Features
Version 23.4.8843
Version 23.4.8843
Features
CData Sync offers powerful features that help you replicate any data source to any database, data warehouse, and more. The following features are briefly explained in this document:
-
Incremental replication
-
Sync intervals (data integrity)
-
Deletion captures (data and records)
-
Data types
-
Data transformations
-
API access
-
Firewall traversal
-
Schema changes
Initial Replication
The first time that you run a job, CData Sync processes the entirety of the source’s historical data. This data can encompass a huge amount of information. Therefore, Sync uses several strategies to maximize efficiency, performance, and integrity. Sync also provides user-controlled options that you can use to optimize the synchronization strategy for your specific data set.
You can control how Sync processes an initial replication by using the following options. (These options are available on the Advanced tab, under the Job Settings category that is displayed when you open a job.)
-
Replicate Start Value: Sync begins replicating data from the source’s minimum date or minimum integer value of the auto-increment column (that is, from the source’s earliest available records). Some APIs do not provide a way to request the minimum date or int value for an entity. If no minimum value is available, you can configure it manually by following these steps:
-
Under Job Settings, click the Tables tab. Then, click the table that is displayed on that tab to open the Task Settings modal.
-
Click the Advanced tab in the modal.
-
Locate the Replicate Start Value option. Manually set the minimum start date/int value by adding a date in either of these forms: yyyy-mm-dd or yyyy-mm-dd hh:mm:ss.
If you do not specify a start date, Sync executes a query on the source that obtains every record in one request. However, this process can cause problems when your source table is very large because any error causes Sync to rerun the query from the beginning of the data.
-
-
Replicate Intervals: After Sync determines the minimum start date, the application moves the remainder of your data by an interval that you define until it reaches the end of the data. You define the intervals with these options, which are also available on the Advanced tab of the Job Settings page):
-
Replicate Interval: Paired with Replicate Interval Unit, this option enables you to set the time interval at which to split the data during data retrieval. Sync uses this interval to batch the updates so that if a failure occurs or the replication is interrupted, the next attempt can start where the last run ended. By default, Sync uses an interval of 180 days. However, you can adjust this interval larger or smaller, depending on the amount of data that you have and how dispersed the data is in terms of time.
-
Replicate Interval Unit: Paired with Replicate Interval, this option enables you to set the time interval at which to split the data during data retrieval. Accepted values for this option are minutes, hours, days, weeks, months, years.
-
Incremental Replication
After the initial replication, CData Sync moves data via incremental replication. Instead of querying the entirety of your data each time, Sync queries only for data that is added or changed since the last job run. Then, Sync merges that data into your data warehouse. This feature greatly reduces the workload, and it minimizes bandwidth use and latency of synchronization, especially when you are working with large data sets.
Many cloud systems use APIs, and pulling full data from those APIs into a data warehouse is often a slow process. In addition, many APIs use daily quotas where you cannot pull all the data daily even if you wanted to, much less every hour or every fifteen minutes. By moving data in increments, Sync gives you tremendous flexibility when you are dealing with slow APIs or daily quotas.
Sync pulls incremental replications by using two main methods–an incremental check column and change data capture. These methods are explained in the following sections.
Incremental Check Column
An incremental check column is either a datetime or integer-based column that Sync uses to identify new or modified records when it is replicating data. Each time that a record is added or updated in the source, the value for this column is increased. Sync uses this column as a criterion during the extraction to ensure that only new or changed records are returned. Then, Sync stores the new maximum value of the column so it can be used in the next replication.
Replication that is done by using an incremental check column can work by using two different data types:
-
DateTime incremental check columns: A Last Modified or a Date Updated column that represents when the record was last updated.
-
Integer-based incremental check columns: An auto-incrementing Id or a rowversion type that increments each time a record is added or updated.
Change Data Capture
Some sources support change data capture (CDC), where a source uses a log file to log events (Insert, Update, or Delete) that cause changes in the database. Rather than querying the source table for changes, Sync reads the log file for any change events. Then, the application extracts those changes for replication and stores the current log position for the next replication.
The sources listed below support CDC capability:
-
MariaDB - Uses binary logs.
-
MySQL - Uses binary logs.
-
Oracle - Uses Oracle Flashback or Oracle LogMiner.
-
PostgreSQL - Uses logical replication.
-
SQL Server - Uses either change tracking or change data capture.
Parallel Processing
You can configure CData Sync jobs to use parallel processing, which means that the application uses multiple worker threads to process one job. With parallel processing, Sync can divide its workload into multiple processes, allowing it to move more than one table simultaneously. As a result, more data is moved in less time, greatly increasing job efficiency. With Sync, you can assign as many workers as you want, on a per-job basis.
To enable parallel processing:
-
Click the job that you want to run (from the Jobs page in Sync). This action opens the Jobs/YourJobName page.
-
Click the Advanced tab under the Job Settings category.
-
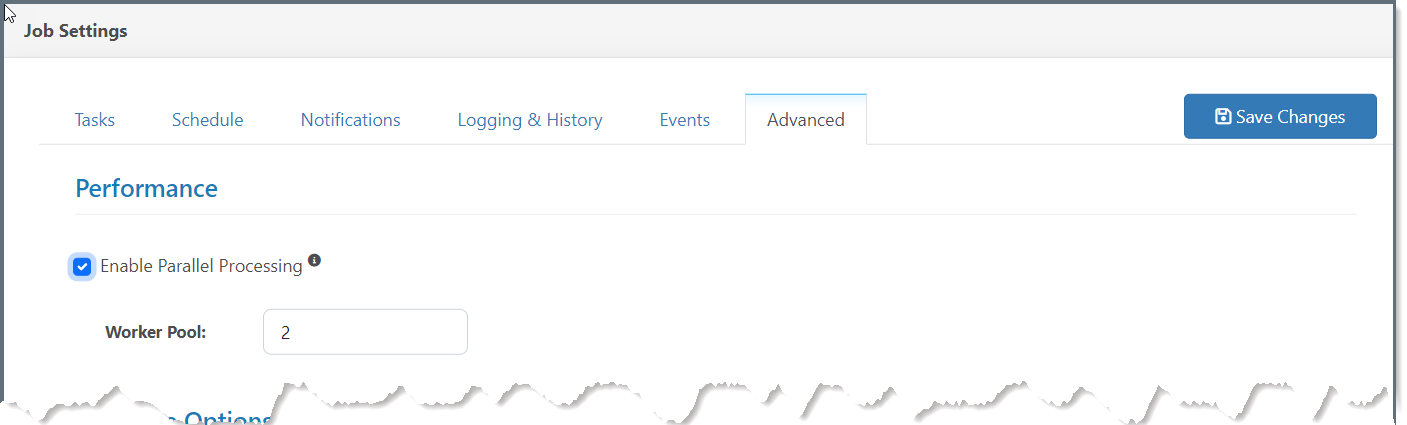
Select Enable Parallel Processing.
-
Enter the number of workers that you want to assign to the job in the Worker Pool field. This value controls how many tasks can run in parallel at one time.
-
Click Save Changes (upper right of the Job Settings header bar).
After you save these changes, your job will use parallel processing when you run it.
Sync Intervals (Data Integrity)
As part of any data-integration strategy, it is important to ensure that data is consistent between the original source and the destination. If an error occurs in your data pipeline, or if a job is interrupted, you need your data pipeline process to resume where it stops. This behavior ensures that no data is lost between updates or in the event of an error. CData Sync automatically manages that action for you without the need to configure complex data-loading scripts or processes.
Sync processes data in sync intervals. This means that, rather than attempting to move all of your data at once, Sync breaks the data into manageable intervals (or “chunks” of data) and processes one interval at a time. This feature greatly increases performance, and it enables Sync to maintain data integrity in the event of an error. Sync matches the source and destination tables. If an error occurs, Sync disposes of all data from the current interval, and it can restart processing from that point.
For example, suppose a large sync job is almost completed when an error occurs. Instead of starting the entire job from the beginning, Sync restarts the job from the last successful interval, which saves both time and resources.
Note: Some APIs have access limitations that restrict the number of times you can access them within a given time period. These limitations can cause errors. In the event of such an error, Sync discards the incomplete sync records and begins again from that point at the next scheduled job. You can set the interval size, dictating how much data is pulled in each interval, and limit the amount of data that needs to be moved if an error occurs.
Deletion Captures
CData Sync automatically captures deleted records, which ensures accuracy in your destination. Sync retrieves a list of deleted records from the source by calling the API or by using the Change Tracking feature.
If the source allows Sync to detect data that is deleted, you can control how Sync handles those deletions by using the Deletion Behavior option, as explained in Advanced Job Options:
-
Hard Delete (the default parameter): If a deletion is detected in the source, Sync removes that record from the destination table.
-
Soft Delete: Sync adds the _cdata_deleted column to your destination table. If a deletion is detected in the source, Sync sets the value to true in the destination.
-
Skip Delete: Sync ignores deleted records in the source.
Note: Some APIs do not allow Sync to detect deleted records, as indicated in the Source Information. In these cases, Deletion Behavior is ignored.
Data Types
CData Sync recognizes a large number of data types and, in situations where the data type is not strictly defined, Sync can infer the data type based on your data. Sync recognizes the following data types:
- Boolean
- Date
- Time
- TimeStamp
- Decimal
- Float
- Double
- SmallInt
- Integer
- Long
- Binary
- Varchar
- GUID
Known Data Types
For many sources—mostly relational databases and some APIs (SQL Server, Oracle, and so on)—Sync automatically detects the data types for the schema. When the column data types for the source are known, Sync automatically creates matching data types in the destination.
Inferred Data Types
In situations where a data type is not specified, Sync can infer the data type by scanning the first few rows of data to determine what the column data type should be.
When Sync detects a string type with an unknown column size, the default size of the column is treated as 2000. In a relational database such as SQL Server, Sync creates a varchar(2000) field for this type.
For fields where the data types are not strictly defined, Sync reads the first row and automatically selects the smallest data type for each column. Then, the application reads the next row and ensures that the data still fits in those data types. If the data does not fit, Sync increases the size for the data type. Sync does this up to the row scan depth (RowScanDepth - 50 or 100 rows). When it finishes, Sync has the data types.
For example, in a source like CSV, Sync uses RowScan to read the first rows of the file and determine dynamically the data types for each column.
Transformations
In data pipelines, transformations are a method for transforming, cleansing, or aggregating data in a way that makes it easy for reporting or for data analysis. Sync supports two common ways to manage data transformations when you build data pipelines:
-
ETL: The extract, transform, load (ETL) process has been the traditional approach in analytics for several decades. ETL was designed originally to work with relational databases, which have dominated the market historically. ETL requires transformations to occur before the replication process. Data is extracted from data sources and then deposited into a staging area. Data is then cleaned, enriched, transformed, and loaded into the data warehouse. For more about ETL, see In-Flight ETL.
-
ELT: The extract, load, transform (ELT) process is a method of data extraction where modifications to the data, such as transformations, take place after the replication process. Because modern cloud data warehouses offer vastly greater storage and scaling capabilities, you can move data in its entirety and then modify it after the move.
ELT transformations are SQL scripts that are executed in the destination on your data. Transformations use the processing power of the data warehouse to quickly aggregate, join, and clean your data based on your analytics and reporting needs. By organizing your data with transformations and mapping, you can receive your data in the form that is most useful to you as it moves through your pipeline. Similar to jobs, transformations support multiple queries that are separated by a semicolon (;) execute on a schedule, and send email notifications after the transformations finish. For more about ELT, see Post-Job ELT.
The primary difference between ETL and ELT is the order in which the steps take place.
History Mode
CData Sync history mode provides a method for analyzing historical data in your data sources. History mode is a slowly changing dimension that stores and manages relatively static data (current and historical) in a data warehouse. That data can change slowly (but unpredictably) over time.
In CData, you can use history mode (via the Enable History Mode option) to track the change history for data rows (records) and see how your data changes over time. History mode is available for all connectors that support replication by incremental check columns.
CData supports a combined approach to analyzing historical data. That is, the Enable History Mode option offers both robust tracking for auditing as well as time-series analysis.
History mode works on a per-table basis. So, you can decide which tables you want to analyze and then activate the option for those tables only.
In standard mode, Sync merges and updates existing rows whereas in history mode, Sync appends updated rows to the database table.
When you activate history mode:
-
Sync maintains a full history of data changes for each data record in the source database table.
-
Sync records those change versions to the corresponding table in your destination database table.
To enable this functionality, Sync includes three new columns in the destination table. These columns are defined in the following table:
| Column Name | Column Type | Description |
|---|---|---|
| _cdatasync_active | Boolean | Specifies whether a record is active. |
| _cdatasync_start | Datetime | Specifies the datetime value of the incremental check column at the time the data record becomes active. This value indicates when the record was created or modified in the source table, based on a timestamp that increments with each data update. |
| _cdatasync_end | Datetime | Specifies the datetime value of the incremental check column at the time the data record becomes inactive. A null value in this column indicates that the record is active. |
| _cdatasync_operation | Varchar | Specifies the operation to use: Insert (I), Update (U), or Delete (D). Note: This column applies only when you use Change Data Capture (CDC). |
| _cdatasync_version | Varchar(100) | Specifies the version for each change in the format that is saved in the CSRS table. Note: This column applies only when you use CDC. |
Restrictions and Limitations
With history mode, the following restrictions apply:
-
The source table must support an incremental check column.
-
The source table must contain a primary key.
-
The incremental check column must be a timestamp (datetime) column.
-
The incremental check column cannot be a pseudocolumn because pseudocolumns do not have a value in the response and are used as criteria only.
-
The destination table cannot exist. (Use the Drop Table option on the Advanced tab to re-create the table with history mode active.)
In addition, support for history mode is limited to the following destinations:
-
SQL Server
-
MySQL
-
PostgreSQL
-
Oracle DB
-
Snowflake
-
Databricks
-
Redshift
Note: Additional destinations will be added in the future.
History-Mode Activation for a Job
To activate history mode for a job in Sync:
-
Navigate to the Jobs tab.
-
Click the job that contains the tables from which you want to select.
-
Scroll to Job Settings and click Add Tables. In the Add Tables modal that opens, select your tables.
-
Click Add Selected Tables to add the selected tables and to return to the Job Settings page.
-
Click the Advanced tab to open the advanced settings.
-
Scroll to Replicate Options and select Enable History Mode.
-
Click Save Changes (not shown) in the upper right of the Job Settings page to save and activate history mode for your selected tables.
History-Mode Activation for a Task within a Job
You can enable history mode for tasks, as well, from the Advanced tab in the task settings, as shown below:
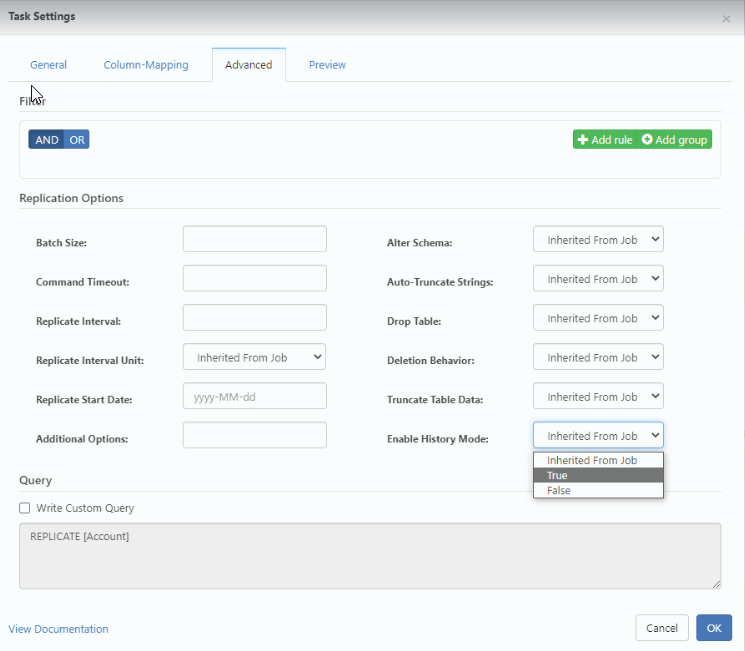
In the advanced settings for a task, history mode has three options:
-
Inherited From Job: If this option is specified, the task inherits history mode from the job.
-
True: This option enables history mode for the task.
-
False This option disables history mode for the task.
History mode is disabled in the task settings also if a table does not support incremental check columns.
Effects of Changing the Source Table
When you change the source table by inserting, updating, or deleting rows, the destination is affected in various ways, as described in the following table:
| Source Change | Destination Effect |
|---|---|
| Inserted Row | A row is added to the destination table. _cdatasync_active is set to True, and _cdatasync_start is set to the incremental check-column value. |
| Updated Row |
|
| Deleted Row | The current row in the destination table is updated. _cdatasync_active is set to False. |
API Access
CData Sync contains a built-in representational state transfer (REST) API that provides a flexible way to manage the application. You can use RESTful API calls to accomplish everything that you can accomplish in the administration console UI.
The REST API comprises the following:
-
The Job Management API enables you to create, update, and execute jobs.
-
The Connection Management API enables you to list, create, modify, delete, and test connections.
-
The User Management API enables you to modify users and to list all users.
For more information about API access, see also REST-API.
In-Network Installation
You can run CData Sync anywhere, which makes the application ideal for customers who have some systems that reside in the cloud and other systems that reside in their internal networks. You can install Sync to run inside your network, thereby avoiding exposure of ports over the internet or open firewalls, the need to create VPN connections, and so on.
The ability to run the Sync application anywhere also greatly reduces the amount of latency. Because you can run Sync close to the source or destination, performance of your ETL or ELT jobs is improved.
Schema Changes
Your data changes constantly, and Sync ensures that those changes are represented accurately at all times. In every run, CData Sync compares the source schema to the destination schema to detect differences. If Sync detects a difference in structure between the two schemas, the application modifies the destination schema, as described below, to ensure that the source data fits:
-
If the source table contains a column that does not exist in the destination table, Sync alters the destination table by adding the column.
-
If the data type in the source table increases in size, Sync alters the destination table by updating the size for the column. Sync updates the column by increasing the column size of a string column (for example, varchar(255) -> varchar(2000)) or the byte size of nonstring columns (for example, smallint -> integer).
Notes:
-
Sync never deletes columns from your destination table if the column is removed from your source table.
-
Sync never reduces the size of a destination column if the size of the data type is updated in the source (varchar(2000) -> varchar(255)).