EDIFACT Connector
Version 22.0.8473
Version 22.0.8473
EDIFACT Connector
The EDIFACT Connector can generate EDIFACT documents from XML and also convert EDIFACT documents into XML.
Overview
When receiving EDIFACT documents, EDIFACT Connectors validate EDIFACT interchange headers and convert the EDIFACT document into XML. This is useful as a staging step, as XML is the primary format that CData Arc uses to manipulate data within a flow. The EDIFACT Connector automatically reads the input file to determine the appropriate EDIFACT schema, then parses the document according to this schema.
When generating EDIFACT documents, EDIFACT Connectors convert XML into EDIFACT document syntax and apply the appropriate EDIFACT interchange headers. This is useful as the final step for creating an EDIFACT document, after the XML data has been fetched and transformed elsewhere in the flow.
Note that interchange header validation can be avoided by enabling the Test Indicator setting.
An EDIFACT Connector can also automatically generate acknowledgments to incoming EDIFACT documents. For more information, please see the EDIFACT Acknowledgments section.
Connector Configuration
This section contains all of the configurable connector properties.
Settings Tab
Translation Configuration
Settings related to how the connector will attempt to translate input files.
- Connector Id The static name of the connector. All connector-specific files are held in a folder by the same name within the Data Directory.
- Connector Description An optional field to provide free-form description of the connector and its role in the flow.
- Translation Type Whether the connector should convert EDIFACT documents into XML or XML data into EDIFACT documents.
Interchange Settings
Settings related to the interchange headers of EDIFACT documents. When generating EDIFACT documents, these settings are applied as interchange headers in the resulting document. When parsing EDIFACT documents, the interchange settings are used to validate the incoming document.
- Syntax Identifier (UNB1.1) Identifies the character set used in the EDIFACT document.
- Syntax Version (UNB1.2) In combination with the Syntax Identifier determines the syntax to be used in the EDIFACT document. The available elements for interchange settings may change depending on this value.
- Service Code List Directory Version Number (UNB1.3) Further specifies the syntax to be used in the EDIFACT document. Only applicable for EDIFACT syntax version 4.
- Character Encoding (UNB1.4) Specifies how characters are encoded (e.g. ASCII, UTF-8). Only applicable for EDIFACT syntax version 4.
- Sender Identifier (UNB2.1) The unique ID identifying the sending party in the EDIFACT communication (when generating an EDIFACT document, this should be your identifier).
- Sender Code Qualifier (UNB2.2) The qualifier for the Sender Identifier, providing context to the value (e.g. EAN location number).
- Address for Reverse Routing (UNB2.3) The optional address within the sender’s system to which responding interchanges should be sent. Only applicable for EDIFACT syntax versions earlier than version 4.
- Sender Internal ID (UNB2.3) An additional sender identifier to facilitate internal routing of response interchanges. Only applicable for EDIFACT syntax version 4.
- Sender Internal Sub-Identification (UNB2.4) Further identifies the sender, for when sub-level identification is required. Only applicable for EDIFACT syntax version 4.
- Recipient Identifier (UNB3.1) The unique ID identifying the receiving party in the EDIFACT communication (when generating an EDIFACT document, this should be your partner’s identifier).
- Recipient Code Qualifier (UNB3.2) The qualifier for the Recipient Identifier, providing context to the value (e.g. EAN location number).
- Routing Address (UNB3.3) The optional address within the recipient’s system to which interchanges should be routed. Only applicable for EDIFACT syntax versions earlier than version 4.
- Recipient Internal ID (UNB3.3) An additional recipient identifier to facilitate internal routing of received interchanges. Only applicable for EDIFACT syntax version 4.
- Recipient Internal Sub-Identification (UNB3.4) Further identifies the recipient, for when sub-level identification is required. Only applicable for EDIFACT syntax version 4.
- Recipient Password (UNB6.1) Reference or password to gain access to the recipient’s system.
- Recipient Password Qualifier (UNB6.2) The qualifier that provides context to the Recipient Password, if applicable.
- Application Reference ID (UNB7) Identifies the application group to which the messages in the interchange relate.
- Processing Priority Code (UNB8) Code for requesting processing priority for the interchange.
- Communication Agreement (UNB10) Defines the type of communication agreement controlling the interchange.
- Test Indicator (UNB11) Whether the interchange is in test mode or production mode. If this setting is enabled when receiving documents, interchange headers will not be validated.
Functional Group Settings
Settings related to the functional group headers of EDIFACT documents. These optional identifiers may help group similar interchanges together or facilitate sub-addressing within an organization.
- Application Sender Identifier (UNG2.1) Identifies the application sending the document (e.g. a division, branch, or computer system).
- Application Recipient Identifier (UNG2.1) Identifies the application for which the document is intended.
Acknowledgments
Settings related to generating and requesting acknowledgments.
- Technical acknowledgment (CONTRL) expected Whether a technical CONTRL ACK should be returned (when receiving) and requested (when sending). A technical acknowledgment serves as a receipt of the interchange.
- Functional acknowledgment (CONTRL) expected Whether a functional CONTRL ACK should be returned (when receiving) and requested (when sending). A functional acknowledgment serves as an indication of acceptance or rejection of the received interchange.
Automation
Settings related to the automatic processing of files by the connector.
- Send A toggle that instructs the connector to automatically send files when they are ready.
- Retry Interval The interval the connector will wait before retrying a failed send.
- Max Attempts The number of attempts the connector will make to send the message. Setting this value to 1 instructs the connector to only make the initial send attempt without retrying. The connector waits the duration specified by Retry Interval between each attempt.
Performance
Settings related to the allocation of resources to the connector.
- Max Workers The maximum number of worker threads that will be consumed from the threadpool to process files on this connector. If set, overrides the default setting from the Profile tab.
- Max Files The maximum number of files that will be processed by the connector each time worker threads are assigned to the connector. If set, overrides the default setting from the Profile tab.
Advanced Tab
EDI Delimiters
Settings that specify which characters separate elements, segments, etc.
- Data Element Separator The character that separates individual data elements within the document.
- Component Element Separator The character that separates elements within a composite data structure in the document.
- Segment Terminator The character that indicates the end of a segment within the document.
- Release Char The character that ‘releases’ or ‘escapes’ the next character, overriding its usual meaning. This allows reserved characters to appear as data withing documents, as long as they are preceded by the Release Char.
- Repetition Char The character that indicates repetition of element values.
- Suffix Appended to the Segment Terminator to distinguish segments.
Tracked Headers
You can enable tracking for UNB2.1, UNB3.1, and Transaction Types by selecting the corresponding checkboxes. When enabled, these values are added as headers to processed messages. These headers are required when running EDI Reports.
Other Settings
Settings not included in the previous categories.
- Batch Transactions Whether multiple transactions should be grouped together in a single output file. If false, each transaction found in the interchange will result in a separate output document.
- Element Ref By ID When translating EDIFACT into XML, whether reference ID’s will be used to name XML elements, for example:
<_143>value</_143>
If false, the Reference designator will be used to name XML elements:
<BEG03>value</BEG03> - Expand Qualifier Values When translating EDIFACT into XML, whether elements containing an EDI qualifier will have child elements ‘Code’ and ‘Value’ to express the qualifier code and value. For example:
<N101>
<Code>ST</Code>
<Value>Ship To</Value>
</N101> - Generate Description As When translating EDIFACT into XML, descriptions of the EDIFACT segments and elements will be provided as context for the EDIFACT data. This context can be added as an XML comment or included within the XML elements as XML attributes. Use this setting to determine which of these approaches, or neither, is used.
- Return inbound functional acknowledgments By default, the connector will route acknowledgments (997, 999) to the connector specified by the Route To Connector setting (or the ACK connections established in the Flows canvas). When this setting is enabled, the connector will also write these ACKs as output in the Receive folder so that they can be processed through an Arc Flow like any other EDI document.
- Nest Master-Detail Loops When enabled, the connector will detect EDI structures (e.g. CPS/HYN Loops) that have hierarchical relationships embedded in the EDI data, and will generate XML with these hierarchical relationships represented as Parent-Child relationships. For more information, please see the Master-Detail Hierarchy: Translating CPS and HYN Loops section.
- SNIP Validation When enabled, the connector will perform the first three levels of SNIP Validation for HIPAA compliance: (1) the syntactical integrity of the document, (2) the presence of required segments and appropriate repetitions for repeated segments, and (3) the correct mathematical relationship between claim line items and claim totals. Higher levels of SNIP Validation (4+) may require a Validate Connector or custom script.
- Send Filter A glob pattern filter to determine which files in the Send folder will be processed by the connector (e.g. *.edi). Negative patterns may be used to indicate files that should not be processed by the connector (e.g. -*.tmp). Multiple patterns may be separated by commas, with later filters taking priority except when an exact match is found.
- Local File Scheme A filemask for determining local file names as they are processed by the connector. The following macros may be used to reference contextual information:
%ConnectorId%, %Filename%, %FilenameNoExt%, %Ext%, %ShortDate%, %LongDate%, %RegexFilename:%, %DateFormat:%, %ControlNumber%, %TransactionControlNumber%, %TransactionCode%, %StandardVersion%.
As an example: %FilenameNoExt%_%ControlNumber%%Ext% - Parent Connector The connector from which settings should be inherited, unless explicitly overwritten within the existing connector configuration. Must be set to a connector of the same type as the current connector.
- Strict Schema Validation Whether the connector should Ignore, Warn, or Fail when the following are detected: Repeat counts above the allowed number; missing required elements/segments; invalid qualifier and code values; disallowed element lengths; invalid element values.
- Log Subfolder Scheme Instructs the connector to group files in the Logs folder according to the selected interval. For example, the Weekly option instructs the connector to create a new subfolder each week and store all logs for the week in that folder. The blank setting tells the connector to save all logs directly in the Logs folder. For connectors that process many transactions, using subfolders can help keep logs organized and improve performance.
- Log Messages Whether the log entry for a processed file will include a copy of the file itself.
- Save to Sent Folder Whether files processed by the connector should be copied to the Sent folder for the connector.
Miscellaneous
Settings for specific use cases.
- Other Settings Allows configuration of hidden connector settings in a semicolon-separated list, like
setting1=value1;setting2=value2. Normal connector use cases and functionality should not require use of these settings.
Converting Formats
The following sections detail the process of converting EDIFACT to XML and vice versa.
EDIFACT to XML
Setting the Translation Type to EDI-to-XML will instruct the connector to parse incoming EDIFACT documents into XML. The connector first reads all of the header information for the Interchange and Functional Group sections of the document and validates them against the configured connector settings (unless Test Indicator is enabled). The connector then parses out the specific EDIFACT schema used in the document and loads the schema from the ‘edifact_schemas’ folder on disk (additional schema files can be downloaded from our website for free). Using the schema, the connector generates XML representing the EDIFACT structure of the document, populates the XML with the values from the document, and provides context to each value either as XML comments or as attributes within the XML elements (depending on the value of Generate Descriptions As).
To see this process with a set of test EDIFACT documents, navigate to the Input tab of an EDIFACT Connector (with Translation Type set to EDI-to-XML) and select More > Create Test Files. EDIFACT documents for an Invoice, Purchase Order, Purchase Order Acknowledgment, and Shipping Notice will be automatically generated and placed in the Input directory. After these test files are processed by the connector, navigate to the Output tab to see the resulting XML.
Once EDIFACT documents are converted to XML, the data can be transformed and manipulated in many ways. Commonly, EDIFACT data needs to be stored in a database or other back-end application system. Since Arc uses XML to represent Inserts into these back-end systems, storing the EDIFACT data becomes a matter of simply mapping one XML structure onto another. This is typically done with the visual designer-driven XML Map Connector.
XML to EDIFACT
Setting the Translation Type to XML-to-EDI will instruct the connector to generate an EDIFACT document out of an XML representation of the document. After the connector has constructed the EDIFACT message out of the data parsed from the XML, it will add Functional Group and Interchange headers according to the configured connector settings.
To see this process with a set of test XML files, navigate to the Input tab of an EDIFACT Connector (with Translation Type set to XML-to-EDI) and select More > Create Test Files. XML files representing an Invoice, Purchase Order, Purchase Order Acknowledgment, and Shipping Notice will be automatically generated and placed in the Input directory. After these test files are processed by the connector, navigate to the Output tab to see the resulting EDIFACT document.
EDIFACT Acknowledgments
The following sections detail the two types of EDIFACT acknowledgments (ACKs), and how Arc expects, processes, and generates ACKs.
Technical versus Functional Acknowledgments
Technical ACKs, sometimes called interchange ACKs, are an indication that an interchange has taken place between the two parties, though not necessarily that any individual message has been exchanged. These serve as a receipt to the sender indicating that the EDIFACT message was successfully received, but it does not specify whether there were any issues while processing the content of the message.
Functional ACKs are an indication that an interchange has been processed by the receiving party. It may report acceptance, acceptance with issues, or rejection of the received document. These serve as both a receipt that an interchange was successfully received and that it was fully processed.
Expecting Acknowledgements
EDIFACT Connectors, while operating in XML-to-EDI mode, can be configured such that interchange and/or functional ACKs are expected for a message. When either Technical acknowledgment (CONTRL) expected and/or Functional acknowledgment (CONTRL) expected are enabled in the Settings tab, the connector will maintain a ‘Pending ACK’ status for a transmission until the appropriate ACKs have been returned and processed. Thus, the connector status can be used to determine whether the recipient has confirmed that they received the interchange.
The following diagram shows the logical flow involved when expecting an ACK from an Invoice document:
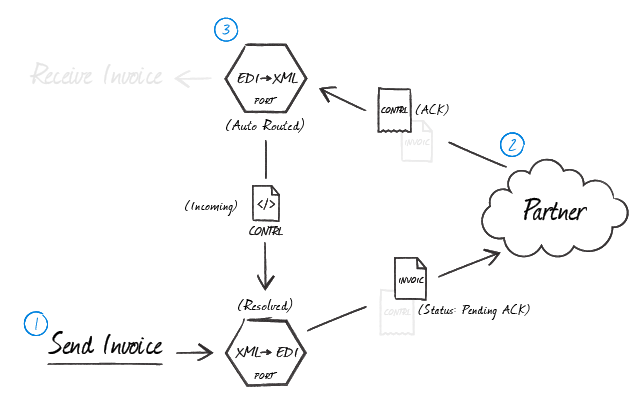
In the above illustration, an EDIFACT Connector operating in XML-to-EDI mode generates the document to be exchanged (1) and holds it in a Pending ACK state while the document is transmitted to the trading partner. The trading partner processes the transmission according to their business logic and creates acknowledgments in accordance with the configured exchange parameters (2). When the acknowledgments are returned, they are processed according to the information in the next section (3).
Processing Acknowledgments
In a typical flow, EDIFACT ACKS will arrive at an EDIFACT Connector operating in EDI-to-XML mode. This EDIFACT Connector can be configured to automatically route any received acknowledgments to the EDIFACT Connector that originally generated the document being acknowledged. Routing ACKs between EDIFACT Connectors is configured visually in the Flows canvas by dragging the gray dot at the bottom edge of one EDIFACT Connector (the one in EDI-to-XML mode) onto the other EDIFACT Connector (which is in XML-to-EDI mode).
Once the EDIFACT Connector in XML-to-EDI mode receives the routed ACK, it pairs the ACK to the original message and resolves its state from ‘Pending ACK’ to ‘Sent’.
Generating Acknowledgements
When an EDIFACT Connector in EDI-to-XML mode receives a message and generates the corresponding XML, it can automatically generate CONTRL acknowledgments for the received message. To accomplish this, enable Technical acknowledgment (CONTRL) expected and/or Functional acknowledgment (CONTRL) expected within the connector’s Settings tab. These acknowledgments must be routed to another EDIFACT Connector (in XML-to-EDI mode) to finalize the ACK. The connector to which the ACK is routed will apply Interchange headings and pass the ACK along to the next connector in the flow like any other EDIFACT message. To route the ACK appropriately, drag the gray dot at the bottom of edge of the EDIFACT Connector in EDI-to-XML mode onto the other EDIFACT Connector (which is in XML-to-EDI mode).
The below diagram shows the logical flow involved when creating an ACK for a received Invoice document:
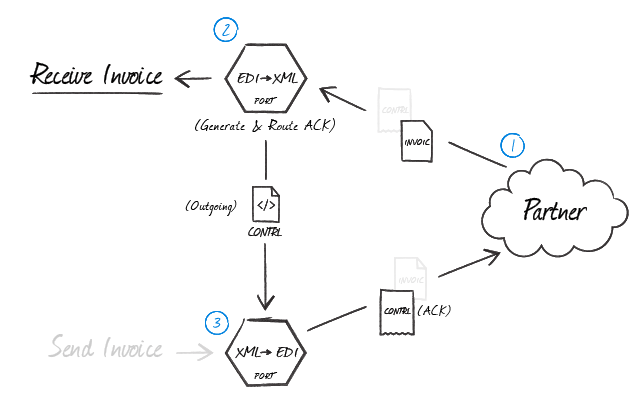
As shown in the above illustration, after a trading partner sends a message expecting an acknowledgment (1), the EDIFACT Connector in EDI-to-XML mode that parses the document automatically generates an ACK (2). This ACK is an XML file containing the transactional information relevant for the transaction. Then, this XML acknowledgment is routed back to an EDIFACT Connector in XML-to-EDI mode (3) so that the Interchange headers (and any other EDI party agreement settings) are applied before the ACK is sent back to the trading partner.
Master-Detail Hierarchy: Translating CPS and HYN Loops
In EDI documents, most hierarchical relationships are represented by the order of EDI segments. Some EDI structures, like CPS Loops (which are found in DESADV documents) and HYN Loops (which are found in PRICAT documents), do not follow this convention and instead have the hierarchical relationships embedded in the EDI element data itself. This can make it difficult to preserve these hierarchical relationships when converting the EDI data to XML.
The EDIFACT Connector supports preserving hierarchical relationships in CPS segments via the Nest Master-Detail Loops setting in the Advanced tab. When enabled, the connector will parse the elements within the CPS segments to determine which segments “belong to” other segments in a hierarchical relationship. These hierarchical relationships are reflected in the output XML as Parent-Child relationships; in other words, this setting converts hierarchy implied by the EDI content into hierarchy represented by the XML structure.
This section will briefly explain both how hierarchy is encoded in CPS/HYN data, and how this hierarchy is converted into XML when Nest Master-Detail Loops is enabled.
CPS/HYN Hierarchy
All CPS/HYN segments have two values that help establish hierarchy:
- an ID value, which identifies the current CPS segment (this value is stored in CPS01, or the first element in an CPS segment)
- a parent-ID value, which identifies the current CPS segment’s hierarchical parent (this value is stored in CPS02, or the second element in an CPS segment)
For example, say that an CPS segment has an ID value of ‘2’. If the next CPS segment should “belong to” this prior segment in a hierarchical relationship, then the next CPS segment’s parent-ID should also be ‘2’.
If an CPS segment’s parent-ID is ‘0’, this means that the segment does not have a parent (i.e. it is at the top level of the hierarchy).
Converting CPS/HYN Hierarchy to XML
When Nest Master-Detail Loops is enabled, the EDIFACT Connector handles the conversion of CPS/HYN hierarchy to XML hierarchy automatically. The connector parses the ID and parent-ID values from CPS/HYN segments and ensures that the resulting XML elements are appropriately nested (indented) inside the elements representing their parents.
In other words, if segmentA’s parent-ID value is equal to segmentB’s ID value, then the resulting XML will have segmentA as a child of segmentB. In this way, the hierarchical relationships are preserved in the XML structure when the EDI data is translated.
EDIFACT Operations
In addition to the Operations provided with Arc, connectors may provide operations that extend functionality into ArcScript. Operations specific to the functionality of the EDIFACT Connector are listed below.
edifactScan
Scans header values from the headers of an EDIFACT document.
Required Parameters
- file: The path to the EDIFACT file.
Optional Parameters
- format: The file format. The default value is ‘EDIFACT’.
Output Attributes
- InterchangeSenderIdQualifier: The interchange qualifier of the sender Id (UNB2.2).
- InterchangeSenderId: The interchange sender Id (UNB2.1).
- InterchangeReceiverIdQualifier: The interchange qualifier of the receiver Id (UNB3.2).
- InterchangeReceiverId: The interchange receiver Id (UNB3.1).
- DocumentType: The document type or transaction set Identifier code (UNH2.1).
Common Errors
Below is a list of common errors, their causes, and the recommended solution. Please contact [email protected] for more information.
ERROR:
“Schema file not found ([schema major version] [schema document type])”
Cause
When Arc parses an EDIFACT file, it first scans the file for the EDI version and document type to determine which schema to use during parsing. The application includes an extensive set of EDIFACT schemas in JSON format. They are stored in the schemas folder in the application directory (next to the data folder).
This error indicates that the application could not find a schema file matching the major version and document type reported by the file.
If either the [schema major version] value or [schema document type] value are missing in the error message, this indicates that EDI document does not contain the major version or document type.
Otherwise, this indicates that the appropriate document schema is not included in the set of schema definitions automatically included with Arc.
Resolution
If the EDI file does not contain the schema major version or document type, contact the trading partner (or other source of the EDI document) and inform them that these values must be included in the message header.
Otherwise, find the appropriate schema version from our free download page here. Download the schema folder and place it in the following path:
[application_directory]\schemas\edifact_schemas\[major_version]\
ERROR:
“The segment at line [line number] with tag [segment name] is not in a valid position in the specified schema ([schema major version] [schema document type]). This may indicate that the input file contains segments that are out of order.”
Cause
When Arc parses an EDIFACT file, it first scans the file for the EDI version and document type to determine which schema to use during parsing. The application includes an extensive set of EDIFACT schemas in JSON format, stored in the ‘www\app_data’ folder of the root installation directory.
This error indicates that the parser encountered an EDI segment in the file that does not match the order of segments defined in the relevant document schema. This may indicate a few different issues:
- The EDI file was generated incorrectly by the trading partner
- The EDI file was generated using a different schema version than what is indicated in the file
- The EDI file was generated using a custom schema
Resolution
If the EDI file was generated using a custom schema, simply place this custom schema file (in JSON format) in the folder where Arc reads EDI schemas. The specific folder depends on the major version of the EDI schema:
[installation_directory]\www\app_data\edifact_schemas\[major_version]\
If the EDI file was not generated using a custom schema, there are two approaches to resolving the discrepancy between the EDI file generated by the partner and the EDI schema used to parse it.
- Manually edit the appropriate EDI schema file (found in the filepath above) to adjust the segment order so that it matches the partner’s EDI files. The error message indicates the line in the file where the segments diverge from the schema definition. Trace through the JSON definition of segment order until the divergence is found, and re-order the segments in the JSON to match the file provided by the partner.
- Contact the trading partner about the EDI file. Confirm that the file was generated according to the major version that is reported by the file, and explain that the order of the segments in the file was not recognized.
The approach to use depends on the familiarity with EDI segments for the particular document type (to correctly edit the JSON schema according to the partner’s file) and the partner’s flexibility (to adjust the EDI file in response to informing them about the error).