Apache Kafka Connector Setup
Version 23.4.8841
Version 23.4.8841
Apache Kafka Connector Setup
Apache Kafka コネクタを使って、さまざまなApache Kafka テーブルからデータをプッシュ、またはプルすることでApache Kafka をデータフローに統合することができます。次の手順に従って、CData Arc をApache Kafka に接続します。
接続の確立
Arc でApache Kafka のデータを使用するには、はじめにApache Kafka への接続を確立する必要があります。この接続を確立するには2つの方法があります。
- Apache Kafka コネクタをフローに追加します。次に、設定タブで、接続ドロップダウンリストの横にある作成をクリックします。
- Arc 設定ページを開き、接続タブを開きます。追加をクリックし、Apache Kafka を選択して、次へをクリックします。
Notes:
- ログインプロセスは、初めて接続を作成する場合にのみ必要です。
- Apache Kafka への接続は、複数のApache Kafka コネクタ間で再利用できます。
接続設定の入力
新規接続ダイアログを開いたら、次の手順に従います。
-
必要な情報を入力します:
- 名前 — 接続の静的な名前。
- 種類 — これは常にApache Kafka に設定されます。
- Auth Scheme — The authorization scheme to use for the connection. Options are Auto, None, Plain, Scram, and Kerberos.
- User — (All schemes except None) The Apache Kafka username to use for logging in.
- Password — (All schemes except None) The password for the user entered above.
- Bootstrap Servers — The host/port pair to use for establishing the initial connection to Apache Kafka. If you are connecting to Confluent Cloud, you can find this on the Cluster settings.
-
必要に応じて、高度な設定をクリックして、詳細な接続設定のドロップダウンメニューを開きます。ほとんどの場合これらの設定は必要ありません。
-
接続テストをクリックして、入力した情報でArc がApache Kafka にアクセスできることを確認します。エラーが発生した場合はすべてのフィールドを確認しもう一度やり直してください。
-
接続の追加をクリックして接続を確定します。
-
コネクタの設定ペインの接続ドロップダウンリストで、新しく作成した接続を選択します。
-
トピックフィールドに、対象とするApache Kafka トピックを入力します。
-
変更を保存をクリックします。
Select an Action
After establishing a connection to Apache Kafka, you must choose the action that the Apache Kafka connector should perform. The table below outlines each action and where it belongs in an CData Arc flow:
| Action | Description | Position in Flow |
|---|---|---|
| Produce | Accepts input data from a file or another connector and sends it to Apache Kafka. | End |
| Consume | Checks the queue for messages and sends any data that it gets down the flow through the Output path. | Middle |
Produce
The Produce action sends input data to Apache Kafka. This data can come from other connectors or from files that you manually upload to the Input tab of the Apache Kafka connector. The Apache Kafka connector sends the input data to the topic you entered in the Topic field of the Configuration section.
Consume
The Consume action checks for messages in the Apache Kafka queue for the topic you entered in the Topic field of the Configuration section. You must set the following fields for this action:
- Consumer Group ID: Specifies which group the consumers created by the connector should belong to.
- Read Duration: The length of time (in seconds) that the connector waits for messages to arrive. The connector waits the full duration, regardless of the number of messages received.
Data processed through the Consume connector goes to the Output tab and travels down to the next steps of the Arc flow.
Additional Connection Configuration
Automation Tab
Automation Settings
Settings related to the automatic processing of files by the connector.
- Send Whether files arriving at the connector are automatically sent.
- Retry Interval The number of minutes before a failed send is retried.
- Max Attempts The maximum number of times the connector processes the file. Success is measured based on a successful server acknowledgement. If you set this to 0, the connector retries the file indefinitely.
- Receive Whether the connector should automatically query the data source.
- Receive Interval The interval between automatic query attempts.
- Minutes Past the Hour The minutes offset for an hourly schedule. Only applicable when the interval setting above is set to Hourly. For example, if this value is set to 5, the automation service downloads at 1:05, 2:05, 3:05, etc.
- Time The time of day that the attempt should occur. Only applicable when the interval setting above is set to Daily, Weekly, or Monthly.
- Day The day on which the attempt should occur. Only applicable when the interval setting above is set to Weekly or Monthly.
- Minutes The number of minutes to wait before attempting the download. Only applicable when the interval setting above is set to Minute.
- Cron Expression A five-position string representing a cron expression that determines when the attempt should occur. Only applicable when the interval setting above is set to Advanced.
Performance
Settings related to the allocation of resources to the connector.
- Max Workers The maximum number of worker threads consumed from the threadpool to process files on this connector. If set, this overrides the default setting on the Settings > Automation page.
- Max Files The maximum number of files sent by each thread assigned to the connector. If set, this overrides the default setting on the Settings > Automation page.
アラートタブ
アラートとサービスレベル(SLA)の設定に関連する設定.
コネクタのE メール設定
サービスレベル(SLA)を実行する前に、通知用のE メールアラートを設定する必要があります。アラートを設定をクリックすると、新しいブラウザウィンドウで設定ページが開き、システム全体のアラートを設定することができます。詳しくは、アラートを参照してください。
サービスレベル(SLA)の設定
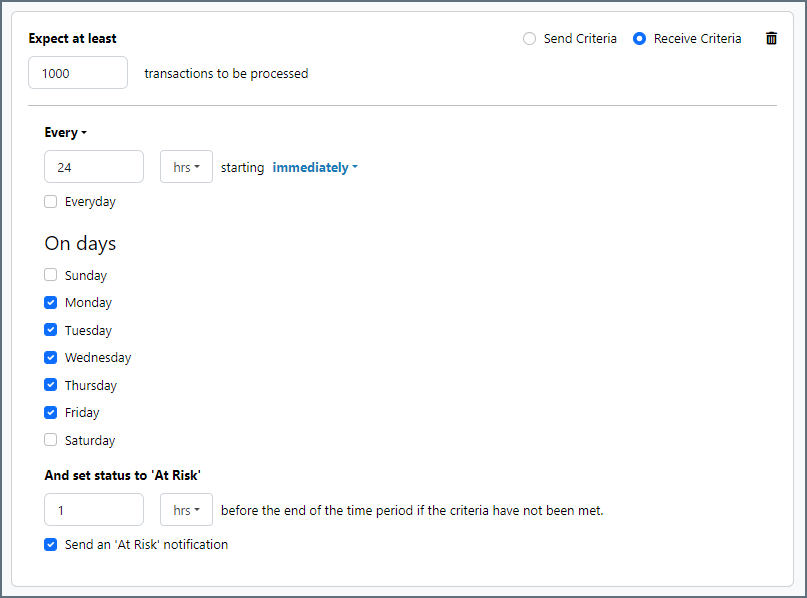
サービスレベルでは、フロー内のコネクタが送受信すると予想される処理量を設定し、その量が満たされると予想される時間枠を設定できます。CData Arc は、サービスレベルが満たされていない場合にユーザーに警告するE メールを送信し、SLA を At Risk(危険) としてマークします。これは、サービスレベルがすぐに満たされない場合に Violated(違反) としてマークされることを意味します。これにより、ユーザーはサービスレベルが満たされていない理由を特定し、適切な措置を講じることができます。At Risk の期間内にサービスレベルが満たされなかった場合、SLA はViolated としてマークされ、ユーザーに再度通知されます。
サービスレベルを定義するには、予想処理量の条件を追加をクリックします。
- コネクタに個別の送信アクションと受信アクションがある場合は、ラジオボタンを使用してSLA に関連する方向を指定します。
- 検知基準(最小)を、処理が予想されるトランザクションの最小値(量)に設定し、毎フィールドを使用して期間を指定します。
- デフォルトでは、SLA は毎日有効です。これを変更するには、毎日のチェックをOFF にし、希望する曜日のチェックをON にします。
- 期間終了前にステータスを’At Risk’ に設定するタイミングを使用して、SLA がAt Risk としてマークされるようにします。
- デフォルトでは、通知はSLA が違反のステータスになるまで送信されません。これを変更するには、‘At Risk’ 通知を送信のチェックをON にします。
次の例は、月曜日から金曜日まで毎日1000ファイルを受信すると予想されるコネクタに対して構成されたSLA を示しています。1000ファイルが受信されていない場合、期間終了の1時間前にAt Risk 通知が送信されます。
Advanced Tab
Message
- Save to Sent Folder Check this to copy files processed by the connector to the Sent folder for the connector.
- Sent Folder Scheme Instructs the connector to group messages in the Sent folder according to the selected interval. For example, the Weekly option instructs the connector to create a new subfolder each week and store all messages for the week in that folder. The blank setting tells the connector to save all messages directly in the Sent folder. For connectors that process many messages, using subfolders helps keep messsages organized and improves performance.
Optional Connection Properties
- Other Driver Settings Hidden properties that are used only in specific use cases.
Logging
- Log Level The verbosity of logs generated by the connector. When you request support, set this to Debug.
- Log Subfolder Scheme Instructs the connector to group files in the Logs folder according to the selected interval. For example, the Weekly option instructs the connector to create a new subfolder each week and store all logs for the week in that folder. The blank setting tells the connector to save all logs directly in the Logs folder. For connectors that process many transactions, using subfolders helps keep logs organized and improves performance.
- Log Messages Check this to have the log entry for a processed file include a copy of the file itself. If you disable this, you might not be able to download a copy of the file from the Input or Output tabs.
Miscellaneous
Miscellaneous settings are for specific use cases.
- Other Settings Enables you to configure hidden connector settings in a semicolon-separated list (for example,
setting1=value1;setting2=value2). Normal connector use cases and functionality should not require the use of these settings.