンバスに追加し、設定したり相互に接続することができます。次の画像は、AS2 とX12 の2つのコネクタから構成される簡単なフローを示します。
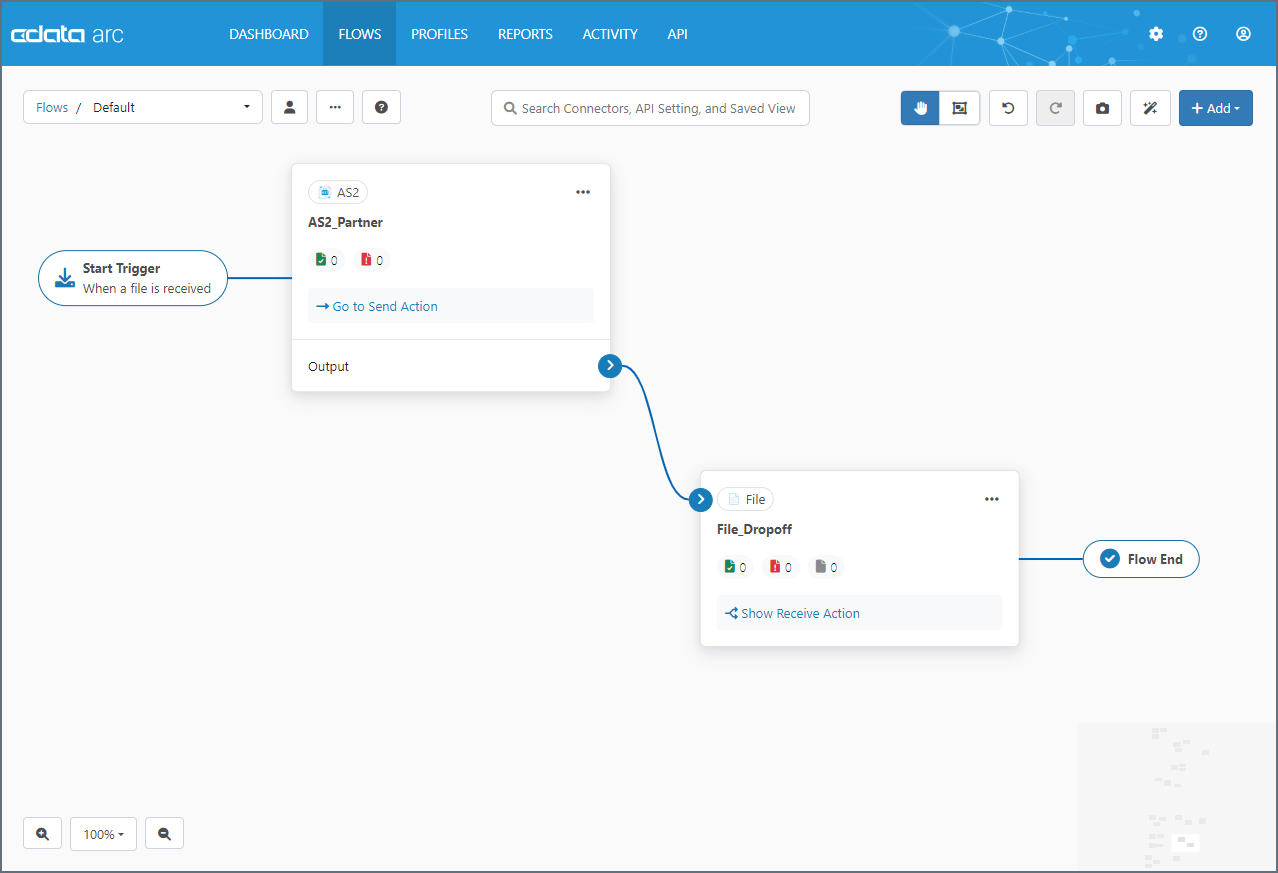
コネクタ間の青い矢印は、AS2 コネクタが受け取ったデータが自動的にX12 コネクタに渡されることを示します。コネクタの右側にある青い点を他のコネクタの左側にドラッグすると、この関係が構成されます。
フロー内の一連のコネクタはデータ処理の論理的な手順を構成するため、特定のビジネスタスクを達成できるようフローをデザインしてください。タスクとしては単なるファイルのダウンロードから、受信したビジネス文書に基づいて複数のバックエンドアプリケーションを同期することまで、さまざまな複雑度のものがあり得ます。
異なるタスクを達成するためにArc 内で複数のフローを設定することもできます。フローは、青いフローの矢印で明示的に接続されていなければ、互いに独立して動作します。
フローに関する詳しい情報は、専用のフローセクションを参照してください。
コネクタ
コネクタはフローの個別の部品で、アプリケーションデータおよびメッセージに影響します。各コネクタはメッセージに特定の操作を実行し、フロー内の次のコネクタ、または外部パーティ(例えば、FTP 同期先)に渡します。
操作は主に3つのカテゴリに分けられます:
- データの受信(転送したファイルやデータベースの出力など)
- データの処理および変換(フォーマット間でのデータの変換、新しい構造へのデータのマッピングなど)
- データの送信(ファイルの送信やアップロード、データベースへのデータの挿入など)
コネクタが上の操作を実行するときには、コネクタはトランザクションを処理していることになります。
フローページのワークスペースで、キャンバスにコネクタを追加すると、その構成設定パネルが開きます:
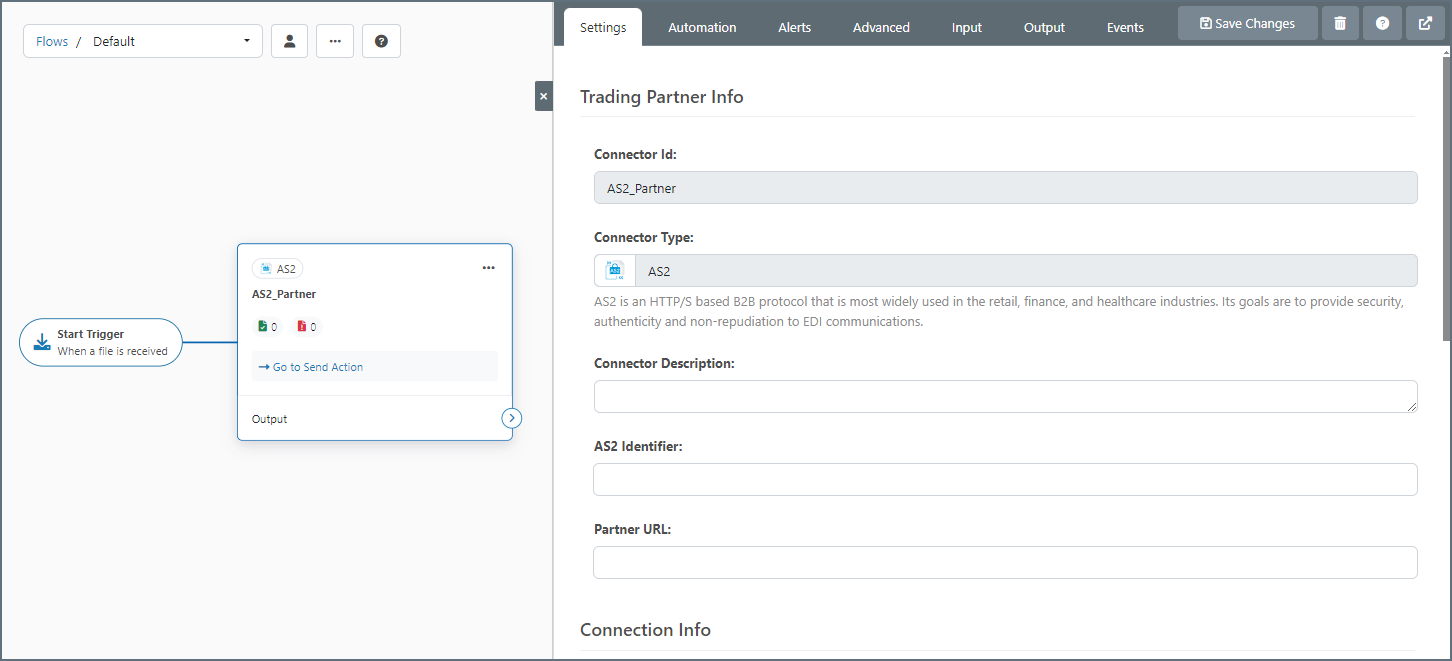
コネクタは、種類(例えば、AS2、SQL Server、XML、etc)に応じて異なる設定を持ちます。
AS2 やSFTP などの一部のコネクタは、外部パーティやサーバーからデータを受け取るか、外部パーティやサーバーにデータを送信するか、またはその両方が可能です。これらのコネクタは通常、データがアプリケーションに入力されたり出力される、フローの起点または終点にあります。
XML Map やX12 などの他のコネクタは、アプリケーション内でローカルにデータを処理します。これらのコネクタは、(外部データソース以外の)他のコネクタからのみデータの受信が可能で、(外部デスティネーション以外の)他のコネクタにのみデータを送信できるため、通常はフローの中間に組み込まれています。
コネクタについての詳細は、コネクタセクションを参照してください。
メッセージ
フロー内のコネクタ間でデータをやりとりする際には、メッセージとしてやりとりされます。メッセージは主に、ファイルペイロードデータ(Arc が処理しているデータ)とメタデータ(Arc がアプリケーションを通過するデータのフローを追跡するために使用する情報)で構成されています。
メッセージについては、メッセージの実装セクションでより詳細に説明されていますが、メッセージは標準RFC822(インターネットメッセージ)形式のファイルである、というのが概要となります。コネクタがデータをフロー内の他のコネクタに渡すと、渡されたコネクタはデータをファイルに書き込み、ファイルを次のコネクタに渡します。
フローの各ステップで、メッセージ(ファイル)はアプリケーション側に受信、またはダウンロードされ、ローカル(アプリケーション内)で変換されて、アプリケーションから送信、またはアップロードされます。これらの各操作をトランザクションと呼びます。
Arc は透明性の高いシステムです。ファイルシステムを参照したり、メッセージがあるフォルダから別のフォルダへコピーされるのを確認したり、またはメッセージ内容を通常のテキストエディタなどのツールを使って参照することで、プラットフォーム内の動作を理解できます。
基本的なメッセージ構造
基本的なメッセージには、(1)ヘッダーとしての名前と値のペアのセット、(2)メッセージのペイロード、の2つの要素があります。このメッセージ形式は、合わせて.eml ファイルで保存され、標準的なテキストエディタやE メールクライアントで開くことができます。
メッセージヘッダー
メッセージヘッダーは、Arc がアプリケーションを通過するデータの進行状況を追跡するのに役立ちます。ヘッダーには、一意のMessageId(ファイル名が変更されても、Arc がメッセージのライフサイクルを完全に把握するのに役立ちます)、コネクタがメッセージを処理した時のタイムスタンプ、処理中に発生した可能性のあるエラー、その他のメタデータが含まれます。
ヘッダーは、メッセージの先頭にある headerName: headerValue 構文で、改行で区切られて表示されます。メッセージにカーソルを合わせて詳細を表示をクリックすると、関連するヘッダーが表示され、メッセージファイルの内容をダウンロードできます。
メッセージは、Arc がフロー内で認識するのに有用なその他の値にも使用されます。例えば、リモートFTP サーバーのサブフォルダからファイルをダウンロードする際、Arc は、このフォルダパスをローカルシステムで再作成する必要がある場合に備えて、ヘッダーを使用してメッセージへのフォルダパスを追跡します。
メッセージペイロード
メッセージペイロードは、アプリケーションによって処理される実際のファイルデータです。これは、リモートソースから受信 / ダウンロードされるデータで、変換コネクタなどで操作されます。メッセージヘッダーは主にArc がメッセージを追跡するために使用されますが、メッセージペイロードにはユーザーが主に関心を持つデータが含まれています。
メッセージペイロードは、メッセージヘッダーと2行の改行で区切られます。テキストエディタやE メールクライアントでArc のメッセージを開くと、メッセージペイロードがプレーンテキストで表示されます。
フロー内のメッセージ
Arc は、アプリケーションによって処理されたデータを追跡し理解するためにメッセージヘッダーを内部的に使用しますが、メッセージが調査されない限り、これらの詳細をユーザーに非表示にします。例えば、Arc は内部メッセージId を使用してメッセージを識別しますが、インプットタブやアウトプットタブ、そしてメッセージタブには公開ファイル名が表示されます。
メッセージのヘッダーを調べたい場合は、表示されているファイル名をクリックするとメッセージの詳細情報が表示されます。
メッセージヘッダーは、第1のコネクタがファイルを処理するとすぐにファイルに追加されます。メッセージヘッダーは、フローの最後(フローの最後のコネクタがメッセージを処理した後)にメッセージから取り除かれます。言い換えれば、メッセージヘッダーと.eml 形式は、ファイルデータがArc フローで処理されている間にのみ関連付けられます。
メッセージログ
メッセージがコネクタによって処理されると、Arc はログファイルを生成します。これらのログには、アクティビティページから、またはコネクタパネルでメッセージの上にカーソルを合わせて詳細を表示をクリックすることでアクセスできます。
バッチグループとバッチメッセージ
メッセージは複数のペイロードを含むことができ、その場合はバッチグループとみなされます。バッチグループ内の個々のペイロードはバッチメッセージとみなされます。
バッチグループ
バッチグループは、各MIME パートが個別のバッチメッセージであるMIME 形式のファイルです。バッチグループは、基本のメッセージで使用されるのと同じヘッダースキームを使用して、バッチに関するメタデータを保持します。これらのヘッダーは、バッチの個々の部分ではなく、バッチ全体の処理を追跡します。
バッチメッセージ
バッチグループ内の各バッチメッセージは、アプリケーションによって処理されるファイルペイロードデータを含むMIME パートです。各バッチメッセージには、MIME パート内のペイロード(バッチグループではない)に関連するメタデータが含まれます。したがって、バッチメッセージには複数のメタデータのセットがあります。バッチグループ全体を追跡するための1つのヘッダーセットと、バッチ内の個々のMIME パート(各バッチメッセージ)用の別のヘッダーセットです。
実装の概要
このセクションでは、先に定義したコアとなるコンセプト(メッセージ、コネクタ、およびフロー)の、Arc 上での実装に関する技術的な詳細と、この実装がどのようにCData のデザイン原則を満たすのかを説明します。
ファイルベースのアーキテクチャ
Arc はファイルシステム上のファイルにすべてのデータを保存します。そのため、アプリケーションに関わるすべてがディスク上に残ります:
- アプリケーションデータ(メッセージ)
- 設定データ(プロファイルとフロー)
- ログ、etc。
設定済みフロー内のコネクタは、1つのインプットフォルダからファイル(メッセージ)を読み込み、1つのアウトプットフォルダにファイル(メッセージ)を書き込みます。データが1つのコネクタから別のコネクタにデータを渡す際には、これらのメッセージファイルは最初のコネクタのアウトプットフォルダから、次のコネクタのインプットフォルダに移動されます。
Arc はこうしたファイルシステムベースの構造にWeb UI を提供し、フローの簡単な構築、設定を実現します。ただし次のセクションで説明されているような、アプリケーションで使用されているフォルダ構造やファイル関連の決まりを理解していれば、ファイルシステムを直接編集することでArc のフローを構成することもできます。Arc は階層的なフォルダ構造を使ってアプリケーションのファイルを整理します。これについては、フォルダ階層セクションで説明します。
メッセージの実装
Arc のメッセージはアプリケーションが処理した生データを含む、ディスク上のファイルです。メッセージは2つの部分に分けられます:
- ボディ—アプリケーションデータのペイロード
- ヘッダー—メッセージのメタデータ
ヘッダーとボディは、合わせてRFC2822 準拠の.eml 拡張子を持ったファイルに保存されます。ヘッダーはname: value ヘッダーを改行 文字で区切ったリストであり、ボディは2つの改行 文字でヘッダーと区別されます。
ボディ
データを受信すると、Arc はメッセージを生成して(新規メッセージをディスクに書き込んで)、受信中のデータをメッセージのボディに使用します。例えば、SFTP コネクタがリモートサーバーからファイルをダウンロードすると、リモートファイルの内容が新規メッセージのボディとなります。
データがアプリケーション内でローカルに処理される際には(例えば、EDI がXML に変換されたり、ファイルが新しい形式にマッピングされるなど)、操作を実行中のコネクタがインプットメッセージのボディを読み込み、メモリ内でデータを処理して、アウトプットメッセージのボディに結果を書き込みます。
アプリケーションがデータを送信する際には(例えば、リモートサーバーにファイルをアップロードしたり、ピアにファイルを送る、データベースに挿入するなど)、インプットメッセージのボディだけが送信されます。
ヘッダー
Arc は生データファイルに、ファイル処理の方法に関するメタデータを付加します。次は最も頻繁に出現するヘッダーの一部です:
- フロー内でファイルを識別する一意の永続する
MessageId - 処理中のファイルのタイムスタンプ
- ファイルを処理したコネクタの
ConnectorId - エラーで処理に失敗したファイルのインスタンス
本アプリケーションがメッセージヘッダーを編集、および上書きすることはありません。処理履歴がすべて保持されるよう、新規ヘッダーは常に既存のリストに追加されます。
バッチグループ
メッセージは、まとめてバッチ処理することで、パフォーマンスを向上させ、大きなメッセージのグループをより管理しやすくすることができます。複数のメッセージをバッチ処理したものをバッチグループと呼びます。バッチグループは、各MIME パートが個別のバッチメッセージであるMIME 形式のファイルです。バッチグループは、基本のメッセージで使用されるのと同じヘッダースキームを使用して、バッチに関するメタデータを保持します。これらのヘッダーは、バッチの個々の部分ではなく、バッチ全体の処理を追跡します。
バッチメッセージ
バッチグループ内の各バッチメッセージは、アプリケーションによって処理されるファイルペイロードデータを含むMIME パートです。各バッチメッセージには、MIME パート内のペイロード(バッチグループではない)に関連するメタデータが含まれます。したがって、バッチメッセージには複数のメタデータのセットがあります。バッチグループ全体を追跡するための1つのヘッダーセットと、バッチ内の個々のMIME パート(各バッチメッセージ)用の別のヘッダーセットです。
メッセージへのアクセスと閲覧
メッセージはディスク上のファイルなので、ユーザーや外部システムは現時点でArc パイプライン内にあるメッセージにアクセスし、閲覧することができます。メッセージ.eml ファイルがファイルシステムのどこにあるのかを知っておくだけで、外部アプリケーションからメッセージにアクセスできます。こうしたメッセージファイルの正確な場所は、フォルダ階層セクションに記載されています。
メッセージは、Arc のWeb UI およびArc のREST API からも利用可能です。メッセージは、メッセージを処理したすべてのコネクタのインプットタブやアウトプットタブ、またはアクティビティページに表示されます。これらのインターフェースのいずれかで詳細を表示をクリックすると、メッセージ情報ページが表示されます:
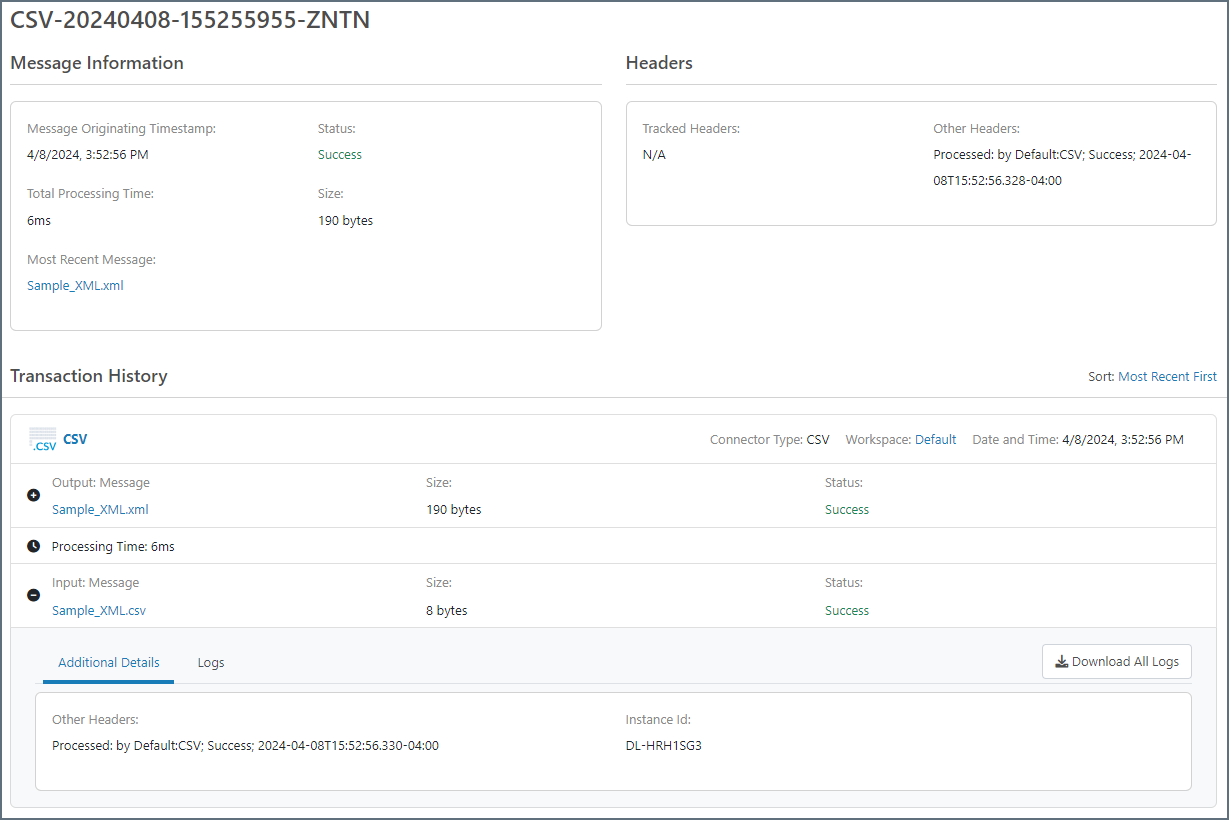
このパネルに表示された値はメッセージヘッダーです。メッセージのボディにはダウンロードボタンをクリックすることでアクセスできます。メッセージに関連するログは(メッセージログセクションで説明されているように)、ログをダウンロードボタンでダウンロードできます。
メッセージトラッキングとログ
メッセージには、メッセージの一意の識別子として機能するMessageId ヘッダーが含まれます。このMessageId は、ファイル自体の名前が変更されたとしても、フロー内では変化しません。そのため、フロー内でのすべてのファイルの状態はMessageId を参照することで追跡できます。ユーザーはこの値を使って、特定のトランザクションに関連したログデータを見つけることができます。
Arc はログデータを次の2つのフォーマットで保存します:
- アプリケーションデータベース。
- ディスク上のVerbose ログファイル。
これら2つのフォーマットとその関係については次で説明します。
アプリケーションデータベース
アプリケーションデータベース は、Arc がさまざまな方法で使用するリレーショナルデータベースです:
- 本アプリケーションが処理した各トランザクションのメタデータを保存
- どのトランザクションにも特定的でないアプリケーションの操作のログを保存
- 特定のコネクタの状態を保存(コネクタが確認応答または受信確認を待機している場合など)
Arc はデフォルトのSQLite(Windows / .NET)、またはDerby(Java)データベースを同梱していますが、SQL Server やPostgreSQL、MySQL などの外部データベースを使用することもできます。Arc はアプリケーションデータベース内のすべての関連するテーブルの作成と保守を行います。
アプリケーションデータベースには、メッセージの追跡やログの検索に使用されるテーブルがあります。これは、本アプリケーションが処理した各トランザクションのメタデータを保持し、メタデータには処理されたメッセージのMessageId が含まれます。UI のアクティビティページを使用して、メッセージログやトランザクションログを検索します。
トランザクションのメタデータ(タイムスタンプ、ConnectorId、ステータスなど)は、アクティビティページで検索できます。データベースのフットプリントを最小化するため、verbose ログデータはアクティビティページには含まれず、ディスク上のログファイルに保存されます。
Verbose ログファイル
Arc は、メッセージを処理するたびにMessageId と同名のログフォルダを生成します。このフォルダにはverbose ログファイルが含まれ、ログ内容はファイルを送信および受信(または送信か受信のどちらか)したコネクタの種類に依存します。例えば、AS2 コネクタはメッセージ自体を表示する.eml ファイルに加えて、MDN レシート、生のリクエストと応答、接続ログをログに記録します。
こうしたログファイルは、フロー内のメッセージを追跡するだけであれば不要です。アプリケーションデータベースに保存されたメタデータだけで、メッセージの追跡には十分です。ただし、デバッグの際などに特定のトランザクションの詳細がほしい場合は、メッセージのMessageId と処理したコネクタに基づいて、適切なファイルを見つける必要があります。
当然、ユーザーはMessageId が分かっていれば適切なログフォルダに手動で移動できます。しかし次で説明するように、こうしたverbose ログファイルを見つけるにはアプリケーションデータベースを使用する方が便利です。
アプリケーションデータベースとログファイルの関係
アプリケーションデータベースに保存されたメタデータには、特定のトランザクションに関連するログファイルを見つけるのに必要なすべての情報が含まれます。Arc のWeb UI およびREST API はこの関係を使って、すべてのトランザクションのログファイルに簡単にアクセスできるようにします。
アクティビティページには、すべてのトランザクションメタデータが含まれています。トランザクションエントリの上にカーソルを合わせて詳細を表示をクリックし、関連するログファイルにアクセスします。Arc はMessageId を使用して、ディスク上の適切なログファイルを検索しています。
同様に、コネクタの設定パネルのインプットタブとアウトプットタブを使えば、特定のコネクタが処理したすべてのトランザクションにアクセスできます。これらの項目は、トランザクションのverbose ログファイルを閲覧、ダウンロードできるように拡張することもできます。
アプリケーションデータベースは、トランザクションログファイルが保存されている適切なフォルダに手動で移動するのに役立ちます。ユーザーがトランザクションのファイル名を知っていても、内部のMessageId は知らない、ということは頻繁にあります。メッセージタブは検索できるので、特定のファイル名で検索すると、そのファイル名に紐付けられたトランザクションのMessageId が表示されます。フォルダ階層セクションは、MessageId とコネクタが分かった後で、ログフォルダの場所を見つける方法に関する情報を含みます。
メッセージ実装のデザイン判断
アプリケーションデータはユーザーと外部システムにとって透明であってほしいと考えており、そのためメッセージは不透明な内部データチャネル上ではなく、ファイルシステム上のデータファイルとしてやり取りする実装になっています。そのため、Arc は処理中にデータが隠ぺいされるブラックボックスではありません。Arc は実質的に、ファイルシステム上の特定のフォルダからファイルを取得したり、そこにファイルをドロップするようなどんなシステムにも組み込むことができます。
また、特別なツールやプログラムなしでメッセージにアクセスできる方が望ましいと考えています。メッセージはRFC2822 準拠のファイルに格納されるので、どんなテキストエディタでも簡単にファイルを開くことができます。ダブルクリックするとシステムのデフォルトE メールクライアントがメッセージを開いて内容を表示するよう、.eml 拡張子を使用しています。
メッセージとログが手軽に利用でき透明性を保つよう、トランザクションメタデータを検索可能なデータベースを提供しています。このデータベースはメッセージペイロードとverbose ログファイルへの直接アクセスに使用でき、しかもメモリをあまり使用しません。
コネクタの実装
コネクタは設定済みのフロー内で1つのステップとして表示されます。複雑なフローは、データ処理の論理的な手順を実行する任意のコネクタの集まりを繋ぐことで作成します。
コネクタは3種類の操作を実行できます:
- データを受信してアウトプットメッセージを書き込む(例えば、SFTP 経由でリモートファイルをダウンロード)
- インプットメッセージを読み込んでデータを外部パーティに送信(例えば、AS2 経由でファイルを送信)
- インプットメッセージを読み込んでローカルで処理し、アウトプットメッセージを書き込む(例えば、EDI ファイルをXML に変換)
多くのコネクタは最初の2つの操作(データのリモートエンドポイントへの送受信)、または最後の操作(データをローカルで変換)を実行できます。コネクタが実行するすべての操作は、トランザクションと呼ばれます。
すべてのコネクタは1つのインプットフォルダからインプットメッセージを読み込み、1つのアウトプットフォルダにアウトプットメッセージを書き込みます。コネクタがフロー内で接続されると、Arc は最初のコネクタのアウトプットフォルダからメッセージを次のコネクタのインプットフォルダに移動します。
コネクタファイルとフォルダ
すべてのコネクタインスタンスは、ConnectorId(フロー内の表示名)と同名のディスク上の1つのフォルダとして存在します。各コネクタフォルダには次が含まれます:
- port.cfg ファイルには設定が含まれます
- ‘Send’ サブフォルダ内の送信、または処理するメッセージ(インプットメッセージ)
- ‘Receive’ サブフォルダ内の受信したメッセージ(アウトプットメッセージ)
- コネクタが処理したメッセージのログファイル
- マップ、テンプレート、スクリプトといったコネクタに固有のファイル
このセクションではこうしたフォルダの内容が本アプリケーションでどのように機能するかを説明し、フォルダ階層セクションではコネクタフォルダとその中のサブフォルダ階層の正確な場所を説明します。
Port.cfg
各コネクタのport.cfg ファイルにはコネクタの動作を制御する設定が含まれます(コネクタUI の[設定]と[高度な設定]に表示される設定です)。ファイルはINI フォーマットであり、コネクタの設定はSettingName = SettingValue 構文で1行1設定としてリスト化されています。
port.cfg ファイルは 間接値 、つまり文字列リテラルの代わりに参照を使ったフィールドの設定をサポートします。この設定は、概念的にはアプリケーションの別のセクションで変数を設定して、その変数名をport.cfg ファイルで参照するのと同じです。間接値の設定に関する詳細は、データディレクトリセクションのsettings.json サブセクションを参照してください。
コネクタ設定をアプリケーションUI で変更するのと、port.cfg ファイルから設定を直接変更するのは、実質的には同じことです。
インプットメッセージ
‘Send’ フォルダはインプットメッセージ、つまりコネクタが処理するためにキューに入っているメッセージを保持します。
各クロックティック(デフォルトでは0.5秒)毎に、Arc はコネクタのSend フォルダをチェックしてワーカースレッドを利用可能なメッセージを持つすべてのコネクタに割り当てます。メッセージが処理されると、Arc はそのメッセージに処理試行時のタイムスタンプが付いたヘッダーを付加します。
Arc は、より古いファイルが最初に処理されるよう、インプットメッセージを最終変更時間に応じてソートします。Arc は各試行中にヘッダーを付加するので、エラーを起こすメッセージが複数回再試行することで、コネクタを無意味にブロックしてしまうことはありません。
各クロックティックでインプットメッセージを処理するには、コネクタ内で 送信 オートメーションを有効化しておく必要があります。
アウトプットマッピング
‘Receive’ フォルダはアウトプットメッセージ、つまりコネクタが受信、ダウンロード、または処理したメッセージを保持します。
コネクタによっては、インプットメッセージの処理を終えてすぐにアウトプットメッセージを書き込みます(例えば、データフォーマットを変換するコネクタなど)。ダウンロードするファイルをリモートサーバーにポーリングするSFTP コネクタ、受信するファイルを待機してリッスンするAS2 のようなその他のコネクタは、インプットメッセージを最初には読み込みません。
コネクタがフローで他のコネクタに接続されている場合、アウトプットメッセージはReceive フォルダに待機せず、次のコネクタのSend フォルダに渡されます。
ログファイル
コネクタが処理する各トランザクションは、一連のログファイルを生成します。トランザクションメタデータはログに追加され、verbose ログ情報はディスク上にファイルとして格納されます。ログファイルには常に.eml フォーマットのメッセージとコネクタ固有のログが含まれます。
デフォルトでは、ログファイルは次のフォルダ構造に従って整理されています:
├── Logs
├── Sent
├── MessageId_1
├── MessageId_2
├── Received
├── MessageId_3
├── MessageId_4
つまりログファイルはすべて、親の’Logs’ フォルダ内にある’Sent’ または’Received’ フォルダ内の、処理されたメッセージのMessageId と同名のフォルダに保存されます。
ログは、生成された時間に応じてログフォルダをまとめることでさらに整理できます。すべてのコネクタのログサブフォルダのスキームフィールドは、時間間隔(例えば、Weekly)に設定することでその間隔でログをまとめることができます(例えば、同じ週に生成されたすべてのログが同じサブフォルダに生成される、といったように)。これによって個々のサブフォルダのサイズを減らすことができ、ディスクI/O 性能の向上に繋がります。
MessageId を見つけるか本アプリケーションのUI からログをダウンロード機能を使うことで、メッセージタブを使って適切なログフォルダを検索する必要があるかもしれません。
送信済みファイル
verbose ログファイルに加えて、コネクタはすべての送信または処理されたメッセージを’Sent’ フォルダに保持しています。この’Sent’ フォルダはコネクタフォルダ直下のフォルダであり、’Logs’ フォルダ内の’Sent’ フォルダではありません。
‘Sent’ フォルダのファイルには送信に成功したメッセージのデータペイロードだけが含まれます。エラーが発生して処理に失敗したメッセージは’Sent’ フォルダには追加されません。
送信ファイルは生成された時間に基づいてさらに整理できます。Sent フォルダのスキームフィールドは時間間隔(例えば、Weekly)に設定して、その間隔でログをまとめることができます(例えば、同じ週に送信されたすべてのファイルが同じサブフォルダに保持される、といったように)。これによって個々のサブフォルダのサイズを減らすことができ、ディスクI/O 性能の向上に繋がります。
設定ファイルの追加
コネクタの種類によっては、コネクタフォルダに追加の設定ファイルが含まれます。追加のファイルには次が含まれます:
- map.json
- script.rsb
- テンプレートXML ファイル
これらのファイルはマッピング関係、カスタムスクリプトの動作、コネクタのインプットとアウトプット構造を保持します。これらのファイルをディスク上で編集することは、アプリケーションUI の関連するコネクタ設定を変更することと同じです。
コネクタ実装のデザイン判断
フローは完全なモジュラー型を志向しており、各コネクタが予測できる直感的な方法でわかりやすい機能を提供することを目指しています。Arc には任意のコネクタを組み合わせる機能があるため、シンプルなインターフェースでありながら複雑なタスクを実行することができます。洗練されたフローであっても、コネクタの連鎖を個々のステップに分解することで簡単に理解できます。
コネクタに関連するすべてのデータ(設定データ、アプリケーションデータ、ログデータ、etc.)に簡単にアクセスできるようにしたいと考えています。すべてのデータはコネクタ固有のフォルダにあるので、フォルダの場所さえ分かっていればそのフォルダにアクセスできます。設定データはメッセージデータと同様、透明性の高いINI フォーマットで格納されているため、シンプルなツールで閲覧・編集できます。
フォルダベースのアプローチでコネクタをデザインしているので、コネクタ間でどのようにデータがやり取りされるのかも容易に理解できます。メッセージファイルを移動する操作では、1つのコネクタのアウトプットを別のコネクタのインプットに移動します。Arc にはこうしたファイル移動の関係を自動で構成する組み込みツールが含まれますが、同じことはファイルシステムを直接操作することによっても可能です。
フローとワークスペースの実装
フローはファイルシステム上で、フローでのコネクタの位置と接続を含むflow.json ファイルとして表されます。ファイルの場所は以下のフォルダ階層セクションに記載されています。
フローでのコネクタの位置は純粋に見た目上のものに過ぎず、アプリケーションUI でフローを設定する場合にのみ使用されます。コネクタ間の接続はデータ処理に影響します。各コネクタがアウトプットメッセージを書き込むと、コネクタはアプリケーションエンジンにアウトプットメッセージを別のコネクタのインプットフォルダに渡すかどうかクエリします。本アプリケーションはflow.json ファイルを使って、(もしあれば)どのコネクタがファイルを渡されるか決定します。
同じフローキャンバスで複数のフローを設定でき、Arc のUI ではキャンバスをドラッグしてフロー間を移動できます。この操作は、例えばGoogle Maps の道路地図を使う場合のようなオンライン地図の操作と同様です。
ワークスペースはフロー間を論理的に分離します。各ワークスペースはコネクタの論理フローを設計するための新しいキャンバスとなります。Google Maps のアナロジーを拡張すると、ワークスペースは個別の’惑星’ のように機能します。
新しいフローを設定するために別のワークスペースを使うか同じワークスペースを使うかは、好みの問題です。
ファイルシステム上のワークスペース
新しい(デフォルトではない)ワークスペースを導入すると、Arc のフォルダ階層に新しい一連のフォルダが追加されます。workspaces ディレクトリには、デフォルトワークスペースで設定したすべてのコネクタのコネクタフォルダが含まれます。このworkspaces フォルダは次のセクションで説明するdata ディレクトリの兄弟です。
フローとワークスペースのデザイン判断
CData では、フロー内の個々のコネクタ間のシンプルでモジュラーな関係を保つ最良の方法は、フローを純粋に論理的な概念として扱うことだと考えています。データ処理の効率的な連鎖を決めるために必要なすべての情報は、すでにコネクタの実装に含まれています。
ワークスペースはコネクタをより根本的なレベルで分離する機能にしたいと考えています。個々のワークスペースは、ファイルシステムレベルの操作(例えば、権限やディレクトリリスティング)が簡単に特定のワークスペースのみに適用されないよう、コネクタを格納する個別のフォルダを与えられています。
フォルダ階層
Arc のすべてのリソースはファイルシステムから利用できるため、Arc の低レベルの実装を理解するにはアプリケーションのフォルダ構造を知っておく必要があります。このセクションでは、ディスク上でファイルやフォルダがどのように整理されているかを説明します。
この階層をよく理解するには、Arc のインストール先のディレクトリ構造を知っておくのがよいでしょう。次のテキストはそのフォルダ構造を示しており、以下のサブセクションで詳細を説明します。
├── Arc
├── data
├── AS2_Amazon
├── Archive
├── Logs
├── Pending
├── Receive
├── Send
├── Sent
├── Database_MySQL
├── Archive
├── Logs
├── Receive
├── Send
├── Sent
├── Templates
この階層は、フローがデフォルトのワークスペースだけで設定されていることを想定しています。追加のワークスペースについてはフローとワークスペースセクションで説明します。
ルートインストールディレクトリ
すべてのArc リソースはインストールディレクトリに含まれており、デフォルトでは以下の場所にあります:
- Windows:
C:\Program Files\CData\CData Arc - Linux/:
/opt/arc
Java 版のインストールについては、CData はzip ファイルを提供しており、それを任意のインストールディレクトリ(例えば、/opt/arc)に展開することができます。
Arc のJava 版はTomcat のような外部Java サーブレットにホストされているので、Arc のリソースは次の場所に配置されます:
~/cdata/arc
このパスでは、‘~’ はJava サーブレットをホストするユーザーのホームディレクトリになります。
前のセクションで説明したフォルダ階層では、ルートインストールディレクトリはツリーの最上部にあるArc フォルダです。
データディレクトリ
data ディレクトリには次が含まれます:
- (デフォルトワークスペースの)フローページで設定された各コネクタのサブフォルダ
- profile.cfg ファイル
- flow.json ファイル
- settings.json ファイル
- すべての証明書ファイル
Profile.cfg
profile.cfg ファイルには、設定済みローカルプロファイル(例えば、AS2 プロファイル)用のアプリケーション全体の設定が含まれます。このファイルはINI フォーマットであり、アプリケーションの設定はSettingName = SettingValue といった1行1設定の構文でリスト化されています。
profile.cfg の設定は、一般のアプリケーションセクション用のApplicationと、各プロファイル(例えば、AS2 プロファイルのAS2 セクションやローカルSFTP サーバー設定のSFTPServer セクション etc)用の専用セクションに分割されています。
アプリケーションUI のプロファイルページからアプリケーション設定を変更することと、profile.cfg ファイル内で直接設定を変更するのは実質的に同じことです。
Flow.json
flow.json ファイルには設定済みのフローの位置と各コネクタインスタンス間の関係が含まれます。フローページでコネクタを移動、再接続することとflow.json ファイルを直接変更するのは、実質的に同じことです。
Settings.json
settings.json ファイルには、アプリケーション内で値ではなく参照名を使用することで、別の箇所で参照できる設定の一覧が含まれます。これにより、セキュアな値(パスワードなど)をアプリケーションに表示しない方法で保存することができます。また、参照名を使用して、複数のインスタンスにデプロイされているフローの設定を一元化することもできます。
この統一された参照構文はWeb UI 上で「鍵」アイコンが付いた設定でサポートされており、それをクリックすることでsettings.json ファイルで定義された参照の一覧を閲覧できます。この機能に関して詳しくは、グローバル設定Vault を参照してください。
証明書
本アプリケーションで作成、またはアップロードされた証明書はすべてdata ディレクトリに保存されます。通常、証明書はパブリックとプライベートの対となっており、プライベートは.pfx、パブリックは.cer と異なる拡張子となっています。本アプリケーションにアップロードされた他のフォーマットの証明書はそのまま保存されます。
Arc はUI からドロップダウンメニューで証明書を設定する際に、data ディレクトリの証明書を一覧化します。data ディレクトリに直接証明書ファイルをドロップすることは、アプリケーションに証明書をアップロードすることと実質的に同じことです。
コネクタフォルダ
設定済みの各コネクタインスタンス用に、data ディレクトリに専用のフォルダが設置されています。これらのフォルダ名はフロー内の各コネクタのConnectorId の値(表示名)と同じです。上の画像では、’AS2_Amazon’ と’Database_MySQL’ がフロー内の2つの設定済みコネクタです。
コネクタフォルダの内容はコネクタファイルとフォルダセクションで説明されていますが、次の説明はコネクタフォルダ内のサブフォルダ構造の概要となります:
- Send(インプット)- コネクタが送信、または処理するメッセージはこのフォルダから読み込まれます。
- Receive(アウトプット)- コネクタが受信、または処理したメッセージはこのフォルダに書き込まれます。
- Sent - 処理に成功したメッセージのコピー(生データファイルのフォーマット)はこのフォルダに書き込まれます。
- Logs - コネクタが処理した各メッセージのverbose ログファイル。
- Sent - コネクタが送信したメッセージのログ。各メッセージは
MessageIdと同名のフォルダを持っています。 - Received - コネクタが受信したメッセージのログ。各メッセージは
MessageIdと同名のフォルダを持っています。 - Archive - 古いログファイルは圧縮されてこのフォルダに移動されます。
コネクタの種類に応じて、場合によっては他のサブフォルダを持つこともできます:
- Pending - 処理したが他パーティからの確認応答を待っているメッセージ。
- Templates - コネクタのインプット、アウトプットデータのXML 表示。
- Public - 本アプリケーション内でパブリックエンドポイントとしてパブリッシュされるはずのファイルはここに設置されます。
- Schemas - (EDI スキーマのような)特定のコネクタに固有のスキーマファイルはここに設置されます。
フォルダ階層のデザイン判断
Arc のデータは透明性を保ち簡単にアクセスできる状態にしておきたいと考えているため、本アプリケーションのファイルの場所は簡単に見つけることができるようになっています。シンプルな階層を持ったフォルダ構造にすることで、ユーザーや外部システムがArc のデータファイルを見つけやすくなっています。
Arc のUI はアプリケーションを設定、使用する上で便利なインターフェースとなっていますが、他のソリューションに完全に組み込むことができるようにもしたいと考えています。Arc のフォルダ構造を理解しさえすれば、他のソリューションはArc に関連するすべてのデータを参照することができます。
オートメーション
Arc のオートメーションサービスは各コネクタのインプットフォルダ内でファイルを処理します。オートメーションサービスは0.5秒毎の「クロックティック」で実行され、メッセージは各ティック毎にフローを1ステップ進みます。
Arc は、複数スレッドを各コネクタに割り当てることで並列処理をサポートし、各スレッドはコネクタ内で複数ファイルを処理することができます。割り当てられるワーカー数とワーカー毎に処理されるファイル数は、[プロファイル]のパフォーマンス設定と各コネクタの設定で決まります。
クロックティック
事前定義された間隔(デフォルトでは500ミリ秒)で、Arc はすべての設定済みコネクタのインプットフォルダをチェックし、新しいファイルが見つかればアプリケーションがワーカースレッドを割り当てて、コネクタ設定に応じてファイルを処理します。
本アプリケーションはどのコネクタのインプットが最初に一覧化されるか保証しません。1つのコネクタのインプットフォルダに複数のファイルが存在する場合、それらのファイルは最終更新時に応じて処理されます(最も古い変更時間のファイルが最初に処理されます)。
Arc がファイルを処理しようとする際には、処理時のタイムスタンプを付加したメッセージヘッダーを追加し、これによってファイルの最終更新時が変わります。ファイルが処理に失敗した場合(エラーが起きた場合)、インプットフォルダの他のファイルに対する優先順位は最低になります。これによって1つのファイルが何度もエラーとなって即座に中止され、コネクタの操作をブロックしてしまわないようにします。
並列処理
並列処理を有効化すると、Arc は1度のクロックティック内で複数ワーカースレッドを同じコネクタに分散できます。これらワーカーの数と動作は、設定ページの[高度な設定]タブ内の3つの設定で決まります(その内いくつかは個々のコネクタの[高度な設定]タブから上書きできます):
- ワーカープール
- コネクタ毎の最大ワーカー数
- コネクタ毎の最大ファイル数
スレッドはラウンドロビン方式でコネクタに割り当てられるので、これらの値を調整することで(全体でも特定のコネクタでも)スループットの問題を軽減したり、コネクタがシステムリソースを占有したりしないようにしたりできます。
ワーカープールは、アプリケーションがコネクタ全体に同時に割り当て可能な全体の最大スレッド数を決定します。スレッドが特定のコネクタ内で割り当てを完了したら、プールにリサイクルされます。ホストマシンのハードウェアリソースがこの設定の上限を決定します。
コネクタあたりの最大ワーカー数は、1つのコネクタに同時に割り当て可能な最大スレッド数を決定します。コネクタに割り当てられた各スレッドはそのコネクタのインプットフォルダ内のファイルを、フォルダが空になるまで(または、次で説明するようにコネクタあたりの最大ファイル数に達するまで)1つずつ処理します。この条件に達すると、コネクタに割り当てられたスレッドは処理の完了後ワーカープールにリサイクルされます。特定のコネクタについて、コネクタの[高度な設定]からこの設定を上書きできます。
コネクタあたりの最大ファイル数は、1回のクロックティック内で1つのコネクタ内で処理されるファイル数の上限を決定します。例えば、この設定を5に指定するとコネクタに割り当てられたスレッドは、(合計で)5ファイル処理したあとに、コネクタのインプットフォルダにファイルが残っていたとしてもワーカープールにリサイクルされます。特定のコネクタについて、コネクタの[高度な設定]からこの設定を上書きできます。これを0に設定すると、コネクタはスレッドが割り当てられた時点でコネクタに存在するすべてのファイルを処理しようと試みます。
パフォーマンスの最大化
コネクタあたりの最大ワーカー数とコネクタあたりの最大ファイル数の設定は、あるコネクタが他のものより多い、または少ないリソースを必要とする際に、それに応じて各コネクタ内で調整することでArc のパフォーマンスを最大化するのに役立ちます。
特定のコネクタのコネクタあたりの最大ワーカー数を増やすと、アプリケーションはそのコネクタのインプットファイルの処理により多くのシステムリソースを割り当てます。特定のコネクタがフローのスループットのボトルネックになっている際には有効です。しかし、スレッドはラウンドロビン方式で割り当てられるため、多くのコネクタでこの設定を増やすとアプリケーションがワーカープール内のスレッドを使い尽くしてしまう可能性があります。その場合、残ったコネクタにスレッドを割り当てるには、アプリケーションは他のスレッドが完了するまで待たなくてはなりません。
特定のコネクタのコネクタあたりの最大ワーカー数を下げることで、ファイルの処理中にコネクタがワーカープールを大きく圧迫するのを避けることができます。これは、ラウンドロビンでの割り当て中にアプリケーションがスレッドを使い尽くしてしまうのを避けるのに役立ちます。しかし、コネクタのインプットフォルダに大量のファイルがある場合、スレッド数が小さいとファイルの処理を完了してプールにリサイクルするまでに時間がかかることがあります(次に説明するように、コネクタあたりの最大ファイル数も調整されていない場合)。
特定のコネクタのコネクタあたりの最大ファイル数を上げる(または0に設定してすべてのファイルを処理する)ことで、複数回クロックティックしてもファイルがコネクタのインプットフォルダに残ったままにならないようにすることができます。これは、大容量コネクタのスループットを向上させるのに役立ちます。ただし、これによって大量の処理を行う必要があるコネクタのスループットを向上できますが、コネクタに割り当てられたスレッドが長時間ワーカープールにリサイクルされない(そのためスレッド不足を引き起こす)可能性も上昇します。
特定のコネクタのコネクタあたりの最大ファイル数を下げることで、そのコネクタに割り当てられたスレッドが時間どおりにプールにリサイクルされます。しかし、インプットフォルダ内のファイル数がティック毎の最大処理数を超えた場合、ファイルが1回のクロックティック内で処理されない可能性もあります。
パフォーマンスの最大化は特定の環境やユースケースに依存します。一般的には、大量のファイルを処理、送信する必要があるコネクタにはより多くのワーカーを割り当て、ワーカーがリサイクル前により多くのファイルを処理できるようにするとよいでしょう。スレッドプールを枯渇させないためには、他のコネクタに割り当てるワーカーと、ワーカーが処理するファイルを減らすのがよいでしょう。
受信オートメーション
Arc 内では上記のインプットファイルの自動処理は「送信」オートメーションと呼ばれます。Arc は「受信」オートメーションもサポートしており、これはコネクタがスケジュールされた間隔に従って、Arc のフローに自動でファイルを入れていく処理を記述します。
受信操作は次の2つのカテゴリに分けられます:
- リモートホストまたはサーバー(FTP、SFTP、S3、etc)からファイルをダウンロード
- バックエンドシステム(データベース、ERP システム、CRM、etc)からデータを取得してXML として書き込み
受信オートメーションは、コネクタが外部システムからファイルをダウンロード、またはデータを取得する試行の回数を決定するためのスケジュールされた間隔と常に紐付けられています。
各クロックティックで、オートメーションサービスは受信間隔を経過したコネクタがないか調べます。経過したコネクタはすぐに外部接続を確立し、コネクタの設定に従ってデータを取得します。
AS2 コネクタのような一部のコネクタは次に受信するデータを受動的にリッスンします。こうしたコネクタは能動的にデータを外部システムから取得することができないので、受信オートメーションをサポートしません。
このドキュメントの活用方法
Arc を使い始めるのに、基盤となるアーキテクチャを完全に理解する必要はありません。しかし、アプリケーションを構成するさまざまなレイヤーを理解していくことには重要なメリットがあります:
- Arc のアプローチが技術的な要件を満たすかどうかを評価する
- より深い理解と設定能力でアプリケーションを操作、設定する
- より大規模なデータ処理ソリューションにArc を組み込む方法を理解する
CData Arc の技術的特性の評価
Arc はメッセージ駆動型の統合フレームワークを軽量で実装します。その基盤を理解することで、エンジニアの方はArc のアプローチがビジネス上のニーズを満たすかどうか決定できます。
デザイン上の原則は本アプリケーションの成長と発展を形作るものですので、このドキュメントを読むことで、Arc のデザイン上の決定を導く原則が明確になることを願っています。アプリケーションデザインの裏にある”why” を理解することで、本アプリケーションがユーザーの皆さんにとって適切なものかどうか判断を下すのに役立つことと思います。
より高度なCData Arc の操作
Arc のWeb UI はアプリケーションを操作、設定する上で使いやすいインターフェースとなっています。その基盤となっているアーキテクチャをよりよく理解することで、ユーザーの皆さんは次の例のように、内部の仕組みにまで踏み込んだより高度な操作を実行できるでしょう:
- Arc のファイルやフォルダを直接変更する、スクリプトを使った管理プロセスを作成。
- Arc のファイルとフォルダをバージョン管理システムに追加してバックアップとスナップショットを保持。
- ユーザーアクセスをより細かく管理するために特定のフォルダに権限を設定。
さらにフローやコネクタ、そしてこうした機能のアプリケーションデータとの関係を理解することで、最適なワークフローを素早く簡単に設定することができます。CData では、ユーザーの皆さんが最小限の設定コストでArc の機能を利用できるよう努めています。
より大規模なソリューションにCData Arc を組み込む
Arc のフォルダ構造を理解すれば、Arc を別のデータ処理システムに組み込むのは簡単です。Arc は明確に定義された一連のディスク上のフォルダを介してシステムとやり取りするので、特定のフォルダに読み書きするアプリケーションはスムーズにArc にデータを渡したり、Arc からデータを取得することができます。
CData Arc に親しむ
最後に、弊社ではエンジニアの皆さんが、使用するシステムの基盤となっている仕組みを理解したいという共通の願望を持っていると考えています。上記のメリットがどれもお客様の特定の状況に当てはまらなかったとしても、このドキュメントを読むことでユーザーの皆さんが、Arc を使ったデータ連携ワークフローの構築に、より親しみをもって取り組んでいただけることを願います。