機能
Version 24.3.9121
Version 24.3.9121
機能
CData Sync は、あらゆるデータソースをあらゆるデータベースやデータウェアハウスなどにレプリケートするパワフルな機能を提供します。このドキュメントでは、次の機能について簡単に説明します。
-
差分レプリケーション
-
同期間隔(データの整合性)
-
削除キャプチャ(データとレコード)
-
データ型
-
データ変換
-
API 接続
-
ファイアウォールトラバーサル
-
スキーマの変更
初期レプリケーション
初めてジョブを実行すると、CData Sync はデータソースの履歴データ全体を処理します。このデータには膨大な量の情報が含まれています。そのため、Sync は、いくつかの戦略を用いて、効率、パフォーマンス、整合性を最大化します。またSync には、特定のデータセットに対して同期戦略を最適化するために使用できるユーザー制御のオプションも用意されています。
次のオプションを使用して、Sync が初期レプリケーションを処理する方法を制御できます。(これらのオプションは、ジョブを開いたときに表示されるジョブ設定カテゴリの高度な設定タブで利用できます。)
-
レプリケート開始値:Sync はデータソースの最小日付または自動インクリメントカラムの最小整数値(つまり、データソースの利用可能な最も古いレコード)から、データのレプリケーションを開始します。API によっては、エンティティの最小日付やint 値をリクエストする方法を提供していないものがあります。最小値を利用できない場合は、次の手順に従って手動で設定できます。
-
ジョブ設定でテーブルタブをクリックします。次に、タブに表示されたテーブルをクリックして、[タスク設定]モーダルを開きます。
-
モーダル内の高度な設定タブをクリックします。
-
レプリケート開始値オプションを見つけます。yyyy-mm-dd またはyyyy-mm-dd hh:mm:ss のいずれかの形式で日付を追加し、手動で最小開始日 / int 値を設定します。
開始日を指定しない場合、Sync はデータソースに対してクエリを実行し、1回のリクエストですべてのレコードを取得します。しかしながら、データソーステーブルが非常に大きい場合、この処理によって問題が発生する可能性があります。エラーが発生すると、Sync がクエリをデータの先頭から再実行するためです。
-
-
レプリケート間隔:Sync が最小開始日を決定した後、アプリケーションはデータの終わりに達するまで、指定した間隔で残りのデータを移動します。以下のオプションを使用して間隔を定義します。ジョブ設定ページの高度な設定タブでも利用可能です。
-
レプリケート間隔:このオプションをレプリケート間隔の単位と組み合わせて使用すると、データ取得中にデータを分割する時間間隔を設定できます。Sync は、この間隔を使用して更新をバッチ処理し、障害が発生したりレプリケーションが中断された場合に、前回の実行が終了したところから実行を開始できるようにします。デフォルトでは、Sync は180日間隔を使用します。しかし、データ量やどの程度データ間に時間的な間隔を置きたいかによって間隔を調整できます。
-
レプリケート間隔の単位:レプリケート間隔と組み合わせてこのオプションを使用すると、データ取得中にデータを分割する時間間隔を設定できます。使用できる値は、minutes、hours、days、weeks、months、years です。
-
差分レプリケーション
初期レプリケーション後、CData Sync は差分レプリケーションでデータを移動します。Sync は、毎回すべてのデータをクエリする代わりに、最後のジョブ実行時から追加、変更されたデータだけをクエリします。そして、Sync はそのデータをデータウェアハウスにマージします。この機能により作業負荷が大幅に軽減し、特に大きなデータセットを扱う場合に帯域幅の使用と同期の遅延が最小限に抑えられます。
多くのクラウドシステムはAPI を使用しており、それらのAPI からデータウェアハウスに完全なデータをプルすることは、多くの場合処理に時間がかかります。また、多くのAPI では1日単位でクオータが設定されており、毎日すべてのデータを取得したくてもできず、毎時や毎15分は不可能です。Sync はデータを差分ごとに移動させることで、遅いAPI や毎日のクオータに対処する際、非常に高い柔軟性を発揮します。
Sync は、主に2つの手法(差分チェックカラムと変更データキャプチャ)を使用して差分レプリケーションを取得します。これらの手法について、次のセクションで説明します。
差分チェックカラム
差分チェックカラムは、データを同期する際に新規または変更されたレコードを識別するためにSync が使用する、datetime またはinteger ベースのカラムです。データソースにレコードが追加または更新されるたびに、このカラムの値が増加します。Sync は抽出時にこのカラムを基準として使用し、新規または変更されたレコードのみが返されるようにします。その後、Sync はカラムの新しい最大値を保存し、次のレプリケーションで使用できるようにします。
差分チェックカラムを使用して行われるレプリケーションは、2種類の異なるデータ型を使用して実行できます。
-
DateTime 差分チェックカラム:レコードが最後に更新された日時を表すLast Modified またはDate Updated カラム。
-
整数ベースの差分チェックカラム:レコードが追加または更新されるたびに増分する自動インクリメントId または行のバージョンタイプ。
変更データキャプチャ
一部のデータソースでは変更データキャプチャ(CDC)をサポートしており、データソースはログファイルを使用して、データベースに変更を加えるイベント(挿入、更新、または削除)をログに記録します。Sync は、データソーステーブルに変更をクエリするのではなくログファイルを読み込んで変更イベントを確認します。次に、アプリケーションはレプリケーションのためのそれらの変更を抽出し、次回のレプリケーション用に現在のログを保存します。
以下のデータソースはCDC 機能に対応しています。
-
MariaDB は、バイナリログを使用します。
-
Microsoft Dynamics 365 は、変更の追跡を使用します。
-
MySQL は、バイナリログを使用します。
-
Oracle は、Oracle LogMiner またはOracle Flashback を使用します。両方のメソッドがテーブルで有効になっている場合、Sync はOracle LogMiner を使用します。
-
PostgreSQL は、論理レプリケーションを使用します。
-
SQL Server は、CDC または変更の追跡のいずれかを使用します。両方のメソッドがテーブルで有効になっている場合、Sync はCDC を使用します。
並列処理
CData Sync ジョブが並列処理を使用するように設定できます。これは、アプリケーションが1つのジョブを処理するために複数のワーカースレッドを使用することを意味します。並列処理により、Sync はワークロードを複数のプロセスに分割し、複数のテーブルを同時に移動できるようにします。その結果、より少ない時間でより多くのデータが移動され、ジョブ効率が大幅に向上します。Sync では、ジョブ単位で必要な数のワーカーを割り当てることができます。
並列処理を有効化するには:
-
実行するジョブをクリックします(Sync のジョブページから)。このアクションによりジョブ/任意のジョブ名ページが開きます。
-
ジョブ設定カテゴリの高度な設定タブをクリックします。
-
並列処理を有効化を選択します。
-
ジョブに割り当てるワーカー数をワーカープールフィールドに入力します。この値は、一度に並列に実行できるタスクの数を制御します。
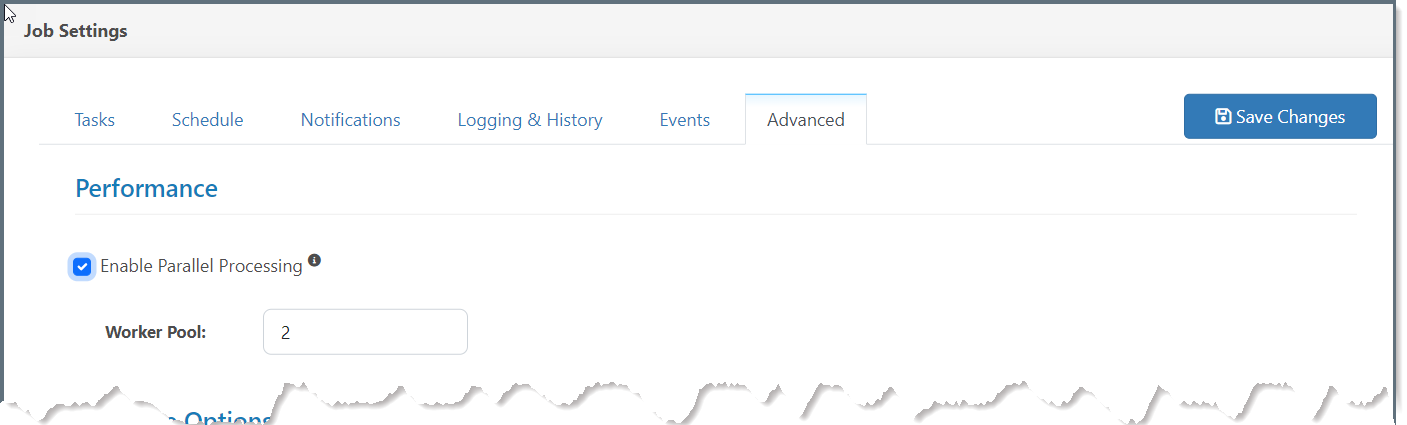
-
変更を保存(ジョブ設定ヘッダーバー右上)をクリックします。
これらの変更を保存すると、ジョブの実行時に並列処理が使用されます。
ジョブの自動再試行
CData Sync は、タスクエラーやネットワークの問題などで、1つ以上のタスクが失敗した場合にジョブの再試行を試みるジョブの自動再試行機能を提供します。ジョブの自動再試行処理は、ジョブ内の失敗したタスクにのみ適用されます。例えば、1つのタスクが失敗した場合、プロセスはその1つのタスクのみを再試行します。
このプロセスはすべての失敗したジョブ(キャンセルされたジョブを除く)に対して機能しますが、再試行が行われるのはそのようなジョブに対して一度のみです。
ジョブの自動再試行機能を有効にするには:
-
ジョブページでジョブの名前をクリック(または… > 編集を選択)して、YourJobName の設定ページを開きます。
-
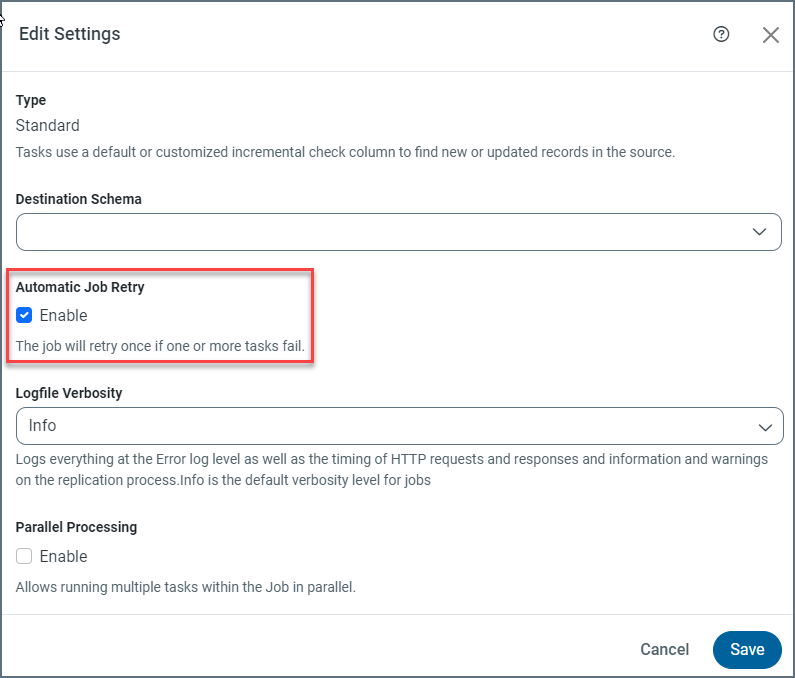
概要タブで、設定カテゴリの編集アイコンをクリックします。
-
ジョブの自動再試行設定の有効化チェックボックスを選択します。次に、保存をクリックして設定の更新を保存します。
失敗したジョブに対してジョブの自動再試行処理が実行されたら、ジョブの詳細(… > 実行の詳細 > タスク)で再試行に関する情報を確認することができます。
-
再試行に成功すると、
再試行に成功しましたというメッセージが、失敗していたタスクの最後の実行カラムに表示されます。 -
再試行に失敗すると、
再試行に失敗しましたというメッセージが、失敗したタスクの横の最後の実行カラムに表示されます。さらに、失敗した各タスクには詳細を表示リンクが表示されます。詳細を表示の左側にある下矢印をクリックすると、以下の例に示すように、失敗の詳細を含むエラーメッセージが表示されます: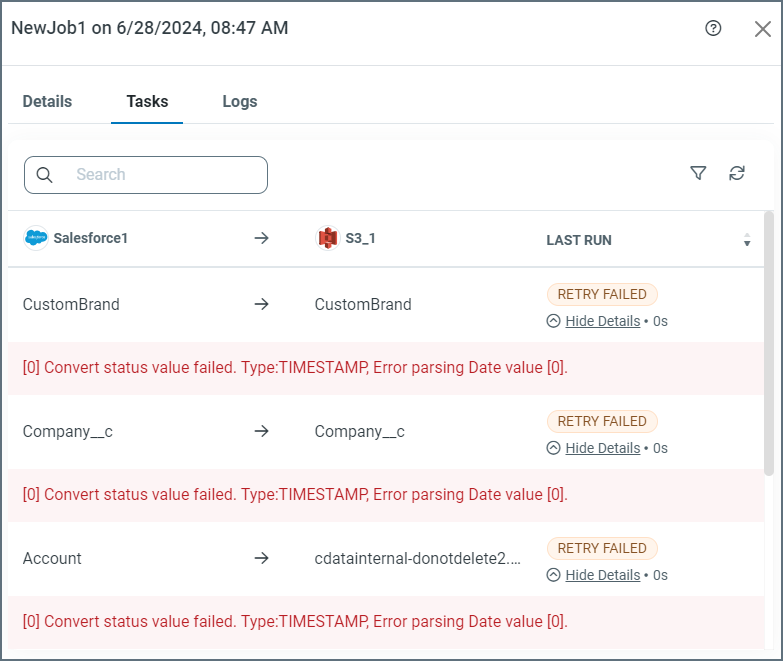
同期間隔(データの整合性)
データ統合戦略の一環として、元となるデータソースと同期先の間で、データの整合性を確保することが重要です。データパイプラインでエラーが発生した場合、またはジョブが中断された場合、データパイプラインプロセスを停止したところから再開する必要があります。この動作により、更新間やエラー発生時にデータが失われないことが保証されます。データ読み込みのための複雑なスクリプトやプロセスを設定することなく、CData Sync が自動的にそのアクションを管理します。
Sync は同期間隔に従ってデータを処理します。つまり、データをすべて一度に移動するのではなく、Sync がデータを扱いやすい間隔(またはデータの「チャンク」)に分割して、一度に1間隔ずつ処理します。この機能によって性能が大幅に向上し、エラーの際にもSync のデータの整合性が保たれます。Sync はデータソーステーブルと同期先テーブルを一致させます。エラーが起きた場合には、Sync は現在の間隔のデータをすべて捨ててその時点から処理を再開できます。
例えば、大規模な同期ジョブの完了間近にエラーが起きたとしましょう。Sync は最初からジョブ全体を開始するのではなく、最後に処理が完了した間隔から再開するので、時間とリソースを節約できます。
Note:API によっては、一定期間内にアクセスできる回数を制限するアクセス制限を設けているものがあります。これらの制限により、エラーが発生することがあります。このようなエラーが発生した場合、Sync は不完全な同期レコードを破棄し、次にスケジュールされたジョブでその時点から再開します。間隔の大きさを設定し、各間隔で取得するデータ量を決定し、エラーが発生した場合に移動する必要があるデータ量を制限することができます。
削除キャプチャ
CData Sync は削除されたレコードを自動でキャプチャして、同期先データの精度を保ちます。Sync はAPI 呼び出しや変更の追跡機能を使用して、削除されたレコードのリストをデータソースから取得します。
データソースがSync に対して削除されたデータの検出を許可している場合は、高度なジョブオプションで説明するように、削除の挙動オプションを使用してSync による削除の処理方法を制御できます。
-
Hard Delete(デフォルトパラメータ):データソースで削除が検出されると、Sync は同期先のテーブルからそのレコードを削除します。
-
Soft Delete:Sync は同期先テーブルに_cdata_deleted カラムを追加します。データソースで削除が検出されると、Sync は同期先の値をtrue に設定します。
-
Skip Delete:Sync はデータソースで削除されたレコードを無視します。
Note: データソース情報に記載されているとおり、API によっては削除されたレコードの検出をSync に許可しません。このようなケースでは、削除の挙動は無視されます。
データ型
CData Sync は多くのデータ型を認識し、データ型が厳密に定義できない場合には、Sync はデータに基づいてデータ型を推論します。Sync は次のデータ型を認識します。
- Boolean
- Date
- Time
- TimeStamp
- Decimal
- Float
- Double
- SmallInt
- Integer
- Long
- Binary
- Varchar
- GUID
既知のデータ型
多くのデータソースについて — そのほとんどがリレーショナルデータベースで、いくつかはAPI(SQL Server、Oracle など)ですが — Sync は自動的にスキーマ用のデータ型を検出します。データソースのカラムのデータ型が既知の場合、Sync は自動で一致するデータ型を同期先に作成します。
推論されたデータ型
データ型が指定されていない場合、Sync はカラムのデータ型を決定するためにデータの最初の数行を解析して、データ型を推論できます。
Sync が不明なカラムサイズの文字列型を検出した場合、カラムのデフォルトサイズは2000となります。SQL Server のようなリレーショナルデータベースでは、Sync はこの型用にvarchar(2000) フィールドを作成します。
データ型が厳密に定義されていないフィールドの場合、Sync は最初の行を読み取り、各カラムの最小のデータ型を自動的に選択します。その後、アプリケーションは次の行を読み取り、データが選択したデータ型で格納できるかを確認します。データが収まらない場合、Sync はデータ型のサイズを増やします。Sync は、これを行スキャンの深度(RowScanDepth - 50または100行)まで実行します。これが終了すると、Sync はデータ型を持っています。
例えば、CSV のようなデータソースでは、Sync はRowScan を使用してファイルの最初の数行を読み取り、動的に各カラムのデータ型を決定します。
変換
データパイプラインにおいて変換は、レポーティングやデータ分析を容易にするためにデータを加工、整形、集計する方法の1つです。Sync は、データパイプラインを構築する際にデータ変換を管理する2つの一般的な手法をサポートしています。
-
ETL: ETL(extract(抽出)、transform(変換)、load(ロード))処理は数十年にわたってアナリティクスの伝統的な手法となっています。ETL は、歴史的に市場を席巻してきたリレーショナルデータベースでの使用を想定して考案されました。ETL では、レプリケーション処理の前に変換を行う必要があります。データはデータソースから抽出され、ステージングエリアに格納されます。データは整形、修飾、変換されてデータウェアハウスにロードされます。ETL についての詳細は、In-Flight ETL を参照してください。
-
ELT: (extract(抽出)、load(ロード)、transform(変換))処理は、変換などのデータの変更がレプリケーション処理後に行われるデータ抽出の手法です。現代のクラウドデータウェアハウスは膨大なストレージとスケーラビリティを備えているため、データすべてを移動して、その後修正を加えることができます。
ELT 変換はデータの同期先で実行されるSQL スクリプトです。変換はデータウェアハウスの処理能力を使って、アナリティクスとレポーティング面でのニーズに基づき素早くデータを集計、結合、整形します。データを変換とマッピングで整理することで、パイプラインの移動に合わせてデータを最も役立つ形式で取得できます。ジョブ同様、変換はセミコロン(;)で区切られた複数のクエリをサポートし、スケジュールに従って実行し、変換の完了後にE メール通知が送信されます。ELT についての詳細は、Post-Job ELT を参照してください。
ETL とELT の主な違いは、手順を実行する順序です。
個人情報のマスキング
個人情報(PII)のマスキングは、データベースやデータテーブル内の機密情報のプライバシーとセキュリティを強化するデータ保護技術です。PII には、名前、住所、社会保障番号、その他個人を特定できるデータが含まれます。
マスキングは、PII を含む特定のカラム内の実際のデータを非表示にすることで、そのカラムへのアクセスを制限します。Sync においては、マスキングはポイントアンドクリックの変換オプションです。Sync でデータをマスクすると、データの各文字はアスタリスク(*)に置き換えられます。マスキングは一方向の操作です。つまり、一度マスキングを適用すると、データを以前の状態に戻すことはできません。マスキングは、EU 一般データ保護規則(GDPR)、US 医療保険の相互運用性と説明責任に関する法律(HIPAA)など、個人情報や機密情報の安全な取り扱いを義務付けるデータ保護規制を遵守するために重要です。
マスキングおよびその他の変換オプションの詳細については、SQL Transformation の適用を参照してください。
ヒストリーモード
CData Sync のヒストリーモードは、データソース内の履歴データを分析するための方法を提供します。ヒストリーモードは、データウェアハウスの比較的静的なデータ(現在および履歴)を保存および管理するslowly changing dimensionです。そのデータは、時間の経過とともにゆっくりと(しかし予測不可能に)変化することがあります。
CData では、ヒストリーモード(ヒストリーモードを有効化オプション)を使用してデータ行(レコード)の変更履歴を追跡し、データが時間の経過とともにどのように変化するかを確認できます。ヒストリーモードは、差分チェックカラムによるレプリケーションをサポートするすべてのコネクタで利用可能です。
CData は、履歴データを分析するための複合アプローチをサポートしています。つまり、ヒストリーモードを有効化オプションは、監査のための堅牢な追跡と時系列分析の両方を提供します。
ヒストリーモードはテーブル単位で機能します。そのため、どのテーブルを分析するかを決定し、それらのテーブルに対してのみオプションを有効にできます。
標準(個別設定)モードでは、Sync は既存の行をマージして更新しますが、ヒストリーモードでは、Sync は更新された行をデータベースのテーブルに追加します。
ヒストリーモードを有効化すると、
-
Sync は、ソースデータベーステーブルの各データレコードに対するデータ変更の完全な履歴を保持します。
-
Sync は、それらの変更バージョンを同期先データベーステーブルの対応するテーブルに記録します。
この機能を実現するために、Sync には同期先テーブルに3つの新しいカラムが含まれています。これらのカラムは次のテーブルで定義されています。
| カラム名 | カラム型 | 説明 |
|---|---|---|
| _cdatasync_active | Boolean | レコードがアクティブかどうかを指定します。 |
| _cdatasync_start | Datetime | データレコードがアクティブになった時点の差分チェックカラムのdatetime 値を指定します。この値は、データ更新ごとに増加するタイムスタンプに基づいて、データソーステーブルでレコードが作成または修正された日時を示します。 |
| _cdatasync_end | Datetime | データレコードが非アクティブになった時点の差分チェックカラムのdatetime 値を指定します。このカラムのNull 値は、レコードがアクティブであることを示します。 |
| _cdatasync_operation | Varchar | 使用するオペレーションを指定します:Insert (I)、Update (U)、またはDelete (D)。Note:このカラムは、変更データキャプチャ(CDC)を使用する場合にのみ適用されます。 |
| _cdatasync_version | Varchar(100) | CSRS テーブルに保存されるフォーマットの変更ごとにバージョンを指定します。Note:このカラムは、CDC を使用する場合にのみ適用されます。 |
制限事項
ヒストリーモードでは次の制約が適用されます。
-
データソーステーブルは差分チェックカラムをサポートしている必要があります。
-
ソーステーブルに主キーが含まれている必要があります。
-
差分チェックカラムがタイムスタンプ(datetime)カラムである必要があります。
-
疑似カラムはレスポンスに値を持たず条件としてのみ使用されるため、差分チェックカラムを疑似カラムにすることはできません。
-
同期先テーブルは存在できません。(高度な設定タブのテーブルを削除オプションを使用して、ヒストリーモードをアクティブにしてテーブルを再作成します。)
また、ヒストリーモードは次の同期先でのみサポートされています。
-
SQL Server
-
MySQL
-
PostgreSQL
-
Oracle DB
-
Snowflake
-
Databricks
-
Redshift
Note:同期先は、今後追加される予定です。
ジョブのヒストリーモード有効化
Sync のジョブに対してヒストリーモードを有効にするには、
-
ジョブタブに移動します。
-
選択したいテーブルを含むジョブをクリックします。
-
ジョブ設定にスクロールして、テーブルを追加をクリックします。[テーブルを追加]モーダルが開いたら、テーブルを選択します。
-
Add Selected Tables をクリックして選択したテーブルを追加し、ジョブ設定ページに戻ります。
-
高度な設定タブをクリックして高度な設定を開きます。
-
レプリケートオプションにスクロールしてヒストリーモードを有効化を選択します。
-
ジョブ設定ページの右上にある変更を保存をクリックして、選択したテーブルのヒストリーモードを保存し、有効にします。
ジョブ内のタスクのヒストリーモード有効化
以下に示すように、タスク設定の高度な設定タブから、タスクのヒストリーモードを有効にすることもできます。

タスクの高度な設定では、ヒストリーモードには3つのオプションがあります。
-
ジョブから継承:このオプションを指定すると、タスクはジョブからヒストリーモードを継承します。
-
True:このオプションは、タスクのヒストリーモードを有効にします。
-
False:このオプションはタスクのヒストリーモードを無効にします。
テーブルが差分チェックカラムをサポートしていない場合も、タスク設定でヒストリーモードが無効になります。
データソーステーブルを変更した場合の影響
行を挿入、更新、削除してデータソーステーブルを変更すると、次の表で説明するように、同期先はさまざまな形で影響を受けます。
| データソースの変更 | 同期先の影響 |
|---|---|
| 挿入された行 | 同期先テーブルに行が追加されます。_cdatasync_active はTrue に設定され、 _cdatasync_start は差分チェックカラムの値に設定されます。 |
| 更新された行 |
|
| 削除された行 | 同期先の現在の行が更新されます。_cdatasync_active はFalse に設定されます。 |
API 接続
CData Sync にはビルトインのREST(representational state transfer) API が含まれており、アプリケーションの柔軟な管理を実現します。管理コンソールのUI で実現できることはすべて、RESTful API コールで実現できます。
REST API は以下のもので構成されています。
-
ジョブ管理API は、ジョブを作成、更新、および実行できます。
-
接続管理API は、接続をリスト、作成、編集、削除、およびテストできます。
-
ユーザー管理API は、ユーザーを編集しすべてのユーザーをリストできます。
API 接続についての詳細は、REST-API も参照してください。
In-Network インストール
CData Sync はどこでも実行できるため、クラウド上にあるシステムと社内ネットワーク上にあるシステムを持つユーザーにとって最適なアプリケーションです。Sync をインストールしてネットワーク内で実行できるため、インターネットや開いたファイアウォール経由でポートが公開されたり、VPN 接続を作成したりすることを回避できます。
また、Sync アプリケーションをどこでも実行できることで、遅延を大幅に削減することができます。データソースや同期先の近くでSync を実行できるため、ETL やELT ジョブのパフォーマンスが向上します。
スキーマの変更
データは常に変化していますが、Sync はそれらの変化を常に正確に表すことを保証します。毎実行時、CData Sync はデータソースのスキーマと同期先のスキーマを比較して差分を検出します。Sync が2つのスキーマ間で構造の違いを検出した場合、アプリケーションは同期先のスキーマを変更し、以下で説明するようにデータソースのデータを格納できるようにします。
-
データソーステーブルに同期先テーブルに存在しないカラムが含まれている場合、Sync はカラムを追加することで同期先テーブルを変更します。
-
データソーステーブルのデータ型のサイズが増える場合、Sync はカラムのサイズを更新することで同期先テーブルを変更します。Sync は、文字列カラムのカラムサイズを増やしたり(例:varchar(255) -> varchar(2000))、非文字列カラムのバイトサイズを増やす(例:smallint -> integer)、といった変更を行います。
Notes:
-
Sync は、カラムがデータソーステーブルから削除されている場合でも、同期先テーブルからはカラムを削除しません。
-
Sync は、データソースでデータ型のサイズが更新された場合でも(varchar(2000) -> varchar(255))、同期先カラムのサイズは小さくしません。