変更データキャプチャ
Version 26.2.9669
Version 26.2.9669
変更データキャプチャ
一部のデータソースでは変更データキャプチャ(CDC)をサポートしており、データソースはログファイルを使用して、データベースに変更を加えるイベント(挿入、更新、または削除)をログに記録します。CData Sync は、データソーステーブルに変更をクエリするのではなくログファイルを読み込んで変更イベントを確認します。次に、アプリケーションはレプリケーションのためのそれらの変更をほぼリアルタイムで抽出し、次回のレプリケーション用に現在のログを保存します。
以下のデータソースは、CDC の機能をサポートします。これらの一部は、CDC エンジンを使用してニアリアルタイムで変更をキャプチャしてストリーミングします(CDC エンジンを使用するデータソースの一覧については、CDC エンジンソースの変更データキャプチャの有効化を参照してください)。
-
DB2 (Native)—補足ロギングを使用します。
-
DB2 for i (Native)—ジャーナリングを使用します。
-
Informix (Native)—変更データキャプチャAPI を使用します。
-
MariaDB—バイナリログを使用します。
-
Microsoft Dynamics 365—変更の追跡を使用します。
-
MySQL—バイナリログを使用します。
-
Oracle (Native)—Oracle LogMiner を使用します。
-
PostgreSQL (Native)—論理レプリケーションを使用します。
-
SAP ERP—変更データキャプチャAPI を使用します。
-
SAP HANA—トリガーベースのCDC を使用します。
-
SQL Server—CDC または変更の追跡のいずれかを使用します。両方のメソッドがテーブルで有効になっている場合、Sync はCDC を使用します。
Note:SQL Server のソーステーブルに
Always Encryptedカラムが含まれている場合、Sync がJDBC 経由で接続する際にCDC はこれらのカラムをサポートします。JDBC ドライバーは、暗号化された(バイナリまたは16進数の)表現の代わりに復号化されたプレーンテキスト値を返すため、読み取りエラーを発生させることなく、暗号化されたカラムをCDC ベースのレプリケーションワークフローに含めることができます。
このドキュメントでは、以下のコンセプトとタスクについて説明します:
-
CDC パイプラインの定義
-
CDC を使用する場合かどうかの判断
-
ソースデータベースのCDC を有効化
-
Sync でCDC ジョブを作成
-
CDC ジョブにタスクを追加
-
Post-Job 変換を追加
CDC パイプラインとは?
変更データキャプチャ(CDC)は、データソースからサポートされている同期先にデータ変更をストリーミングできるパイプラインを作成し、そのデータに対して変換を実行できるようにします。サポートされている同期先は、以下のいずれかの構造を含めることができます:
-
別のリレーショナルデータベース
-
クラウドストレージシステムまたはデータレイク
-
データウェアハウス(例えばSnowflake、Amazon Redshift、Google BigQuery など)
-
ファイルストレージシステム
-
メッセージキュー(Kafka またはKinesis など)
CDC を使用するかどうかの判断
CDC のアプローチは、ソースデータベースに加えられた変更を識別、キャプチャ、配信するプロセスを通じてデータを統合します。それらのデータ変更はトランザクションログに保存されます。
このアプローチは、次のような状況で有効です:
-
CDC をサポートするデータソースの1つを使用している場合。前述のとおり、Sync はMySQL、Oracle、PostgreSQL、およびSQL Server のネイティブのログベースの変更データキャプチャをサポートしています。
-
リアルタイムに近いデータを必要としている場合。CDC プロセスは、ETL やELT 処理においてほぼリアルタイムでのデータ転送を提供します。
-
リソースの使用を制限または保持したい場合。CDC データ統合は、アプリケーションレベルで変更を加えたり、トランザクションテーブルをスキャンしたりしないので、システムへ与える影響は小さくなります。
ソースデータベースのCDC を有効化
CDC を有効化する方法は、CDC をサポートするデータベースソースごとに異なります。使用するデータソースのCDC を有効にする方法については、以下の該当するリンクをクリックしてください。
CData Sync でCDC ジョブを作成
ジョブを作成するには、事前設定されたデータソースと同期先の接続が必要です。データソースおよび同期先接続の作成に関する詳細は、接続を参照してください。
データソースへの接続と、同期先データベースを定義後、次の手順に従って新しいジョブを作成します。
-
Sync のジョブタブで、ジョブを追加 > 新しいジョブを追加を選択します。ジョブを追加ダイアログボックスが開きます。
-
ダイアログボックスで、ジョブ名を入力し、サポートされているCDC データソースの1つを選択し、さらに同期先も選択します。
-
レプリケーションタイプとして変更データキャプチャを選択します。
-
同期先スキーマリストからスキーマを選択します。
-
ジョブを追加をクリックしてジョブを作成します。
-
ジョブページに戻り、ジョブにアクセスします。
CDC ジョブにタスクを追加
タスクはデータソースから同期先へのデータフローを制御します。通常のレプリケーションジョブでは、すべてのデータソーステーブルをレプリケーションタスクとしてジョブに追加できます。
テーブルをレプリケーションタスクとして追加するには:
-
Sync のジョブタブで、ジョブをクリックします。
-
ジョブ / ジョブ名ページのジョブ設定セクションでタスクを追加をクリックします。このアクションによりスキーマを選択ダイアログボックスが開きます。
-
スキーマリストからスキーマ(例:public)を選択します。
-
ダイアログボックスで特定のテーブルを選択するか、データソース名の横のチェックボックスを選択して、すべてのテーブルを選択します。
-
タスクを追加をクリックして新しいタスクを追加します。
-
ジョブページに戻り、ジョブにアクセスして実行します。
タスクの作成について、詳しくはタスクを参照してください。
主キーを持たないテーブルに対するCDC のサポート
Sync は、同期先テーブルに新しいカラム(_cdatasync_id)を追加することで、主キーのないソーステーブルのCDC をサポートします。このカラムには、行全体のコンテンツから生成されたハッシュ値が格納されます。このハッシュ値は、内容に基づいて行の一意の識別子として機能します。行のいずれかの値が変更されるとハッシュ値も変更されるため、Sync は主キーがなくても行が更新されたことを認識できます。
Sync が_cdatasync_id カラムを追加すると、アプリケーションはINSERT、UPDATE、およびDELETE 操作を次のように処理します:
-
INSERT:データソースで新しい行が検出されると、Sync は
_cdatasync_id値を生成し、その行を同期先に挿入します。 -
UPDATE:Sync は、
_cdatasync_deleted=trueを設定することで、既存の行の論理削除を実行します。その後、Sync は新しい行を挿入します。 -
DELETE:Sync は、
_cdatasync_deleted=trueを設定することで、行の論理削除を実行します。
このアプローチ(新しいカラムの追加)により、主キーを持たないソーステーブルに対して正確なCDC を実現できます。
Post-Job 変換の追加
Sync は、ジョブ完了後のデータ変換プロセスをサポートします。高度なSQL クエリを使用するか、既存のdbt Core およびdbt Cloud プロジェクトを活用することで、単一のプラットフォームですべてのデータニーズに対応できます。
SQL 変換についての詳細は、SQL Transformation を参照してください。DBT 変換についての詳細は、DBT Transformation を参照してください。
Sync CDC エンジンの使用方法
Sync の一部の変更データキャプチャ(CDC)ソースは、CDC エンジンを使用してニアリアルタイムでデータ変更をキャプチャしてストリーミングします。CDC エンジンは、データベーストランザクションログを継続的に監視し、Sync が処理する変更イベントをステージングします。
CDC エンジン
CDC エンジンは、Sync アプリケーションのコンポーネントで、ソースデータベースからのリアルタイムデータ変更を追跡しストリーミングします。CDC エンジンは、トランザクションログ(ログ先行書き込みやREDO ログなど)を監視することでデータの更新を識別し、これらの変更イベントをステージングエリアにファイルとして一時的に保存して、さらに処理できるようにします。このステージングエリアは、アプリケーションディレクトリのjobs フォルダにあります(C:\ProgramData\CData\sync\jobs)。
CDC エンジンを使用する各CDC ジョブには、ステージングエリア内に専用のサブフォルダを持つ専用のエンジンインスタンスがあります。ジョブに含まれる各テーブルに対して、Sync はステージングされた変更イベントファイルを含む対応するサブフォルダを作成します。
ステージファイルの管理
変更イベントの保存を最適化するには、1つのステージファイルに書き込むことができる最大行数を指定するstage.file.max.rows プロパティを設定します。デフォルトでは、この値は100,000行に設定されています。多数のカラムを持つテーブルや大きなオブジェクト(バイナリデータなど)を含むジョブの場合、CData ではこのプロパティの値を減少させることをお勧めします。
次の例に示すように、ジョブの高度な設定タブでテーブルスキーマに応じてこのプロパティを設定できます:
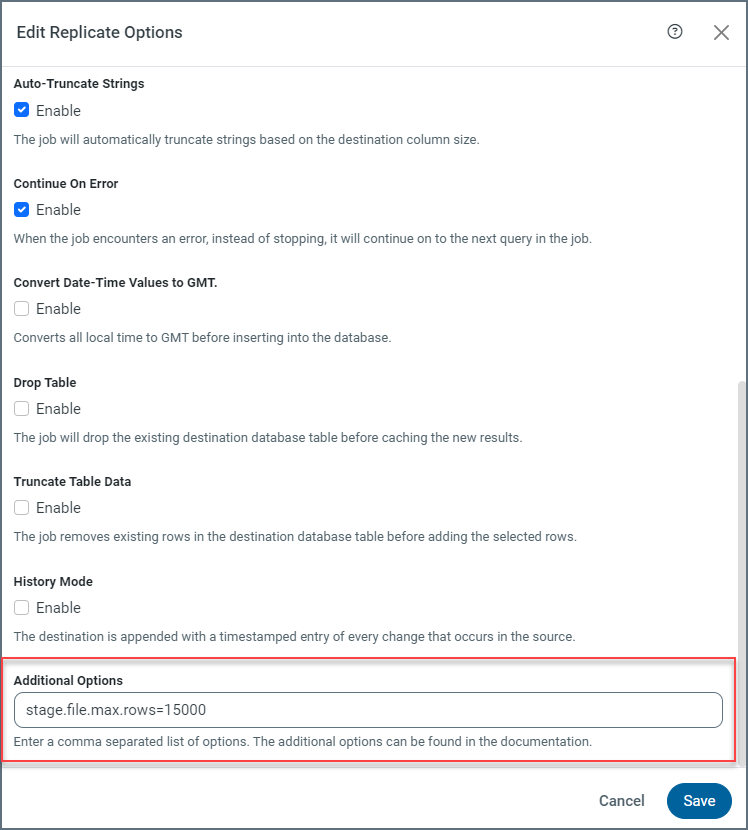
ステージリミットの管理
すべてのCDC ジョブは同じステージングエリアを共有するため、ステージングエリアのサイズを慎重に管理することが重要です。デフォルトでは、ディスクのオーバーロードを防ぐためにステージは10GB に制限されています。この制限はstagemaxsize プロパティを調整することで変更できます。これを行うには、設定 > 高度な設定 > 追加設定 > その他の設定に移動し、以下に示すようにプロパティを適切な値(例えば、stagemaxsize=20)に設定します。
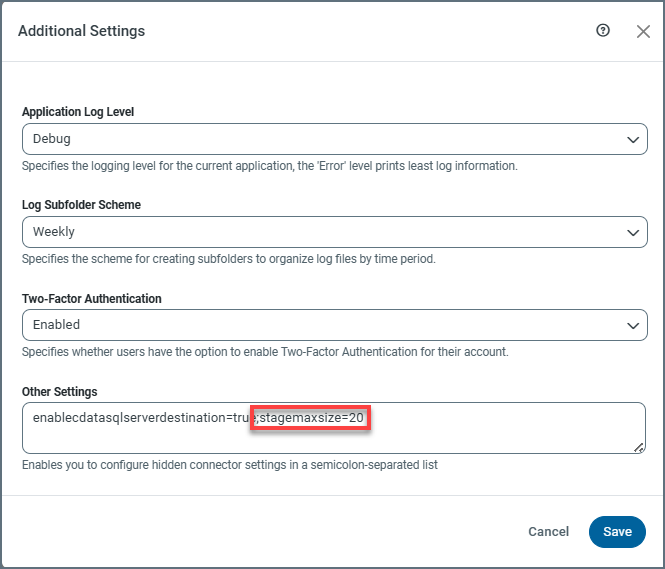
Note:stagemaxsize プロパティは整数値のみを受け入れ、デフォルトではギガバイト(GB)単位で解釈されます。
ステージングエリアがサイズ制限に達すると、すべてのCDC エンジンが自動的に停止します。このような場合、手動でジョブを実行するか、スケジュールされたジョブの実行を待って、蓄積された変更イベントを同期先に複製してステージングエリアを解放する必要があります。最大ステージサイズの3分の1が解放されると、すべてのCDC エンジンが自動的に起動し、リアルタイムデータストリーミング処理を再開します。
オプションとして、概要タブの開始ボタンをクリックしてCDC エンジンを再起動することもできます。
Note:CDC エンジンは継続的に動作し、変更イベントをリアルタイムでストリームするため、ベストプラクティスとして、ジョブを頻繁に実行するようにスケジュールする必要があります。この方法により、ステージングエリアがサイズ制限に達するのを防ぎながら、ニアリアルタイムのレプリケーションが保証されます。
CDC エンジンソースの変更データキャプチャの有効化
変更データキャプチャ(CDC)を有効化するために必要な手順は、ソースデータベースによって異なります。CDC エンジンを使用するソースでは、Sync がトランザクションログまたはネイティブの変更追跡メカニズムから変更をキャプチャできるようにするために、追加の設定が必要になる場合があります。
ご使用のソースに対応する以下のリンクを選択して、具体的な設定手順を参照してください。
CDC エンジンを使用するジョブの作成
CDC エンジンを使用するジョブを作成するには、事前設定されたデータソースと同期先の接続が必要です。データソースおよび同期先接続の追加については、接続を参照してください。
データソースへの接続と、同期先データベースを定義後、次の手順に従って新しいジョブを作成します。
-
Sync のジョブタブで、ジョブを追加 > 新しいジョブを追加をクリックします。ジョブを追加ダイアログボックスが開きます。
-
ダイアログボックスでジョブ名を入力し、CDC をサポートするデータソースと同期先を選択します。CDC エンジンを使用するソースの場合、Sync は自動的にエンジンベースのCDC を使用するようにジョブを設定します。
-
データソースに応じて、適切なプロパティを入力します。
-
ジョブを追加をクリックします。
-
ジョブページに戻り、ジョブにアクセスします。
CDC エンジンを使用するジョブを作成した後は、他のCDC ジョブと同様にタスクを追加します。
タスクの作成について、詳しくはタスクを参照してください。
CDC ジョブの実行とエンジンの動作について
Sync は、CDC エンジンの状態とステージングされたデータの可用性に基づいてCDC ジョブの実行を管理します。CDC ジョブを実行すると、Sync はジョブとCDC エンジン間の実行を調整します。ジョブの動作は、CDC エンジンの状態とステージングされた変更データの可用性によって異なります。
ジョブ実行時のCDC エンジンの利用可能性
Sync は、CDC エンジンの状態とステージングされたデータの可用性に基づいて、CDC ジョブの実行方法を決定します:
-
CDC エンジンが実行中の場合:ジョブは正常に実行され、利用可能なすべての変更を処理します。変更がない場合、ジョブは影響を受けるレコードなしで正常に完了することができます。
-
CDC エンジンが実行中でないが、ステージファイルが存在する場合:ジョブが実行され、既存のステージファイルを処理します。この動作により、エンジンが現在アクティブでない場合でも、以前にキャプチャされた変更を適用できます。
-
CDC エンジンが実行中でなく、ステージファイルも存在しない場合:処理するデータがないためジョブが失敗し、次のエラーが表示されます:
There are no stage files to consume.
CDC エンジンの自動再起動
CDC ジョブの実行前に、Sync はCDC エンジンが利用可能であることを確認しようとします。以下の状況によってSync の応答が決まります:
-
CDC エンジンがエラーまたは予期しない状態のために停止した場合(明示的に停止していない場合)、Sync はジョブの実行前にエンジンを自動的に再起動しようとします。
-
Sync がCDC エンジンを再起動できない場合、ジョブの実行はステージファイルの可用性に基づいて続行されます。ステージファイルが存在しない場合、ジョブは次のエラーで失敗します:
There are no stage files to consume.
これらの状況によりCDC ジョブが正常に実行できない場合は、次のセクションで説明するように、CDC エンジンのリセットが必要になる場合があります。
CDC エンジンのリセット
場合によっては、変更データキャプチャ(CDC)エンジンが最後に記録した位置から処理を再開できないことがあります。この状況は、必要なソースデータベースのログが利用できなくなった場合や、保存されたオフセットが無効になった場合に発生します。
復旧を簡単にするため、Sync はユーザーインターフェースにリセットオプションを提供しており、サーバーに手動でアクセスしたりオフセットファイルを削除したりすることなく、CDC エンジンをリセットできます。このリセットオプションは、サポートされているCDC データソースで利用できます。
CDC エンジンのリセットは、CDC エンジン設定(ジョブ名 > 概要 > CDC エンジン)から次の手順で行います:
-
Sync でジョブを開きます。
-
概要タブで、CDC エンジンセクションを見つけます。
-
リセットボタンをクリックします。

ボタンをクリックすると、CDC エンジンをリセットダイアログボックスが表示され、操作の確認を求められます。
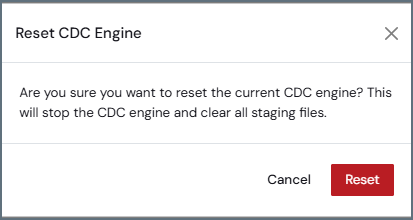
ダイアログボックスのリセットをクリックして続行します。CDC エンジンをリセットすると、エンジンが停止し、すべてのステージングファイルがクリアされることに注意してください。
CDC エンジンのリセット後
CDC エンジンをリセットすると、Sync は以下の操作を実行します:
-
実行中のCDC エンジンを停止する
-
キャプチャされたイベントのステージフォルダをクリアする
-
ジョブのステージテーブルをクリアする
-
オフセットファイルを削除する
-
処理済み行数を0にリセットする
-
ジョブのタスクのCDC エンジンステータスレコードを削除する
リセットが完了すると、Sync は確認メッセージを表示します。
CDC エンジンをリセットした後、次のジョブ実行ではソースデータの完全なスナップショットが実行されます。この動作により、同期先がソースと完全に再同期されます。
CDC エンジンのリセットが必要な場合
以下の状況では、CDC エンジンのリセットが必要になる場合があります:
-
必要なログファイルが利用できなくなったことを示すエラーでCDC エンジンが失敗した場合。
-
保持ポリシーまたはシステムの変更により、ソースデータベースのログが削除された場合。
-
保存されたオフセットが無効になり、ジョブを再開できない場合。
-
自動復旧で問題が解決しない場合。
範囲外エラーの自動復旧
サポートされているコネクタでは、Sync は特定のCDC 障害から自動的に復旧できます。CDC エンジンが範囲外の状態を検出した場合(例えば、必要なログが利用できなくなった場合)、Sync は以下の操作を実行します:
-
CDC エンジンのステータスを範囲外の状態を示すように設定する
-
ステージをクリアする
-
ユーザーインターフェースにエラーメッセージを表示し、復旧の準備中は一時的に開始オプションを無効にする
次のジョブ実行時に、Sync はCDC エンジンを再起動し、同期先テーブルを削除して再作成するのではなく、更新します。このアプローチにより、同期先スキーマおよびテーブルに依存するダウンストリームの統合が保持されます。
Note:範囲外の自動復旧は、現在、Oracle およびInformix ソースコネクタのみでサポートされています。
自動復旧で問題が解決しない場合は、前のセクションで説明したように、CDC エンジンを手動でリセットできます。