Architecture
Version 22.0.8473
Version 22.0.8473
Architecture
CData Arc is a message-driven platform for integrating business processes. It provides a centralized Communications Hub that enables applications, databases, and external messaging systems to talk to each other.
Design Principles and Implementation
The Arc architectural decisions flow from a set of core design principles. This section focuses on three aspects of Arc design:
- Principles and values that we prioritize
- Core concepts necessary for a high-level understanding of Arc
- Architectural decisions and how they fit with our design principles
The Principles and Concepts sections are intended for both technical and non-technical users. The remaining implementation sections are intended to help engineers understand how to leverage the Arc architecture.
Core Principles
The following are the key principles of Arc design:
- Transparency
- Simplicity
- Modularity
- Accessibility
The Arc architecture is not the only way that the design principles above could be implemented in an integration platform. What follows are explanations of our implementation choices and how they fit with our design principles.
Concepts
At a high level, Arc solutions are composed of three elements:
- Flows
- Connectors
- Messages
Flows
Arc Flows are configured workflows that perform an automated set of data processing tasks. Flows are composed of a number of Connectors that are connected to each other so that data processed by one Connector is automatically passed along to the next Connector in the Flow.
In the user interface, Flows are shown in the Flows page. Connectors are dragged from the toolbox on the left into the blank canvas where they can be configured and connected to each other. The image below represents a simple Flow consisting of two Connectors: an AS2 Connector and an X12 Connector:
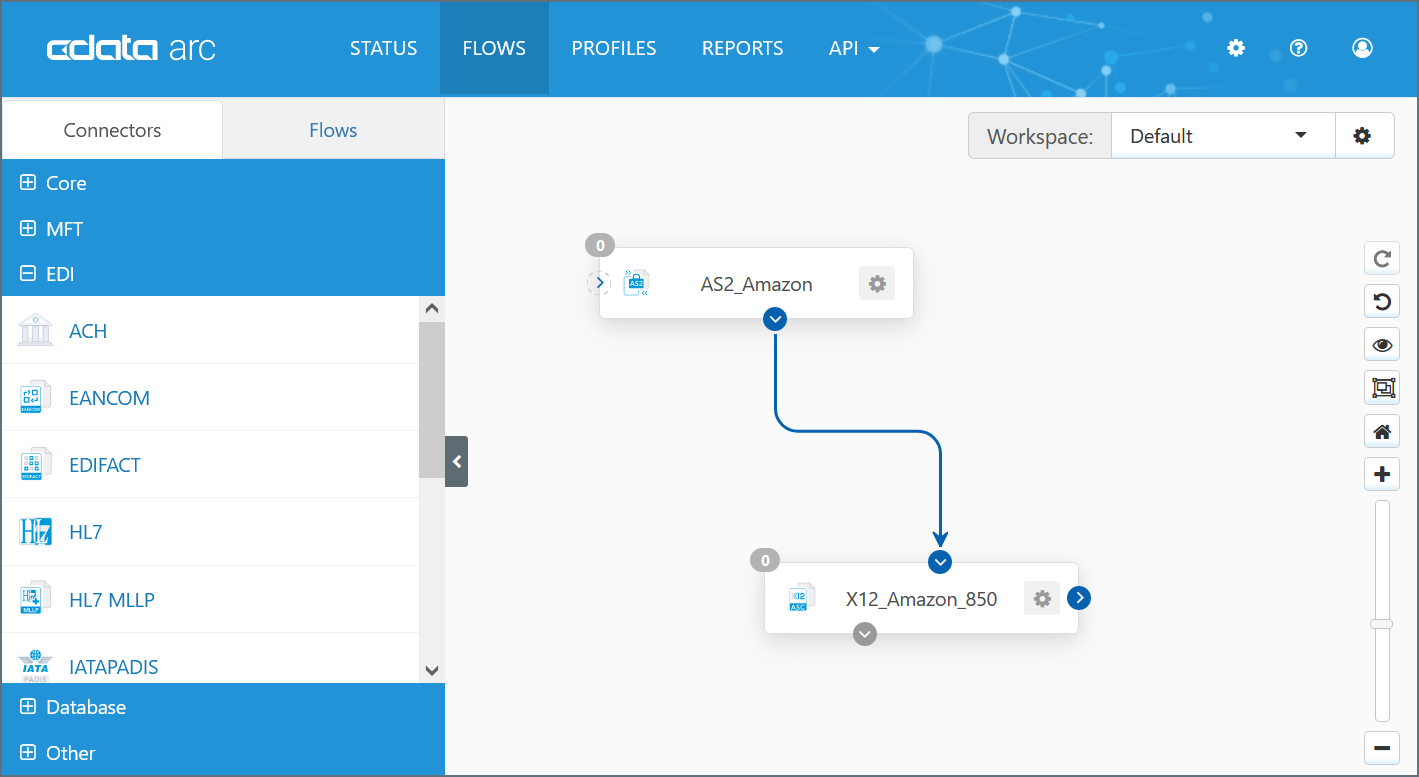
The blue arrow between the two Connectors indicates that data received by the AS2 Connector will automatically be passed along to the X12 Connector. Dragging the blue dot on the right side of any Connector onto the left side of any other Connector will establish this relationship.
The series of Connectors in a Flow establishes a logical chain of data processing, so Flows should be designed to accomplish a specific business task. These tasks can vary in complexity from simply downloading a file all the way to synchronizing multiple back-end applications in accordance with received business documents.
Multiple Flows can be configured within Arc to accomplish separate tasks. Flows will act independently of each other unless they are explicitly connected to each other via a blue flow arrow.
More information on Flows can be found in our dedicated Flows section.
Connectors
Connectors are the individual building blocks of a Flow, operating on application data, or Messages. Each Connector performs a specific operation on a Message and passes it along to the next Connector in the Flow, or to an outside party (e.g. to an FTP destination).
Operations fall primarily into three categories:
- Receiving data (from transferred files, database output, etc)
- Processing/Transforming data (translating data between formats, mapping data into a new structure, etc)
- Transmitting data (sending/uploading files, inserting data into databases, etc)
Each time a Connector performs one of the above operations it is processing a Transaction.
In the Flows page, dragging a Connector from the toolbox on the left into the canvas creates an instance of the Connector. Clicking on a Connector in the Flow brings up the configuration settings panel:

Connectors have a different set of configuration settings based on what type of Connector it is (e.g. AS2, SQL Server, XML, etc).
Some Connectors, like the AS2 Connector, SFTP Connector, etc, either receive data from an external party/server or send data out to an external party/server (or both). These Connectors are typically at the start or the end of a Flow, since that’s where data enters or exits the application.
Other Connectors, like the XML Map Connector, X12 Connector, etc, process data locally within the application. These Connectors are typically in the middle of configured Arc Flows, since they can only receive data from other Connectors (not from an external source) and can only send data to other Connectors (not to an external destination).
More information on Connectors can be found in our dedicated Connectors section.
Messages
When data is passed between Connectors in a Flow, it is passed in the form of a Message. Messages consist primarily of file payload data (the data that Arc is processing) and metadata (information that Arc uses to track the flow of data through the application).
Messages are explained in more detail in the Message Implementation section, but the high-level takeaway is that Messages are files in standard RFC822 (Internet Message) format. When a Connector passes data to another Connector in the Flow, it writes the data to a file and then passes that file to the next Connector down the line.
At each step in a Flow, a Message (file) is either received/downloaded into the application, transformed locally (within the application), or uploaded/sent out of the application. Each of these operations is referred to as a Transaction.
Arc is transparent; you can observe what happens inside the platform by looking at the file system, seeing how messages are copied from one folder to another, and looking at the message content using a regular text editor or other tool.
Basic Message Structure
Basic messages have two parts: (1) a set of name-value pairs as headers, and (2) the message payload. Together, this message format is stored in a ‘.eml’ file type that can be opened by any standard text editor or email client.
Message Headers
Message headers help Arc track the progress of data through the application. Headers include a unique Message ID (which helps Arc know the full lifecycle of a message, even if the filename is changed), timestamps from when connectors processed the message, any errors that might have occurred during processing, and other metadata.
Headers are listed in headerName: headerValue syntax at the top of the message, delimited by line breaks. Clicking on a message within Arc (e.g. within the Input our Output tab of a connector panel) will show the headers associated with the message, and allow for downloading the file content of the message.
Messages are also used for miscellaneous values that are helpful for Arc to know within a flow. For example, when downloading files from a subfolder on a remote FTP server, Arc uses a header to track the folder path to the message in case this folder path needs to be recreated on the local system.
Message Payload
The message payload is the actual file data being processed by the application. This is the data that is received/downloaded from a remote source, manipulated by transformation connectors, etc. While the message headers are primarily used by Arc for tracking messages, the message payload contains the data that users care primarily about.
Message payloads are separated from message headers by two line breaks. Opening an Arc message in a text editor or email client will display the message payload in plain text.
Messages Within a Flow
While Arc internally uses message headers for tracking and understanding the data processed by the application, it hides these details from users unless the message is inspected. For example, Arc uses an internal Message ID to identify a message, but will display a public filename in Input/Output tabs, transaction logs, etc.
To examine the headers on a message, simply click on the displayed filename to view further message information.
Message headers are added to files as soon as the first connector processes the file. Message headers are stripped from the message at the end of the flow (after the last connector in the flow has processed the message). In other words, message headers and the ‘.eml’ format is only relevant while file data is in the midst of being processed in an Arc flow.
Message Logs
Whenever a message is processed by a connector, Arc generates a transaction log for that processing. These logs can be accessed via the Transaction Log in the Status page, or by clicking on a message filename within a connector panel and selecting Download Logs.
Batch Groups and Batch Messages
Messages can contain multiple payloads, in which case they are considered “batch groups.” Each individual payload within a batch group is considered a “batch message.”
Batch Groups
Batch groups are MIME-format files where each MIME part is a separate batch message. The batch group maintains metadata about the batch using the same header scheme that basic messages use. These headers track the processing of the batch as a whole, rather than individual parts of the batch.
Batch Messages
Each batch message within a batch group is a MIME part containing the file payload data processed by the application. Each batch message contains metadata associated with the payload (but not the batch group) within the MIME part. Thus, batch messages have multiple sets of metadata: one set of headers for tracking the batch group as a whole, and a separate set of headers for each individual MIME part (each batch message) within the batch.
Implementation Overview
This section provides technical details about Arc implementation of the above core concepts (Messages, Connectors, Flows), together with explanations as to why we think our implementation satisfies our Design Principles.
File-Based Architecture
Arc stores all data in files on the filesystem, so everything in the application persists to disk:
- Application Data (Messages)
- Configuration Data (Profiles and Flows)
- Logs, etc.
Connectors in a configured Flow read files (messages) from a single Input folder and write files (messages) to a single Output folder. When data passes from one Connector to the next, these message files are moved from the Output folder of the first Connector into the Input folder of the next Connector.
Arc provides a web UI on top of this filesystem-based infrastructure to easily construct and configure Flows. However, with an understanding of the folder structure and file conventions used in the application (as described in the following sections), Arc’s flows can also be configured by manipulating the filesystem directly. Arc utilizes a hierarchical folder structure to organize the application’s files. This is described in in the Folder Hierarchy section.
Message Implementation
Messages in Arc are simple files on disk that contain the raw data processed by the application. Messages have two parts:
- Body - the application data payload
- Headers - message metadata
The combination of headers and body is stored in RFC2822-compliant files with an .eml extension. The headers are a simple list of name: value headers separated by newline characters, and the body is separated from the headers by two newline characters.
Body
When data is received, Arc generates a message (i.e. writes a new message file to disk) and uses the incoming data as the body of the message. For example, when an SFTP Connector downloads a file from a remote server, the contents of that remote file becomes the body of a new Message.
When data is processed locally within the application (e.g. when EDI is translated into XML, or when a file is mapped into a new format), the Connector performing the operation reads the body of the input Message, processes the data in memory, and writes the results into the body of an output Message.
When data leaves the application (e.g. when uploading a file to a remote server, sending a file to a peer, or inserting into a database), only the body of the input message is sent out.
Headers
Arc augments the raw data files with metadata that describe how the application has processed the file. These are some of the most common headers:
- A unique, durable MessageId that identifies the file throughout the Flow
- Timestamps of the file being processed
- The Connector IDs for any Connectors that processed the file
- Any instance of the file failing to process due to an error
Message headers are never edited or overwritten by the application. New headers are always appended to the existing list so that the full processing history is preserved.
Batch Groups
Messages can be batched together to improve performance and make large groups of messages more manageable. Multiple messages batched together are called “Batch Groups.” Batch groups are MIME-format files where each MIME part is a separate batch message. The batch group maintains metadata about the batch using the same header scheme that basic messages use. These headers track the processing of the batch as a whole, rather than individual parts of the batch.
Batch Messages
Each batch message within a batch group is a MIME part containing the file payload data processed by the application. Each batch message contains metadata associated with the payload (but not the batch group) within the MIME part. Thus, batch messages have multiple sets of metadata: one set of headers for tracking the batch group as a whole, and a separate set of headers for each individual MIME part (each batch message) within the batch.
Accessing and Viewing Messages
Since messages are just simple files on disk, users and external systems can access and view messages currently in the Arc pipeline. Accessing messages with an external application merely requires understanding where on the filesystem to look for the message .eml files. The exact location of these message files is described in the Folder Hierarchy section.
Messages are also made available through the Arc web UI as well as the Arc REST API. Messages are displayed in the Input tab or Output tab for any Connector that has processed a message, as well as the Transaction Log on the Status page. Clicking on a filename within any of these three interfaces brings up the Message Info modal:

The values displayed in this panel are the message’s headers. The body of the message can be accessed by clicking the Download button. The logs associated with a message (as described in the Message Log Folders section) can be downloaded via the Download Logs button.
Message Tracking and Logs
Messages include a MessageId header that functions as a unique identifier for messages. This MessageId remains the same as the file passes through the Flow, even if the file itself is renamed. As a result, the progress of any file throughout a Flow can be traced by referencing its MessageId. This value also allows users to find log data associated with a particular Transaction.
Arc stores log data in two formats:
- Application Database
- Verbose log files on disk
Both of these formats and the relationship between the two are detailed below.
Application Database
The Application Database is a relational database that Arc uses in several ways:
- Store metadata about each Transaction processed by the application
- Store logs for application operations that are not specific to any transaction
- Store the state of certain Connectors (e.g. when a Connector is awaiting an acknowledgment or receipt)
Arc comes packaged with a default SQLite (Windows/.NET) or Derby (Java) database, but can be configured to use an external database like SQL Server, PostgreSQL, or MySQL instead. Arc handles the creation and maintenance of all relevant tables within the Application Database.
The Transaction Log is the table within the Application Database that is used to track Messages and find logs for a particular Transaction. This table stores metadata for each Transaction processed by the application, and the metadata includes the MessageId of the Message that was processed. The Status page of the web UI provides a browser for navigating the Transaction Log and other tables in the database.
The Transaction Log is searchable by transaction metadata (e.g. timestamp, filename, ConnectorId, etc). To minimize the database footprint, verbose logging data is not included in the Transaction Log and is instead stored in log files on disk.
Verbose Log Files
Each time Arc processes a message, it generates a log folder with the same name as the MessageId. This folder contains the verbose log files, and the specific logging content depends upon the type of Connector that sent and/or received the file. For example, the AS2 Connector logs the MDN receipt, raw request and response, and connection log in addition to the .eml file representing the message itself.
These log files are not necessary for merely tracking a Message through the Flow; the metadata stored in the Application Database is enough to track a Message. However, to find detailed information on a specific transaction (especially when debugging), it is necessary to find the appropriate files on disk based on the MessageId of the Message and the Connector that processed it.
Naturally, users can manually navigate to the appropriate log folder on disk once they know the MessageId, however it is often more convenient to use the Application Database to find these verbose log files, as explained below.
Relationship Between Application Database and Log Files
The metadata stored in the Application Database includes everything that is required to find the log files associated with a particular Transaction. The Arc web UI and REST API take advantage of this relationship to provide easy access to the log files for any Transaction.
The Status page includes the Transaction Log table, which contains Transaction metadata. Any of these Transaction entries can be expanded to show the log files associated with that transaction; underneath, Arc is using the MessageId to find the appropriate log files on disk.
Similarly, the Input and Output tabs within the Connector Settings panel provide access to any Transaction processed by that specific Connector. These entries can also be expanded to view and download verbose log files for the Transactions.
The Application Database can also be helpful for manually navigating to the appropriate folder where Transaction log files are held. Often, a user will know the filename (or timestamp, etc) of a Transaction but not the internal MessageId. The Transaction Log is searchable, so searching for a specific filename will bring up the MessageId for any Transactions associated with that filename. The Folder Hierarchy section contains more information on where the log folders can be found once the MessageId and Connector are known.
Design Decisions Behind Message Implementation
We want application data to remain transparent to users and external systems, so our Messages are passed via simple data files on the filesystem rather than an opaque internal data channel. As a result, Arc is not a black box where data is hidden away during processing. Arc can effectively be embedded into any system that picks up files or drops off files into specified folders on the filesystem.
We also want Messages to be accessible without specialized tools or programs. Messages are stored in RFC2822-compliant files so that any common text editor can easily open the file. The .eml extension is used so that double-clicking on the file will cause the system’s default email client to open the Message and display the contents.
In order for messages and logs to be accessible and transparent, we provide a searchable database of transaction metadata. This database can be used to access the message payload and verbose log files directly, while maintaining a light database footprint.
Connector Implementation
Connectors represent a single step in a configured Flow. Complex Flows are created by connecting arbitrary sets of Connectors together to perform a logical chain of data processing.
There are three types of operations a Connector can perform:
- Receive data and write an output message (e.g. download a remote file over SFTP)
- Read an input message and send the data to an external party (e.g. send a file over AS2)
- Read an input message, process it locally, and write an output message (e.g. translate an EDI file into XML)
Most Connectors can either perform the first two operations (send and receive data to/from remote endpoints) or perform the last operation (transform data locally). Every operation performed by a Connector is referred to as a Transaction.
All Connectors read input messages from a single Input folder, and write output messages to a single Output folder. When Connectors are connected in the Flow, Arc will automatically move messages from the Output folder of the first Connector to the Input folder for the next Connector.
Connector Files and Folders
Every instance of a Connector exists on disk as a single folder that is named the same as the ConnectorId (the display name in the Flow). Each Connector folder contains the following:
- A port.cfg file containing configuration settings
- Messages to send/process (i.e. input messages) within the ‘Send’ subfolder
- Received messages (i.e. output messages) within the ‘Receive’ subfolder
- Log files for messages processed by the Connector
- Connector-specific files like Maps, Templates, and Scripts
This section explains how these folder contents function in the application, and the Folder Hierarchy section explains the exact location of Connector folders and subfolder hierarchy within.
Port.cfg
Each Connector’s port.cfg file contains the settings that govern the Connector’s behavior (i.e. the settings that appear in the Settings and Advanced tabs of the Connector UI). This file is in INI format: Connector settings are listed in SettingName = SettingValue syntax, one-setting-per-line.
The port.cfg file supports indirect values, or setting a field using a reference instead of a string literal. This is conceptually similar to setting a variable in another section of the application, and referencing the variable name in the port.cfg file. Details on setting indirect values can be found in the settings.json subsection of the Data Directory section.
Editing Connector settings within the application UI is functionally equivalent to editing the settings directly in the port.cfg file.
Input Messages
The ‘Send’ folder holds input messages, or messages that are queued to be processed by the Connector.
At every clock tick (half a second by default), Arc checks for changes in each Connector’s Send folder and dispatches worker threads to any Connector with available messages. When a message is processed, Arc appends a header to that message with the timestamp of the processing attempt.
Arc sorts the input messages according to the last modified time so that older files are processed first. Since Arc appends a header during each attempt, this ensures that messages that cause an error do not block the Connector unnecessarily through repeated retries.
Note that Connectors must have Send automation enabled in order to process input messages every clock tick.
Output Messages
The ‘Receive’ folder holds output messages, or messages that have been received/downloaded/processed by the Connector.
Some Connectors write an output message as soon as they have finished processing an input message (e.g. Connectors that translate data formats). Other Connectors write an output message without first reading an input message, such as an SFTP Connector that polls a remote server for files to download, or an AS2 Connector that passively listens for incoming files.
When a Connector is connected to another Connector in the Flow, output messages do not remain in the Receive folder and are instead passed along to the Send folder for the next Connector.
Log Files
Each transaction processed by a Connector generates a set of log files. Metadata about the transaction is added to the Transaction Log, and the verbose logging information is stored as files on disk. The log files always include the message itself in .eml format along with any Connector-specific log files.
By default, log files are organized in the following folder structure:
├── Logs
├── Sent
├── MessageId_1
├── MessageId_2
├── Received
├── MessageId_3
├── MessageId_4
In other words, log files are all held in a folder named the same as the MessageId for the message that was processed, in either the ‘Sent’ or ‘Received’ folder within the parent ‘Logs’ folder.
Logs can be further organized by grouping together log folders based on the time they were generated. The LogSubfolderScheme field of any connector can be set to a time interval (e.g Weekly) to group logs together within that interval (e.g. all logs generated in the same week are held in then same subfolder). This may improve disk I/O performance by reducing the size of any individual subfolder.
It may be necessary to use the Transaction Log to find the appropriate log folder, either by determining the MessageId or by using the Download Logs function in the application UI.
Sent Files
In addition to verbose log files, the Connector maintains a copy of all sent/processed messages in the ‘Sent’ folder; note that this ‘Sent’ folder is a direct child of the Connector folder, rather than the ‘Sent’ folder within the ‘Logs’ folder from the previous section.
Files in the ‘Sent’ folder contain only the data payload of messages that have been successfully sent. Messages that cause an error instead of successfully processing are not added to the ‘Sent’ folder.
Sent files can be further organized by grouping them together based on the time they were generated. The SentFolderScheme field can be set to a time interval (e.g Weekly) to group files together within that interval (e.g. all files sent in the same week are held in then same subfolder). This may improve disk I/O performance by reducing the size of any individual subfolder.
Additional Configuration Files
Depending on the Connector type, some Connector folders will include additional configuration files. These additional files include:
- map.json
- script.rsb
- template XML files
These files store mapping relationships, custom scripting behavior, and the structure of connector input and output. Editing these files on disk is equivalent to editing the associated Connector settings within the application UI.
Design Decisions Behind Connector Implementation
We want Flows to be fully modular, and that means that each Connector should provide a straightforward function in a predictable and intuitive way. Arc’s capacity to perform complex tasks comes from the ability to combine arbitrary sets of Connectors, while the Connector interfaces remain simple. Sophisticated Flows remain easy to understand by breaking down the Connector chain into discrete steps.
We want all of the data relevant to a Connector (configuration data, application data, logging data, etc) to be easy to access. Since all of this data is housed in a Connector-specific folder, accessing the data is a simple matter of knowing where to find the folder. Configuration data is stored in the transparent INI format so that it, like Message data, can be easily viewed and edited with simple tools.
Our folder-based approach to Connectors also makes it easy to understand how data is passed between Connectors: a simple file-move operation on the Message files turns one Connector’s output into another Connector’s input. Arc includes built-in tools to establish these file-move relationships automatically, but the same result could be accomplished by manipulating the filesystem directly.
Flows and Workspaces Implementation
Flows are represented on the filesystem in a flow.json file containing the position and connections for each Connector in the Flow. The location of this file is specified in the Folder Hierarchy section below.
The position of Connectors in the Flow is purely cosmetic and only used when configuring Flows within the application UI. The connections between Connectors are relevant at the data processing level: after each Connector has written an output Message it will query the application engine to see if it needs to pass the output Message along to another Connector’s Input folder. The application uses the flow.json file to determine which Connector, if any, is given the file.
Multiple Flows can be configured in the same Flows canvas, and the Arc UI allows for dragging the canvas around to navigate between Flows. This is similar to navigating geographical maps online, e.g. looking at road maps in Google Maps.
Workspaces provide a logical separation between Flows. Each Workspace provides a fresh canvas within which to configure Connectors into logical Flows. Extending the Google Maps analogy, Workspaces function as entirely separate ‘planets’.
Deciding whether to configure new Flows on separate Workspaces or within the same Workspace is a matter of preference.
Workspaces on the Filesystem
Introducing new (non-default) Workspaces adds a new set of folders in the Arc folder hierarchy. The workspaces directory contains the Connector folders for all Connectors configured in non-default workspaces. This workspaces folder is a sibling of the data directory described in the next section.
Design Decisions Behind Flows and Workspaces
We think that the best way to preserve the simple and modular relationship between individual Connectors in the Flow is to treat Flows as a purely logical concept. All of the information necessary to determine the logical series of data processing is already contained in the Connector implementation.
We want Workspaces to provide the ability to separate Connectors on a more substantial level. Separate Workspaces are given separate folders to house Connectors so that filesystem-level operations (e.g. permissions, directory listings) can be easily isolated to a particular Workspace.
Folder Hierarchy
Since all Arc resources are available on the filesystem, understanding Arc at a low level requires learning the application’s folder structure. This section describes how files and folders are organized on disk.
In order to best understand the hierarchy, it is helpful to see the directory view of an Arc installation. The text below provides a visual representation of the folder structure, and the details of this structure are explained in the following subsections.
├── Arc
├── data
├── AS2_Amazon
├── Archive
├── Logs
├── Pending
├── Receive
├── Send
├── Sent
├── Database_MySQL
├── Archive
├── Logs
├── Receive
├── Send
├── Sent
├── Templates
Note that this hierarchy assumes that Flows are only configured in the default Workspace. Additional Workspaces are explained in the Flows and Workspaces section.
Root Installation Directory
All Arc resources are contained in the installation directory, which are the following default locations:
- Windows:
C:\Program Files\CData\CData Arc - Linux/:
/opt/arc
For Java installations, CData provides a setup.zip file that you can extract to the installation directory of your choice (for example, /opt/arc).
When the Java edition of Arc is hosted on an external Java servlet, like Tomcat, Arc resources reside here:
~/cdata/arc
In this path, ‘~’ resolves to the home directory of the user that hosts the Java servlet.
In the folder hierarchy that is shown in the previous section, the root installation directory is the Arc folder at the top of the tree.
Data Directory
The data directory has the following contents:
- A subfolder for each Connector configured in the Flows page (in the default workspace)
- A profile.cfg file
- A flow.json file
- A settings.json file
- All certificate files
Profile.cfg
The profile.cfg file contains application-wide settings such as those for configured local profiles (e.g. the AS2 Profile). This file is in INI format: application settings are listed in SettingName = SettingValue syntax, one-setting-per-line.
The profile.cfg settings are divided into sections: an Application section for general application sections, and a dedicated section for each Profile (e.g. an AS2 section for the AS2 Profile, an SFTPServer section for the local SFTP Server settings, etc).
Editing application settings within the Profile page of the application UI is functionally equivalent to editing the settings directly in the profile.cfg file.
Flow.json
The flow.json file contains the structure of configured Flows: the positions and connections between each Connector instance. Editing the flow.json file directly accomplishes the same thing as moving or re-connecting Connectors in the Flows page.
Settings.json
The settings.json file contains a list of settings that can be referenced elsewhere in the application by using a reference names instead values. This enables you to store secure values (like passwords) in a way that does not display them in the application. You can also use reference names to centralize the configuration of Flows that are deployed across multiple instances.
Settings that support this centralized reference syntax will have a key icon in the web UI, which can be clicked to view a list of defined references in the settings.json file. For more information about this feature, see Global Settings Vault.
Certificates
All certificates created or uploaded in the application are stored in the data directory. Typically, certificates come in public/private pairs with the same filename but different file extensions: .pfx for private and .cer for public. Certificates in other formats uploaded within the application will be stored as-is.
Arc will enumerate the certificates in the data directory to determine the options available when configuring a certificate in the UI via a dropdown menu. Dropping a certificate file directly in the data directory accomplishes the same thing as uploading a certificate in the application.
Connector Folders
Each configured Connector instance has a dedicated folder within the data directory. The names of these folders are the same as the ConnectorID value (i.e. the display name) for each Connector in the Flow. In the above image, the two configured Connectors in the Flow are ‘AS2_Amazon’ and ‘Database_MySQL’.
The contents of the Connector folder is explained in the Connectors on the Filesystem section, and the following serves as an overview of the subfolder structure within the Connector folder:
- Send (Input) - Messages that the Connector should send/process are read from this folder
- Receive (Output) - Messages that the Connector has received/processed are written to this folder
- Sent - A copy of successfully processed messages (in raw data file format) are written to this folder
- Logs - Verbose log files for each message processed by the Connector
- Sent - Logs for messages that were sent by the Connector; each message has its own folder named by the MessageId
- Received - Logs for messages that were received by the Connector; each message has its own folder named by the MessageId
- Archive - Older log files are compressed and moved to this folder
Some Connectors may have other subfolders, depending on the Connector type:
- Pending - Messages that have been processed but are pending an acknowledgement from another party
- Templates - XML representations of Connector input and output data
- Public - Files that should be published as public endpoints in the application are placed here
- Schemas - Schema files (like EDI schemas) that are specific to a particular Connector are placed here
Design Decisions Behind the Folder Hierarchy
Since we want the data in Arc to be transparent and accessible, the location of specific files within the application should be easy to find. A simple hierarchical folder structure helps ensure that users and external systems know where to look for the Arc data files.
We want the Arc UI to provide a convenient interface for configuring and using the application, but we also want the application to remain fully embeddable within other solutions. Understanding the Arc folder structure is all that is required to point these other solutions to any relevant Arc data.
Automation
The Arc automation service processes files in the Input folder for each Connector. The automation service runs on a half-second ‘clock tick’, and messages move one step further through the Flow at each tick.
Arc supports Parallel Processing by distributing multiple threads to each Connector, and each thread can process multiple files within that Connector. The specific numbers of workers distributed and files processed per-worker are determined by performance settings in the Profile and in the specific Connector settings.
Clock Ticks
At a predefined interval (500 milliseconds by default), Arc checks the contents of the Input folder for every configured Connector, and if new files are found, the application assigns worker threads to process them according to the Connector’s settings.
The application does not provide any guarantees about which Connector’s Input is enumerated first. When there are multiple files within a single Connector’s Input folder, those files are processed in order according to the last modified time (files modified least recently are processed first).
When Arc attempts to process a file, it adds a message header with the processing timestamp, and this changes the last modified time for the file. This means that if a file fails to process (causes an error), it becomes the lowest priority file compared to the rest of the files in the Input folder. This prevents a single file from blocking the operation of a Connector by repeatedly throwing an error and immediately being retried.
Parallel Processing
When Parallel Processing is enabled, Arc can distribute multiple worker threads to the same Connector during a single clock tick. The number and behavior of these workers are determined by three settings in the Advanced tab of the Settings page (some of which can be overridden for individual Connectors within that Connector’s Advanced settings tab):
- Worker Pool
- Max Workers per Connector
- Max Files per Connector
Threads are distributed to Connectors in round-robin fashion, so adjusting these values (either globally or for specific Connectors) can help alleviate throughput problems or prevent some Connectors from hogging system resources.
The Worker Pool establishes the global maximum number of threads that the application can assign to all Connectors (combined) at the same time. When a thread finishes its assignment within a specific Connector, it is recycled back into the pool. The hardware resources available on the host machine determine the upper limit for this setting.
Max Workers per Connector establishes the maximum number of threads assigned to a single Connector at the same time. Each thread assigned to a Connector processes files in that Connector’s Input folder one-at-a-time until the folder is empty (or until the Max File per Connector is reached, as explained below). Once this condition is reached, threads assigned to the Connector are recycled back into the worker pool as they finish processing. This setting can be overridden for specific Connectors within that Connector’s Advanced settings.
Max Files per Connector establishes a limit on the number of files processed in a single Connector within a single clock tick. For example, if this setting is set to 5, then threads assigned to a Connector will be recycled back into the worker pool after they have (collectively) processed 5 files, even if there are still files left in that Connector’s Input folder. This setting can be overridden for specific Connectors within that Connector’s Advanced settings.
Maximizing Performance
The Max Workers per Connector and Max Files per Connector settings can be adjusted within individual connectors to help maximize Arc performance when certain Connectors require more or less resources than others.
Increasing the Max Workers per Connector for a particular Connector tells the application to assign more system resources when processing that Connector’s input files. This is useful when a particular Connector acts as a bottleneck for Flow throughput. However, since threads are assigned in round-robin fashion, increasing this setting for many different Connectors may cause the application to run out of threads in the Worker Pool. In this case, the application must wait for other threads to finish and be recycled before it can assign them to the remaining Connectors.
Decreasing the Max Workers per Connector for a particular Connector prevents that Connector from severely depleting the worker pool when processing files. This may help avoid issues where the application runs out of threads to distribute during round-robin assignment. However, if the Connector’s Input folder has many files, it may take a long time for the smaller number of threads to finish processing the files and be recycled back into the pool (unless the Max Files per Connector is also adjusted, as discussed below).
Increasing the Max Files per Connector for a particular Connector helps ensure that files do not sit in that Connector’s Input folder for multiple clock ticks. This may help increase throughput for high-volume Connectors, however, it may also increase the chance that threads assigned to the Connector are not recycled back into the worker pool for a long time (and thus cause a thread shortage).
Decreasing the Max Files per Connector for a particular Connector helps ensure that threads assigned to that Connector are recycled back into the pool in a timely manner. However, it may mean that files are not always processed within a single clock tick if the number of files in the Input folder exceeds the maximum processed per-tick.
Performance maximization is specific to the particular environment and use case. In general, Connectors that need to process/send a large number of files should be assigned more workers and those workers should be allowed to process more files before recycling. To prevent the thread pool from being exhausted, other Connectors should be assigned fewer workers and those workers should be limited to fewer files.
Receive Automation
Within Arc, the automated processing of Input files described above is called ‘Send’ automation. Arc also supports ‘Receive’ automation, which describes the automated process of Connectors pulling files into the Arc Flow according to a scheduled interval.
Receive operations fall into two categories:
- Downloading files from a remote host/server (FTP, SFTP, S3, etc)
- Pulling data from a back-end system (database, ERP system, CRM, etc) and writing it out as XML
Receive automation is always tied to a scheduling interval that determines how often the Connector attempts to download files or pull data from an external system.
Every clock tick, the automation service checks to see if any Connector’s Receive Interval has elapsed. Any such Connector immediately establishes an outbound connection and pulls data according to the Connector’s settings.
Some Connectors, like the AS2 Connector, passively listen for incoming data to Receive. These Connectors do not support Receive automation since they cannot actively poll an external system for data.
Putting This Document to Use
Getting started in Arc does not require a full understanding of the underlying architecture. However, peeling back the layers of the application does provide an important set of benefits:
- Evaluate whether the Arc approach fits more specific technical requirements
- Manipulate and configure the application with greater understanding and control
- Understand how to embed Arc as part of a larger data-processing solution
Evaluate CData Arc Technical Characteristics
Arc is a lightweight implementation of a message-driven integration framework. An understanding of it’s underpinnings can help engineers know whether this approach is suitable for their specific business needs.
After reading this document, we hope the principles guiding our design decisions are clear, since these principles will continue to shape the growth and development of the application. Understanding the “why” behind an application’s design helps users make an informed decision about whether it is right for them.
Manipulate CData Arc With Confidence
The Arc web UI provides an accessible interface for manipulating and configuring the application. A better understanding of the underlying architecture helps users perform more advanced work “under the hood,” for example:
- Creating scripted management procedures that modify Arc files and folders directly
- Adding Arc files and folders to a versioning system to maintain backups and snapshots
- Setting permissions on specific folders for granular control over user access
In addition, we believe that a conceptual grasp of Flows, Connectors, and their relationship with application data can help users quickly and easily configure optimal workflows. We prioritize the ability for users to take advantage of the Arc feature set with minimal configuration overhead.
Embed CData Arc Within a Larger Solution
Once a user knows the Arc folder structure, the process of embedding Arc within another data processing system is simple. Since Arc interfaces with the system through a set of well-defined folders on disk, any other application that reads and writes from specified folders can seamlessly pass data to and from Arc.
Feel Comfortable with CData Arc
Finally, we think that engineers have a common desire to understand the mechanisms underlying the systems that they use. Even if none of the benefits listed above are applicable to your particular circumstance, we hope that this document has provided you with an additional layer of comfort and familiarity when using Arc to build your own data integration workflows.