Reverse ETL
Version 24.3.9120
Version 24.3.9120
Reverse ETL
Traditional ETL (extract, transform, load) processes copy data from source systems to a centralized data store for analysis and reporting. Reverse ETL does the opposite–it moves data from a central repository back to your operational systems. Reverse ETL enables you to use results from data analytics to improve your operational processes, enhance customer experiences, or facilitate decision making.
The basic process for reverse ETL is as follows:
-
Extract data from a central data warehouse or data lake where that data has been aggregated and transformed for analytical purposes.
-
Transform the extracted data to make it suitable for consumption by your systems. Transformations can include reformatting, filtering, or enhancing your data.
-
Load the transformed data back into operational databases, applications, or other systems where you can use it for various purposes (for example, updating records or triggering workflows).
In CData Sync, reverse ETL capability is supported for the following sources:
Note: Source databases that you can use for reverse ETL capability are restricted to those for which the Delta Snapshot replication type is implemented (that is, source databases that accept the SQL EXCEPT statement).
In Sync, this capability is supported for these Salesforce and Microsoft Dynamics 365 destinations only. (Reverse ETL is the only replication type available for those destinations).
Understanding the Reverse ETL Process
Reverse ETL works by querying your data warehouse for changes and writing the results of that query to your destination. When you run the reverse ETL job for the first time, the application creates an initial snapshot of the source table in your data warehouse and the loads the results into your destination. During subsequent runs, CData Sync creates a new snapshot and compares it against the previous snapshot to capture the changes. Then, those changes are loaded into the destination.
Using the Delta Snapshot feature, Sync maintains an error table for logging rows that do not insert or update correctly, and it enables you to see individual errors at the row level. This feature also cleans up any failed rows from the previous snapshot.
With reverse ETL, you can choose from three modes to transfer your data:
-
Insert - Select this mode to insert new records into your source. For Insert mode, your source table must have a unique primary key. Each time you take a new snapshot, that key enables CData Sync to ensure that you are inserting new identifiers (Ids).
-
Upsert - Select this mode both to update existing records and to insert new records into your source. For Upsert, you must define a key that matches a record from your source table to your destination table. The key type must be one of the following:
-
an external Id, which allows Sync to use the Upsert API in Salesforce for better performance. Sync generates a list of external Ids that are defined in the Salesforce table, and you can choose an Id from that list.
-
an alternate key, which facilitated data movement between Sync and Microsoft Dynamics 365. After you create an alternate key, it is available on the Column Mapping tab for a reverse ETL job.
-
-
Update - Select this mode to update existing records in your source. Update mode uses the Salesforce Id or a Microsoft Dynamics 365 alternate key to match records in your source and destination tables. You must select a source column to map to the Salesforce Id or the Dynamics 365 alternate key.
Creating a Reverse ETL Job
To create a reverse ETL job, you need to define job parameters and then map required and optional columns as well as any keys that are necessary, as follows:
-
Select Jobs > Add Job > Add New Job. This step opens the Add Job dialog box.
-
Enter a job name.
-
Select your destination (Salesforce or Microsoft Dynamics 365) first. Then select your source, as shown in this example:
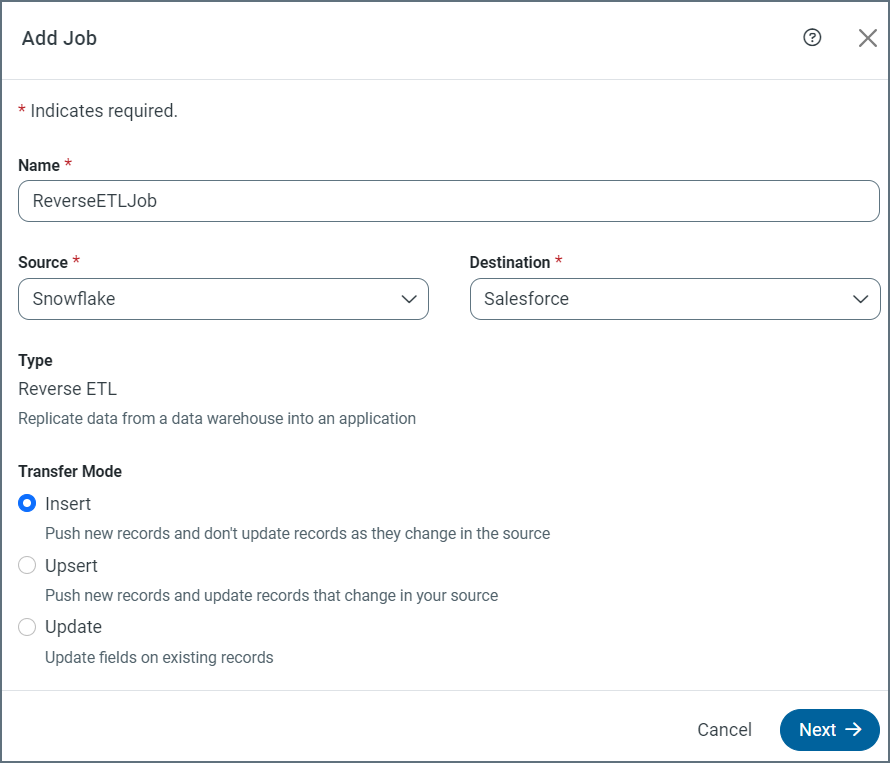
After you enter a source and a destination, the Add Job dialog box expands to include a Type and a Transfer Mode section, as shown above. The Type section indicates that your job is a reverse ETL job, and the Transfer Mode section enables you to select the type of data transfer that you want to perform. For details about the transfer modes, see Understanding the Reverse ETL Process.
-
Click Next.
-
Select your schema, a source table, and a destination table in the Configure Tables dialog box.
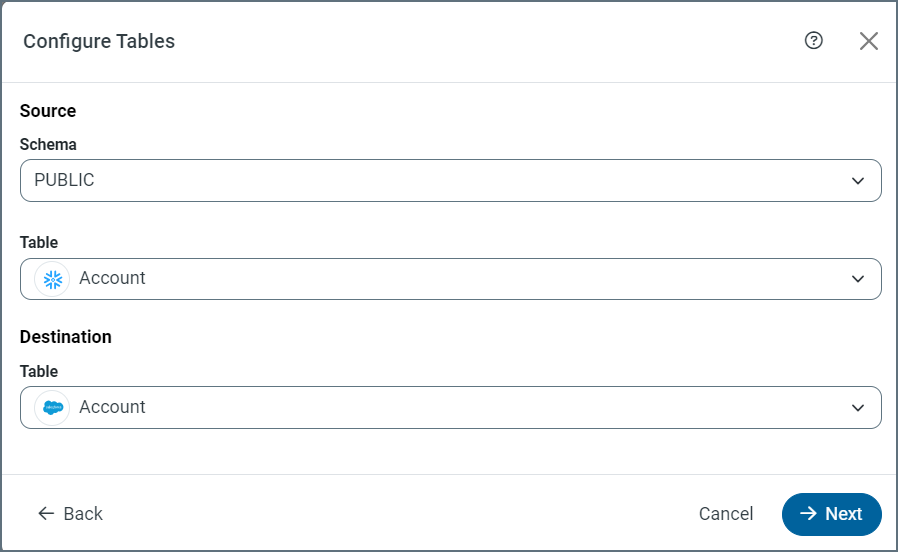
-
Click Next.
-
Configure your columns and keys in the Configure Mapping dialog box, as follows:
-
Choose your key (for Upsert and Update modes only).
-
Map any required columns.
-
Add any additional columns that you want.
-
-
Click Add Job to create your new job. After the job is created, Sync displays your table mappings on the Column Mapping tab, as shown below:
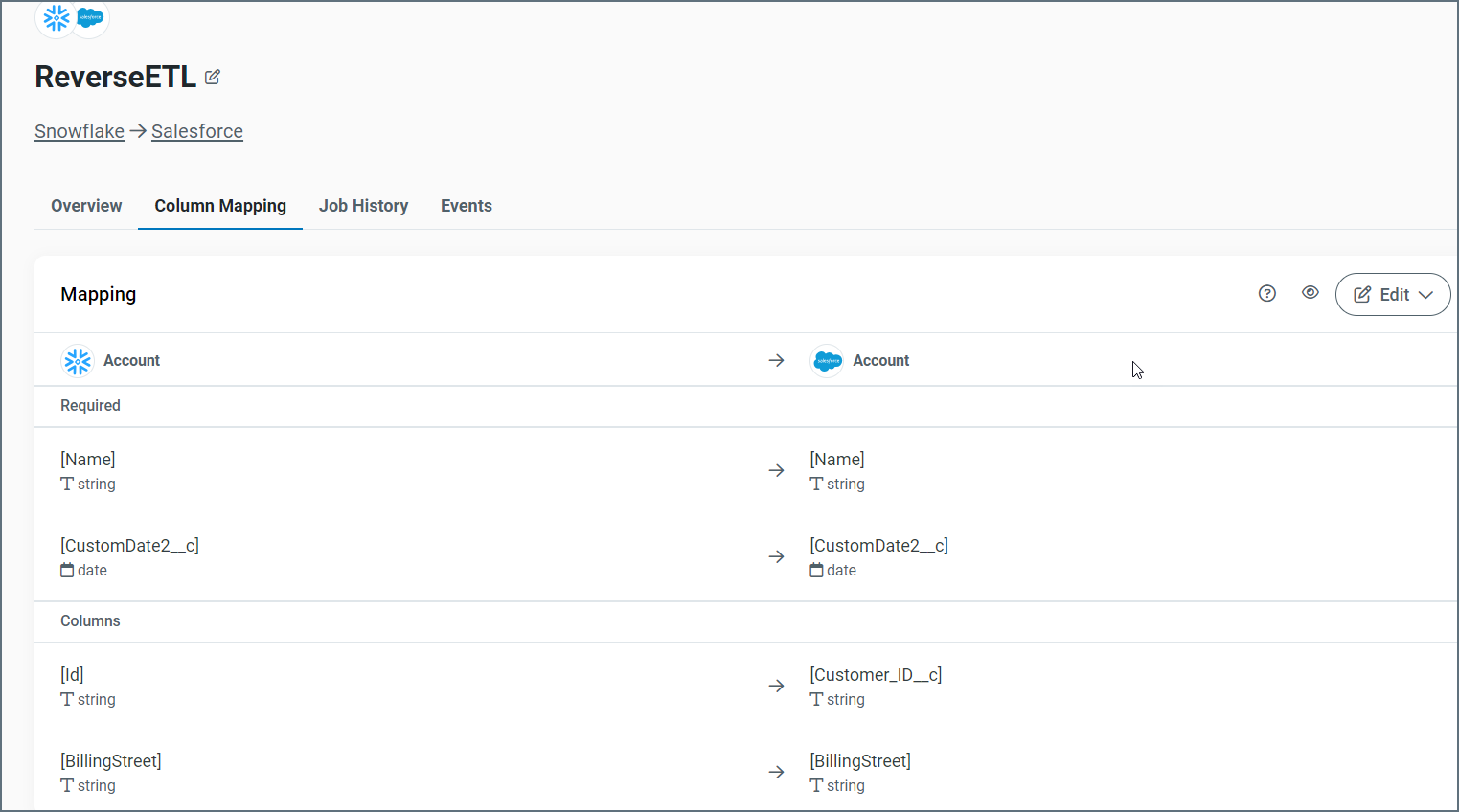
After you add your job, you can manage it as described in the next section.
Managing Your Job
Once you add your reverse ETL job, you can run and manage it like any other job it in Sync from the Jobs page. When you click your job in the application, Sync opens your job page with the standard tabs (Overview, Column Mapping, Job History, Events, and Advanced). The following sections explain how to manage settings and mappings for your reverse ETL job on the Overview, Column Mapping, and Advanced tabs.
Job Overview
The Overview tab for a job displays a summary of your settings, including the job type and transfer mode. In the example below, the job type is Reverse ETL and the transfer mode is InsertMode.
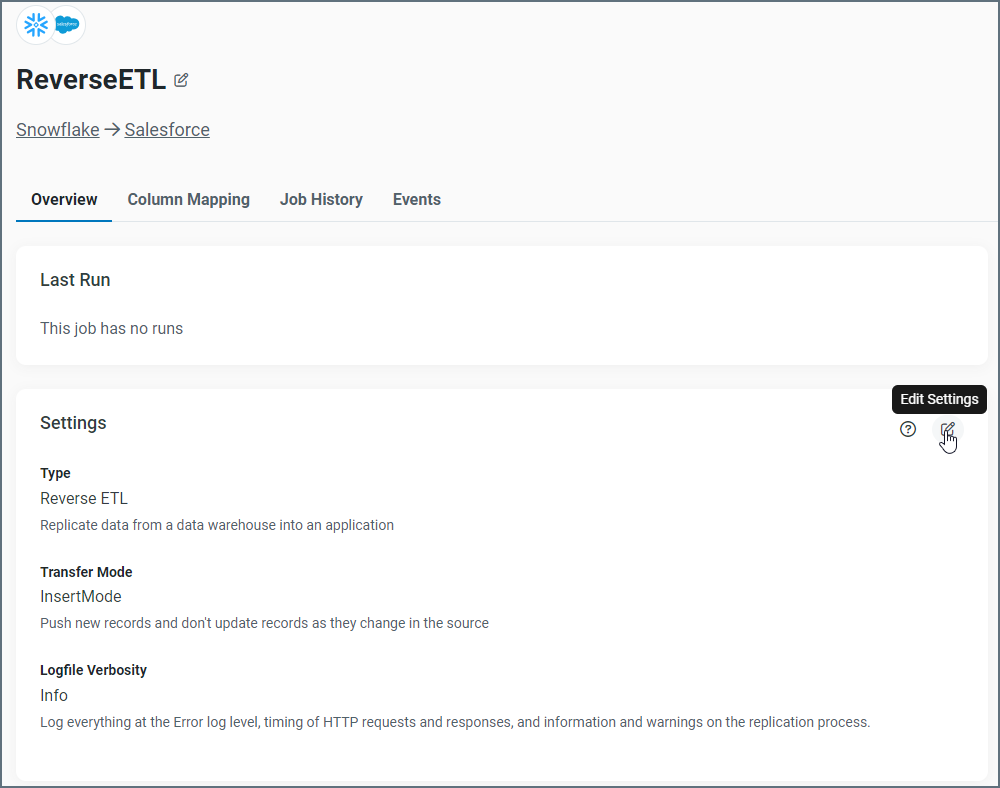
To edit your settings, click the Edit button. The only change that you can make in the Edit Settings dialog box is to select a different verbosity level for you log file.
Column Mapping
As explained earlier, Sync automatically opens the Column Mapping tab when you add a new job. This page shows you the mappings between your source and the Salesforce destination for both the required and optional columns. In addition, the page shows the mapping for keys for Insert mode.
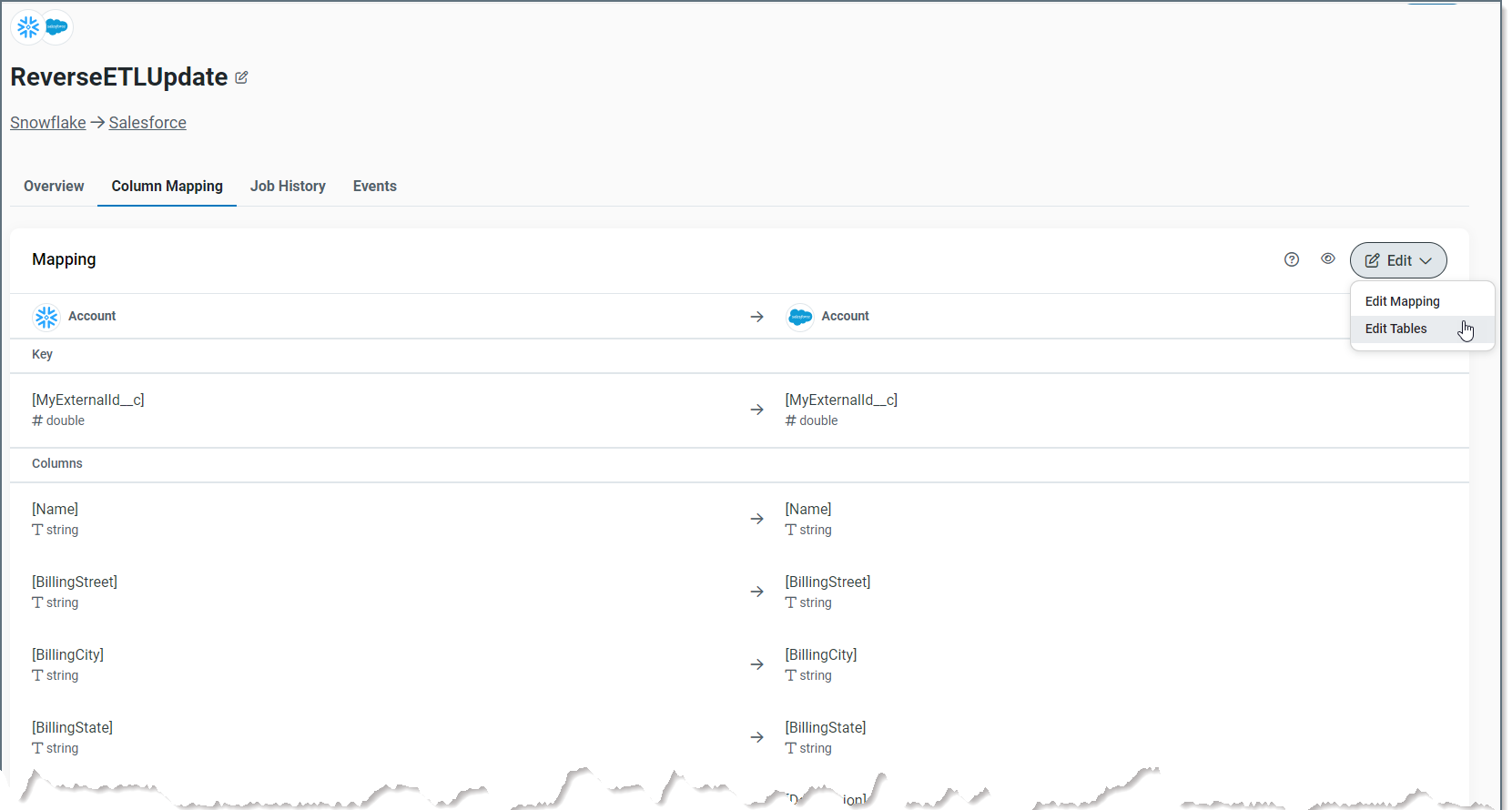
You can edit both the mappings and your table.
To edit your mappings:
-
Select Edit > Edit Mapping.

-
Add new columns or change any columns and keys that you want.
-
Click Save to save your changes and return to the Column Mapping page.
To edit your source or destination table:
-
Select Edit > Edit Tables. This selection takes you back to the Edit Tables dialog box.

-
Update the source or destination table. For example, select User for both the destination and source. Click Next.
-
Rebuild the column mapping for your job in the Edit Mapping dialog box.
-
Click Save to save your changes and return to the Column Mapping page.
Advanced Options
The Advanced tab contains advanced replication options for your job. Currently, for reverse ETL jobs, the tab contains one option, Reset Strategy. Sync uses primary keys to identify when rows in a table are added, modified, or deleted. For reverse ETL jobs, the Reset Strategy replication option defines how you should manage situations where the key is changed in the query.
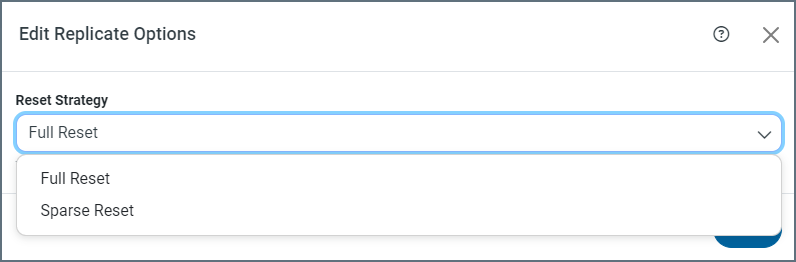
This option provides two settings:
-
Full Reset: When you use this setting, Sync replaces the snapshot table with a full replication of the source table, including previously replicated rows. Avoid using this option with Insert mode because it might create duplicate entries.
-
Sparse Reset: With this setting, Sync updates the snapshot table to match schema changes without altering existing rows or duplicating entries. As such, Sparse Reset is the preferred option for use with Insert mode.