Change Data Capture
Version 24.3.9120
Version 24.3.9120
Change Data Capture
Some sources support change data capture (CDC), where a source uses a log file to log events (Insert, Update, or Delete) that cause changes in the database. Rather than querying the source table for changes, CData Sync reads the log file for any change events. Then, the application extracts those changes in near real time for replication and stores the current log position for the next replication.
The following sources support CDC capability:
-
MariaDB - Uses binary logs.
-
Microsoft Dynamics 365 - Uses change tracking.
-
MySQL - Uses binary logs.
-
Oracle - Uses either Oracle LogMiner or Oracle Flashback. If both methods are enabled on a table, Sync uses Oracle LogMiner.
-
PostgreSQL - Uses logical replication.
-
SQL Server - Uses either CDC or change tracking. If both methods are enabled on a table, Sync uses CDC.
This document explains the following concepts and tasks:
-
defining a CDC pipeline
-
determining when to use CDC
-
enabling CDC for a source database
-
creating a CDC job in Sync
-
adding tasks to your CDC job
-
adding a post-job transformation
What Is a CDC Pipeline?
Change data capture (CDC) creates a pipeline that enables you to stream data changes from a source to supported destinations so you can run transformations on that data. Supported destinations can include any of the following structures:
-
another relational database
-
a cloud storage system or a data lake
-
a data warehouse (for example, Snowflake, Amazon Redshift, and Google BigQuery)
-
a file storage system
-
a message queue (for example, Kafka or Kinesis)
Determining When to Use CDC
The CDC approach integrates data through a process of identification, capture, and delivery of changes that are made to a source database. Those data changes are stored in a transaction log.
This approach makes sense in the following situations:
-
You are using one of the sources that supports CDC. As mentioned earlier, Sync supports native, log-based change data capture for MySQL, Oracle, PostgreSQL, and SQL Server.
-
You need near, real-time data. The CDC process provides near real-time data transfer in ETL and ELT processing.
-
You want to limit or preserve resource use. CDC data integration has low impact on your system because it does not make changes at the application level, nor does it scan transactional tables.
Enabling CDC for the Source Database
The way in which you enable CDC is different for each of the five database sources. For information about how to enable CDC for your source, click the appropriate link below.
Creating a CDC Job in CData Sync
Creating a job requires pre-configured source and destination connections. See Connections for more information about creating your source and destination connections.
After you define connections to your data source and your destination database, follow these steps to create a new job.
-
Select Add Job > Add New Job on the Jobs tab in Sync. This action opens the Add Job dialog box.
-
Enter your job name and select one of the supported CDC sources and a destination in the dialog box.
-
Select Change Data Capture as the replication type.
-
Enter the name of your replication slot in the Logical Replication Slot text box.
-
Click Add Job to create your job.
-
Return to the Jobs page to access your job.
Adding Tasks to Your CDC Job
Tasks control the data flow from a source into a destination table. In a standard replication job, all source tables are available to be added as replication tasks to the job.
To add tables as replication tasks:
-
Click a job on the Jobs tab in Sync.
-
Click Add Tasks in the Job Settings section of the Jobs/YourJobName page. This action opens the Select Schema dialog box.
-
Select the schema (for example, public) from the schema list.
-
Select specific tables in the dialog box or select the checkbox next to the source name to select all tables.
-
Click Add Tasks to add your new tasks.
-
Return to the Jobs page to access and run your job.
For more information about creating tasks, see Tasks.
Adding a Post-Job Transformation
Sync supports data transformation processes after job completion. Using advanced SQL queries or leveraging your existing dbt Core and dbt Cloud projects enables you to meet all your data needs in a single platform.
For more information about SQL transformations, see SQL Transformations. For more information about DBT transformations, see DBT Transformations.
Enhanced CDC Jobs in CData Sync
The Enhanced Change Data Capture (CDC) feature for jobs in Sync enables you to capture changes in real time. The mechanism for capturing changes is the CDC engine, explained in the following section.
CDC Engine
The CDC Engine is a component of the Sync application that is responsible for tracking and streaming real-time data changes from the database. By monitoring transaction logs (for example, WAL or redo logs), the CDC engine identifies data updates and temporarily stores these change events as files in a staging area for further processing. This staging area is in the jobs folder of the application directory (C:\ProgramData\CData\sync\jobs).
Each enhanced CDC job has its own dedicated CDC engine, which creates a unique subfolder for that job within the staging area. In addition, for every table in a given job, there is a corresponding subfolder that contains event files.
Managing the Stage File
To optimize the storage of change events, you can configure the stage.file.max.rows property, which specifies the maximum number of rows or lines that can be written to a single stage file. By default, this value is set to 100,000 rows. For jobs that involve tables with numerous columns or large objects (for example, binary data), CData recommends that you decrease the value of this property.
You can configure this property according to your table schema on the job’s Advanced tab, as shown in the following example:
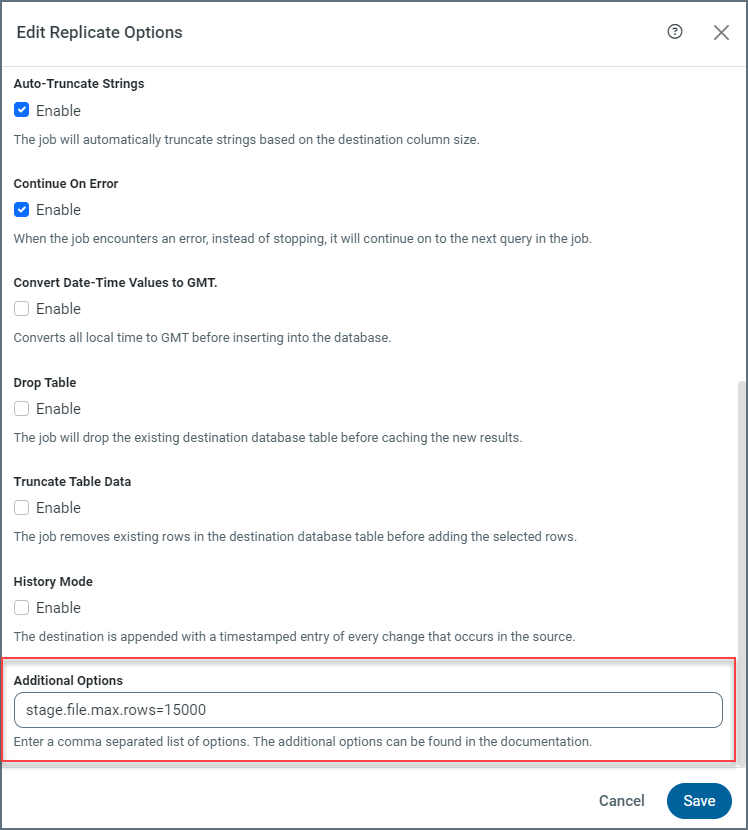
Managing the Stage Limit
Because all enhanced CDC jobs share the same staging area, it is essential to manage the staging area’s size carefully. By default, the stage is limited to 10 GB to prevent disk overloading. You can modify this limit with the stagemaxsize property.
If the staging area reaches its size limit, all CDC engines stop automatically. In such cases, you either must run the jobs manually or wait for the scheduled jobs to run in order to replicate the accumulated change events to the destination and release the staging area. If one-third of the maximum stage size (stagemaxsize) has been freed, all the CDC engines start automatically to resume the real-time data streaming process.
As an option, you can restart a CDC engine by clicking the Start button on the Overview tab.
Note: Because the CDC engine operates continuously and streams change events in real-time, you should schedule the job to run frequently as a best practice. This practice ensures near real-time replication while preventing the staging area from reaching its size limit.
Enabling Enhanced CDC for the Source Database
The way in which you enable enhanced CDC is different for each of the two database sources that can use this method of capturing changed data. For information about how to enable enhanced CDC for your source, click the appropriate link below.
Creating an Enhanced CDC Job in CData Sync
Creating a job requires pre-configured source and destination connections. See Connections for more information about adding source and destination connections.
After you define connections to your data source and your destination database, follow these steps to create a new job.
-
Click Add Job > Add New Job on the Jobs tab in Sync. This action opens the Add Job dialog box.
-
Enter your job name and select one of the supported enhanced CDC sources and a destination in the dialog box. Once you select your source, the replication type (Enhanced Change Data Capture) is displayed automatically.
-
Depending on your source, fill in the appropriate properties, as described below:
For the PostgreSQL Source (Postgres-CDC-Enhanced):
-
Publication Name: Enter the name of the PostgreSQL publication that you created for streaming changes. This publication is created at start-up if it does not exist already
Note: The publication must be unique to a job. Jobs cannot share publications.
-
Logical Replication Slot: Enter the name of your replication slot.
Notes:
-
The replication slot must be unique to a job. Jobs cannot share replication slots.
-
A PostreSQL user can create the logical replication slot upon startup, as well, if the user has sufficient permissions.
-
For the Oracle source (OracleDeb):
Enter the name of the Oracle pluggable database to which you want to connect in the Pluggable Database text box. Use this property with container database (CDB) installations only.
-
-
Click Add Job.
-
Return to the Jobs page to access your job.
Adding Tasks to Your Enhanced CDC Job
Tasks control the data flow from a source into a destination table. In a standard replication job, all source tables are available to be added as replication tasks to the job.
To add tables as replication tasks:
-
Click a job on the Jobs tab.
-
Click Add Tasks in the Job Settings section of the Jobs/YourJobName page. This action opens the Select Schema dialog box.
-
Select the schema (for example, public) from the schema list.
-
Select specific tables in the dialog box or select the checkbox next to the source name to select all tables.
-
Click Add Tasks to add your new tasks.
-
Return to the Jobs page to access your job.
For more information about creating tasks, see Tasks.