Flat File Connector
Version 23.4.8841
Version 23.4.8841
Flat File Connector
Flat File connectors convert flat file formats into XML, and vice versa.
Overview
Each Flat File connector is configured with a specific flat file format to convert to XML or to generate from XML. The Flat File connector has two primary modes:
- Position Delimited
- Character Delimited
For Position Delimited flat files, the connector is configured with an arbitrary set of field names, indices (such as positions), and lengths indicating where data appears in each line of the flat file.
For Character Delimited flat files, the connector is configured with the character that separates field values in the flat file.
See Defining the Flat File Format for details.
The Flat File connector supports defining multiple types of lines in the flat file. For example, a flat file might have a header line representing Purchase Order data, and multiple item lines representing the Line Items in the order.
The key to defining multiple line types is to specify the Control Field; this value is what determines the type of a specific line in the flat file data (for example, a header line might have a control field value of HEAD while an item line has a control field value of ITEM). See Multiple Line Types for details on how to configure multiple line types.
Once the flat file format is configured, the connector converts files that match this format into XML. The resulting XML structure is explained in XML Format. The Flat File connector can also translate XML that fits this structure into a flat file according to the defined flat file format.
Some flat files have implied hierarchical relationships between different line types. For information on preserving these hierarchical relationships when converting the flat file to XML, see Multi-Line Hierarchy.
Connector Configuration
Settings Tab
Configuration
Settings related to the core configuration of the connector.
- Connector Id The static, unique identifier for the connector.
- Connector Type Displays the connector name and a description of what it does.
- Connector Description An optional field to provide a free-form description of the connector and its role in the flow.
- File Type Position Delimited—the fields in the flat file appear at a specific position in each line.
Character Delimited—the fields in the flat file are separated by a specific character defined by the Delimiter field. - Delimiter If File Type is Character Delimited, specify the character that separates individual fields in the flat file.
Control Field: Position Delimited
Settings related to the Control Field when the connector is set to Position Delimited.
- Multi-line Mode Whether the flat file format includes multiple line types. See Multiple Line Types for more information.
- Start Index If Multi-line Mode is enabled, this value is the index in the line where the Control Field begins. For example, if the first field in a line is the control field, then the Start Index should be 0.
- Control Field Length (Optional) If Multi-line Mode is enabled, this value defines the number of characters to read from the Start Index to get the value of the Control Field.
- Column Headers Present If Multi-line Mode is disabled, this determines whether the first line of a flat file should be interpreted as column headers. Enabling this setting causes the connector to generate a header row when converting from XML to flat file.
Control Field: Character Delimited
Settings related to the Control Field when the connector is set to Character Delimited.
- Multi-line Mode Whether the flat file format includes multiple types of lines. See Multiple Line Types for more information.
- Field Index If Multi-line Mode is enabled, this is the index of the Control Field in the line (indices start at 0). For example, if the second field of a line is the control field, then the Field Index should be 1.
- Generate Field/Line Type Names If Multi-line Mode is enabled, this setting provides the option to not specify the names and indexes of the fields and line types in the flat file. When this setting is enabled, the connector auto-generates XML element names for fields and line types that are not explicitly defined in the Line Types section below.
- Column Headers Present If Multi-line Mode is disabled, this determines whether the first line of a flat file should be interpreted as column headers. Enabling this setting causes the connector to generate a header row when converting from XML to flat file.
- Generate Field Names If Multi-line Mode is disabled, this determines whether the connector generates generic field names. Disable this setting if you want to manually specify the field names in the Line Types section.
Line Types
This section lets you define the field names and positions in the flat file format. See Defining the Flat File Format for details on defining the flat file format.
If File Type is Position Delimited and Multi-line Mode is enabled, click the Add Line Type button to define multiple line types. Each line type has a Control Field Value, which is used to identify the line type. For example, a header line might have the control field value of HEAD, while an item line has the control field value of ITEM.
If File Type is set to Character Delimited, Multi-line Mode is enabled, and Generate Field/Line Type Names is enabled, you do not need to provide names and indexes for all of the fields or line types present in the flat file. In this case, the connector auto-generates XML element names for any unspecified fields or line types. Uncheck Generate Field/Line Type Names to manually specify the field names.
Advanced
- Padding Character When creating a flat file and the field value does not fill the entire field length, this character is used to fill the rest of the field.
- Invalid XML Name Prefix Some field names are not valid names for XML elements (for example, fields that begin with a number like ‘123ABC’), so you must apply a prefix to generate XML from the flat file. When translating from XML to flat file, the connector looks for this prefix and removes it.
- Line Separator Specifies the control character that the connector uses for line endings when writing files. Options are LF (default) and CRLF.
- Local File Scheme A scheme for assigning filenames to messages that are output by the connector. You can use macros in your filenames dynamically to include information such as identifiers and timestamps. For more information, see Macros.
- Nest Line Types This setting is only relevant when converting flat files to XML, and when there are multiple line types in the flat file. If Multi-line Mode is enabled, enabling this setting instructs the connector to add hierarchy to the resulting XML based on the control fields of the flat file lines. See Multi-Line Hierarchy for details on this automatic hierarchy.
- Pad on EOL By default, the connector throws an error if it encounters an unexpected end-of-line. When enabled, this setting tells the connector to pad out the remainder of the line instead of throwing an error.
- Force Cell Delimiter If File Type is set to Character Delimited, enabling this setting instructs the connector to wrap each cell value in cell delimiters (
"). Disabling this setting instructs the connector to only wrap the cell value in cell delimiters if the specified character delimiter is present in the cell value. - Processing Delay The amount of time (in seconds) by which the processing of files placed in the Input folder is delayed. This is a legacy setting. Best practice is to use a File connector to manage local file systems instead of this setting.
Message
Message settings determine how the connector searches for messages and manages them after processing. You can save messages to your Sent folder or you can group them based on a Sent folder scheme, as described below.
- Save to Sent Folder A toggle that instructs the connector to keep a copy of sent messages in the Sent folder.
- Sent Folder Scheme Instructs the connector to group files in the Sent folder according to the selected interval. For example, the Weekly option instructs the connector to create a new subfolder each week and store all sent files for the week in that folder. The blank setting instructs the connector to save all files directly in the Sent folder. For connectors that process many transactions, using subfolders can help keep files organized and improve performance.
Logging
Settings that govern the creation and storage of logs.
- Log Level The verbosity of logs generated by the connector. When you request support, set this to Debug.
- Log Subfolder Scheme Instructs the connector to group files in the Logs folder according to the selected interval. For example, the Weekly option instructs the connector to create a new subfolder each week and store all logs for the week in that folder. The blank setting tells the connector to save all logs directly in the Logs folder. For connectors that process many transactions, using subfolders helps keep logs organized and improves performance.
- Log Messages Check this to have the log entry for a processed file include a copy of the file itself. If you disable this, you might not be able to download a copy of the file from the Input or Output tabs.
Miscellaneous
Miscellaneous settings are for specific use cases.
- Other Settings Enables you to configure hidden connector settings in a semicolon-separated list (for example,
setting1=value1;setting2=value2). Normal connector use cases and functionality should not require the use of these settings.
Automation Tab
- Send Whether files arriving at the connector are automatically processed.
Performance
Settings related to the allocation of resources to the connector.
- Max Workers The maximum number of worker threads consumed from the threadpool to process files on this connector. If set, this overrides the default setting on the Settings > Automation page.
- Max Files The maximum number of files sent by each thread assigned to the connector. If set, this overrides the default setting on the Settings > Automation page.
アラートタブ
アラートとサービスレベル(SLA)の設定に関連する設定.
コネクタのE メール設定
サービスレベル(SLA)を実行する前に、通知用のE メールアラートを設定する必要があります。アラートを設定をクリックすると、新しいブラウザウィンドウで設定ページが開き、システム全体のアラートを設定することができます。詳しくは、アラートを参照してください。
サービスレベル(SLA)の設定
サービスレベルでは、フロー内のコネクタが送受信すると予想される処理量を設定し、その量が満たされると予想される時間枠を設定できます。CData Arc は、サービスレベルが満たされていない場合にユーザーに警告するE メールを送信し、SLA を At Risk(危険) としてマークします。これは、サービスレベルがすぐに満たされない場合に Violated(違反) としてマークされることを意味します。これにより、ユーザーはサービスレベルが満たされていない理由を特定し、適切な措置を講じることができます。At Risk の期間内にサービスレベルが満たされなかった場合、SLA はViolated としてマークされ、ユーザーに再度通知されます。
サービスレベルを定義するには、予想処理量の条件を追加をクリックします。
- コネクタに個別の送信アクションと受信アクションがある場合は、ラジオボタンを使用してSLA に関連する方向を指定します。
- 検知基準(最小)を、処理が予想されるトランザクションの最小値(量)に設定し、毎フィールドを使用して期間を指定します。
- デフォルトでは、SLA は毎日有効です。これを変更するには、毎日のチェックをOFF にし、希望する曜日のチェックをON にします。
- 期間終了前にステータスを’At Risk’ に設定するタイミングを使用して、SLA がAt Risk としてマークされるようにします。
- デフォルトでは、通知はSLA が違反のステータスになるまで送信されません。これを変更するには、‘At Risk’ 通知を送信のチェックをON にします。
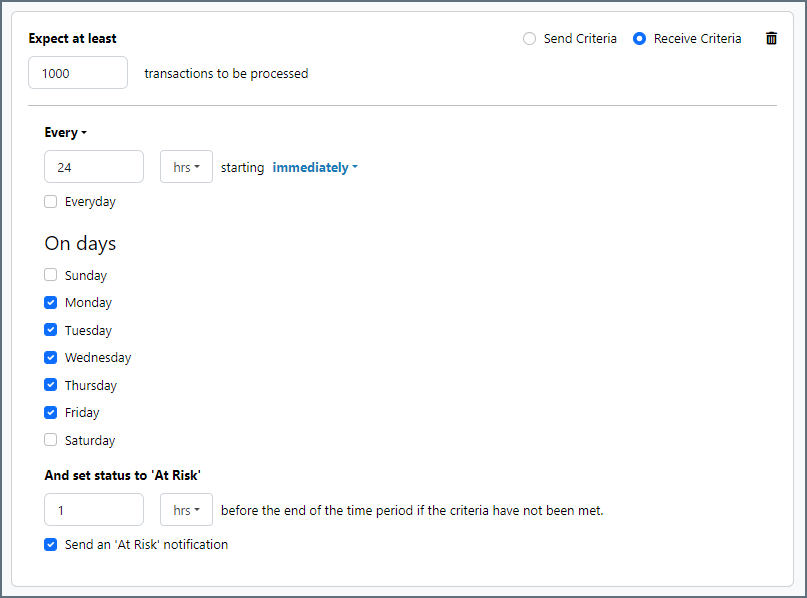
次の例は、月曜日から金曜日まで毎日1000ファイルを受信すると予想されるコネクタに対して構成されたSLA を示しています。1000ファイルが受信されていない場合、期間終了の1時間前にAt Risk 通知が送信されます。
Defining the Flat File Format
The first step in configuring a Flat File connector is defining the format of the flat file. This section describes formats that have a single line type; in other words, each line in the flat file has the same set of fields. For flat files with multiple line types, see Multiple Line Types.
Character Delimited Single-line Format
For Character Delimited flat files, defining the format is simple: use the Delimiter property to specify the character that separates different fields in the flat file.
The Column headers present field indicates whether the first line of the flat file is a header line; in other words, it contains the names of fields rather than actual data. If these column headers are present, the connector uses the header names as the names of XML elements in the resulting translated XML. Similarly, the connector uses the XML element names to generate a header row when translating from XML to flat file.
If column headers are not present, the connector supports manually specifying the names of each field by adding the fields in the Line Types portion of the Settings tab. These field names are applied in index order, meaning that the first entry in Line Types is the name of the first field in the flat file line, and so on.
You can also auto-generate generic field names by enabling Use auto generated field names.
Position Delimited Single-line Format
For Position Delimited flat files, defining the format requires specifying the position of each field in the format. The Line Types portion of the Settings tab provides an interface for adding an arbitrary number of fields that are present in each line of the flat file. Each field must be identified by a name and the position in the file it appears.
The Column headers present field indicates whether the first line of the flat file is a header line; in other words, it contains the names of fields rather than actual data. The field names must still be configured in the Line Types section; this setting simply helps ensure that a header row is not interpreted as real data.
Multiple Line Types
If your flat file format contains multiple types of lines, enable the Multi-line Mode property in the Control Field potion of the Settings tab. The field in the flat file that identifies the line type is known as the control field.
Character Delimited Multi-line Format
When the File Type is Character Delimited, the Field Index setting determines where the control field appears in each line of the flat file. This index starts at 0, meaning that if the control field is the 5th value in the line, the Field Index should be 4.
For each possible value that might appear in the control field define a new line type by clicking the Add Line Type button in the Line Types portion of the Settings tab. Set the value that identifies the line type in the Control Field Value for that line.
Once each possible line type has been added and identified using a specific Control Field Value, the fields that appear in each line type should be specified in index order.
If Generate Field/Line Type Names is enabled, you do not need to provide names and indexes for all of the fields or line types present in the flat file (only the Control Field is required). In this situation, the connector auto-generates XML element names for any unspecified fields or line types.
Position Delimited Multi-line Format
When the File Type is Position Delimited, the Start Index setting determines the position where the control field begins in each line of the flat file. This index starts at 0, meaning that if the control field begins at the 15th character in the line, the Field Index should be 14.
For each possible value that might appear in the control ield, define a new line type by clicking the Add Line Type button. Set the value that identifies the line type in the Control Field Value for that line.
Once each possible line type has been added and identified using a specific Control Field Value, the fields that appear in each line type should be specified along with the position in the line where they begin.
Multi-line Example
For example, say that a flat file contains two types of lines, a shipment line type and a package line type. The shipment line contains information on the date, time, and address of shipment, and the package line type contains information on the items being shipped. The first field in each line is SHIP or PCKG to indicate what type of line it is.
To handle this case, enable Multi-line mode, and set the Field Index or Start Index to 0 to indicate that the control field is the first field in the line. Then, configure two line types in the Line Types section: one with a Control Field Value of SHIP, which contains each field in a shipment line (for example, ShipDate, DeliveryDate, and ShipToAddress), and one with a Control Field Value of PCGK, which contains each field in a package line (such as ItemName and ItemWeight).
XML Format
Once a flat file is converted to XML, the result has the following XML structure:
- One Items_ element at the root of the document
- Each line in the flat file has an element named the same as the Control Field Value for that line (or row if no Control Field Value is defined)
- Each field in the row is a child element of the Control Field Value element
For example, if a flat file has SHIP and PCKG lines, then the XML output would look similar to this:
<Items>
<SHIP>
<ShipmentId>12B992</ShipmentId>
<Date>20230228</Date>
<ShipTo>14 Wallaby Way</ShipTo>
</SHIP>
<PCKG>
<ShipmentId>12B992</ShipmentId>
<ItemName>Goggles</ItemName>
<ItemWeight>3.98</ItemWeight>
</PCKG>
<PCKG>
<ShipmentId>12B992</ShipmentId>
<ItemName>Fins</ItemName>
<ItemWeight>1.07</ItemWeight>
</PCKG>
</Items>
To convert an XML file into a flat file, the XML input must match the structure above (this includes the restriction that the field names must match the defined fields in the connector configuration).
When converting XML into a flat file, the connector creates a new line in the resulting flat file for each row element in the input XML. For each child of the row element, the connector matches the child to a field name in the connector configuration, and places the value for that element at the appropriate field index.
Multi-Line Hierarchy
Flat files with multiple line types often have an implied hierarchical relationship between the line types. For example, one line might contain data for a Purchase Order (such as customer name and order date), while the following lines represent each line item in that order (for example item name and item quantity). The line items belong to the order, creating a hierarchical relationship.
These relationships are sometimes referred to as master-detail relationships, which in our example means that the first line type (Purchase Order) is the master, and the following lines (line items) are details about that master line. In XML, this is often represented as a parent-child relationship.
The Flat File connector can preserve these hierarchical relationships when translating flat files to XML. If you enable the Nest Line Types setting on the Advanced tab, the connector automatically indents the detail line types so that they are children of the master line types.
The following is a simple example of translating a hierarchical flat file with Nest Line Types enabled. The section after the example explains the logic the connector uses to determine the hierarchical relationships.
Multi-Line Hierarchy Example
Take as example input the following flat file:
M,CustomerA,05022020,true
D,itemA,4,2.09
D,itemB,9,15.23
M,CustomerB,05032020,false
D,itemC,1,5.99
D,itemE,1,3.99
There are two line types in this flat file, M and D:
- M, or master, contains information for an order: customer name, order date, and a high-value customer flag.
- D, or detail, contains line item information for the preceeding order: item name, item quantity, and item price.
Since the D line type belongs to the M line type in a hierarchical relationship, you might want to preserve this hierarchy when translating the flat file to XML. To see what this looks like, take the following example output when the Nest Line Types setting is enabled and the flat file above is translated to XML:
<Items>
<M>
<CustomerName>CustomerA</CustomerName>
<OrderDate>05022020</OrderDate>
<HighValueCustomer>true</HighValueCustomer>
<D>
<ItemName>itemA</ItemName>
<ItemQuantity>4</ItemQuantity>
<ItemPrice>2.09</ItemPrice>
</D>
<D>
<ItemName>itemB</ItemName>
<ItemQuantity>9</ItemQuantity>
<ItemPrice>15.23</ItemPrice>
</D>
</M>
<M>
<CustomerName>CustomerB</CustomerName>
<OrderDate>05032020</OrderDate>
<HighValueCustomer>false</HighValueCustomer>
<D>
<ItemName>itemC</ItemName>
<ItemQuantity>1</ItemQuantity>
<ItemPrice>5.99</ItemPrice>
</D>
<D>
<ItemName>itemE</ItemName>
<ItemQuantity>1</ItemQuantity>
<ItemPrice>3.99</ItemPrice>
</D>
</M>
</Items>
Notice that the D records are children of the M records, which accurately reflects the hierarchy present in the source data.
Multi-Line Hierarchy Logic
The Flat File connector uses the order of lines in the source flat file to determine the hierarchy between line types. When Nest Line Types is enabled, the connector uses the following logic:
- The first line type the connector encounters is always treated as the top level of hierarchy (it is not indented in the resulting XML)
- After the first line type, when the connector encounters a new line type it assumes this line type is one level of hierarchy below the previous line type (it belongs to the previous line and is therefore indented in the resulting XML)
- When the connector encounters a line type it has encountered before, it returns to that line type’s level of hierarchy, closing all XML elements at hierarchy levels equal-to or below this level.
This means that the source flat file must have lines in order according to the desired hierarchy.
Macros
Using macros in file naming strategies can enhance organizational efficiency and contextual understanding of data. By incorporating macros into filenames, you can dynamically include relevant information such as identifiers, timestamps, and header information, providing valuable context to each file. This helps ensure that filenames reflect details important to your organization.
CData Arc supports these macros, which all use the following syntax: %Macro%.
| Macro | Description |
|---|---|
| ConnectorID | Evaluates to the ConnectorID of the connector. |
| Ext | Evaluates to the file extension of the file currently being processed by the connector. |
| Filename | Evaluates to the filename (extension included) of the file currently being processed by the connector. |
| FilenameNoExt | Evaluates to the filename (without the extension) of the file currently being processed by the connector. |
| MessageId | Evaluates to the MessageId of the message being output by the connector. |
| RegexFilename:pattern | Applies a RegEx pattern to the filename of the file currently being processed by the connector. |
| Header:headername | Evaluates to the value of a targeted header (headername) on the current message being processed by the connector. |
| LongDate | Evaluates to the current datetime of the system in long-handed format (for example, Wednesday, January 24, 2024). |
| ShortDate | Evaluates to the current datetime of the system in a yyyy-MM-dd format (for example, 2024-01-24). |
| DateFormat:format | Evaluates to the current datetime of the system in the specified format (format). See サンプル日付フォーマット for the available datetime formats |
| Vault:vaultitem | Evaluates to the value of the specified vault item. |
Examples
Some macros, such as %Ext% and %ShortDate%, do not require an argument, but others do. All macros that take an argument use the following syntax: %Macro:argument%
Here are some examples of the macros that take an argument:
- %Header:headername%: Where
headernameis the name of a header on a message. - %Header:mycustomheader% resolves to the value of the
mycustomheaderheader set on the input message. - %Header:ponum% resolves to the value of the
ponumheader set on the input message. - %RegexFilename:pattern%: Where
patternis a regex pattern. For example,%RegexFilename:^([\w][A-Za-z]+)%matches and resolves to the first word in the filename and is case insensitive (test_file.xmlresolves totest). - %Vault:vaultitem%: Where
vaultitemis the name of an item in the vault. For example,%Vault:companyname%resolves to the value of thecompanynameitem stored in the vault. - %DateFormat:format%: Where
formatis an accepted date format (see サンプル日付フォーマット for details). For example,%DateFormat:yyyy-MM-dd-HH-mm-ss-fff%resolves to the date and timestamp on the file.
You can also create more sophisticated macros, as shown in the following examples:
- Combining multiple macros in one filename:
%DateFormat:yyyy-MM-dd-HH-mm-ss-fff%%EXT% - Including text outside of the macro:
MyFile_%DateFormat:yyyy-MM-dd-HH-mm-ss-fff% - Including text within the macro:
%DateFormat:'DateProcessed-'yyyy-MM-dd_'TimeProcessed-'HH-mm-ss%