Databricks Lookup Configuration
Version 22.0.8473
Version 22.0.8473
Databricks Lookup Configuration
The Lookup action retrieves a value from Databricks and inserts that value into an existing Arc message in the flow.
Lookup Query
Follow these steps to configure a Lookup query for the Databricks connector:
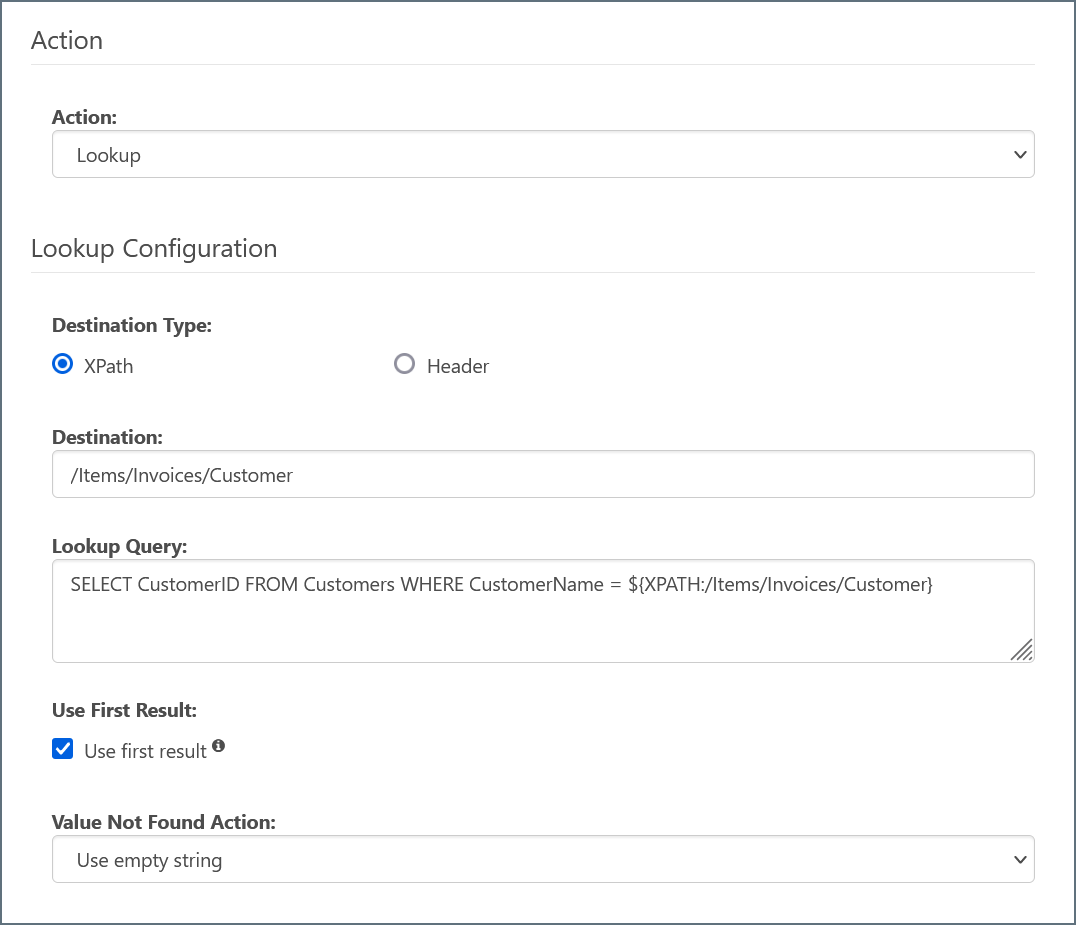
-
In the CData Arc flow, drag an arrow from the connector that will provide input to the connector.
-
Under Destination Type, select either XPath to insert the query response values into an XML file or Header to insert the query response value into a message header.
- Provide the Destination for the query response values:
- For XPath, enter the XPath value to the desired destination in the XML file, e.g.
/Items/Invoices/Customer. - For Header, enter the name of the new message header for the data.
- For XPath, enter the XPath value to the desired destination in the XML file, e.g.
- In the Lookup Query, enter the SQL query to retrieve data to retrieve from Databricks tables.
- For XPath, format the path as
${XPATH:/path/to/element}. For example,SELECT CustomerID FROM Customers WHERE CustomerName = ${XPATH:/Items/Invoices/Customer}. - For Header, format the path as
${HEADER:HeaderName}.
- For XPath, format the path as
-
If the query you entered could return multiple values, check Use first result to avoid errors.
-
Set Value Not Found Action to the desired behavior for values that cannot be found.
- In the Arc flow, drag an arrow from the Databricks connector to the connector where you want your resulting XML or Header data to go.
Cache
The Databricks connector provides the ability to perform Lookup queries against a local cache instead of querying Databricks directly for each Lookup. This can improve query performance, especially with larger databases.
To enable this feature, check the Enable Cache box and configure the fields as needed. If a query returns no results from the cache, the connector then queries Databricks directly.
Note: If your query statement contains a limit, offset, or groupby parameter, the cache function will not work. These queries instead go directly to Databricks.