DB2 for i (Native)
Version 26.2.9669
Version 26.2.9669
DB2 for i (Native)
You can use the DB2 for i connector from the CData Sync application to capture data from DB2 for i and move it to any supported destination. To do so, you need to add the connector, authenticate to the connector, and complete your connection.
Prerequisites
Before you add and set up the DB2 for i source connector, you need to set up the DB2 for i database for change data capture (CDC), as explained in the following sections.
Limitations:
The following capabilities are not supported in Sync:
-
remote journals or failover functionality
-
large objects such as CLOB, XML, TEXT, BLOB
Set Up DB2 for i for CDC
Journaling records database changes in journal receivers, which the change data capture (CDC) process uses to capture and replicate those changes to other systems in real-time or near real-time synchronization.
A journal is a database object that serves as a tracking mechanism, capturing metadata about changes made to specific database objects. Each journal is linked to one or more journal receivers, which physically store the detailed change records, including before-and-after images of the data as well as metadata and transaction details.
Because CDC depends on journaling to supply detailed change records, creating a journal and journal receiver and setting user permissions are the first steps in enabling CDC for DB2 for i, as explained in the next sections.
Create the Journal Receiver and Journal and Enable Journaling on Tables
Run the following command-line (CL) commands to create the journal receiver, journal, and enable journaling on tables:
-- 1. Create a journal receiver.
CRTJRNRCV <RECEIVER_LIBRARY>/<RECEIVER_NAME>
-- 2. Create a journal.
CRTJRN <JOURNAL_LIBRARY>/<JOURNAL_NAME> <RECEIVER_LIBRARY>/<RECEIVER_NAME>
-- 3. Enable journaling on a file (table) by using the STRJRNPF command. As a best practice, capture both before-and-after images of the records to support features like auditing and recovery.
STRJRNPF <FILE_LIBRARY>/<FILE_NAME> <JOURNAL_LIBRARY>/<JOURNAL_NAME> IMAGES(*BOTH)
-- If you already started journaling and need to change the image settings, submit the CHGJRNOBJ command.
CHGJRNOBJ OBJ((<FILE_LIBRARY>/<FILE_NAME> *FILE)) ATR(*IMAGES) IMAGES(*BOTH)
-- To stop journaling for a specific physical file (table), use the ENDJRNPF command.
ENDJRNPF FILE(<FILE_LIBRARY>/<FILE_NAME>) JRN(<JOURNAL_LIBRARY>/<JOURNAL_NAME>)
To verify that journaling is enabled for a table, or for details about the journals and their journal receivers, execute the following queries:
SELECT * FROM QSYS2.JOURNAL_RECEIVER_INFO WHERE JOURNAL_RECEIVER_LIBRARY = <RECEIVER_LIBRARY>;
SELECT * FROM QSYS2.JOURNAL_INFO WHERE JOURNAL_LIBRARY = '<JOURNAL_LIBRARY>';
SELECT * FROM QSYS2.JOURNALED_OBJECTS WHERE JOURNAL_LIBRARY = '<JOURNAL_LIBRARY>';
The following example creates the RCV01 journal receiver and the JRN1 journal. Then, it adds the PRODUCTS table for journaling by using QSYS2.QCMDEXC to call any CL command through the JDBC tool. All of the objects are created in the TEST2 schema/library.
-- 1.Create a NEW journal receiver.
CALL QSYS2.QCMDEXC('CRTJRNRCV TEST2/RCV01');
-- 2. Create a journal.
CALL QSYS2.QCMDEXC('CRTJRN TEST2/JRN1 TEST2/RCV01');
-- 3. Start journaling tables/files.
CALL QSYS2.QCMDEXC('STRJRNPF FILE(TEST2/PRODUCTS) JRN(TEST2/JRN1) IMAGES(*BOTH)');
-- 4. Stop journaling tables/files.
CALL QSYS2.QCMDEXC('ENDJRNPF FILE(TEST2/PRODUCTS) JRN(TEST2/JRN1)');
VALUES CURRENT_SCHEMA; -- TEST2
SELECT * FROM QSYS2.JOURNAL_RECEIVER_INFO WHERE JOURNAL_RECEIVER_LIBRARY = CURRENT_SCHEMA;
SELECT * FROM QSYS2.JOURNAL_INFO WHERE JOURNAL_LIBRARY = CURRENT_SCHEMA;
SELECT * FROM QSYS2.JOURNALED_OBJECTS WHERE JOURNAL_LIBRARY = CURRENT_SCHEMA;
When you create a CDC job in Sync, you select the journal and schema to determine which tables are available for capture.
Set Required User Permissions
To verify all permissions for the user to which you are connected, submit the following query:
SELECT * FROM QSYS2.OBJECT_PRIVILEGES WHERE AUTHORIZATION_NAME = '<CDC_USER>'
If the user lacks privileges to the journal, journal receiver, or the schema (library) from which you want to capture changes, run the following CL commands:
GRTOBJAUT OBJ(<JOURNAL_LIBRARY>) OBJTYPE(*LIB) USER(<CDC_USER>) AUT(*EXECUTE)
GRTOBJAUT OBJ(<JOURNAL_LIBRARY>/*ALL) OBJTYPE(*JRNRCV) USER(<CDC_USER>) AUT(*USE)
GRTOBJAUT OBJ(<JOURNAL_LIBRARY>/<JOURNAL_NAME>) OBJTYPE(*JRN) USER(<CDC_USER>) AUT(*USE *OBJEXIST)
GRTOBJAUT OBJ(<RECEIVER_LIBRARY>) OBJTYPE(*LIB) USER(<CDC_USER>) AUT(*EXECUTE)
GRTOBJAUT OBJ(<RECEIVER_LIBRARY>/*ALL) OBJTYPE(*FILE) USER(<CDC_USER>) AUT(*USE)
Note: To execute the commands through a Java Database Connectivity (JDBC) tool, use this command:
CALL QSYS2.QCMDEXC('CL COMMAND');
Add the DB2 for i Connector
To enable Sync to use data from DB2 for i, you first must add the connector, as follows:
-
Open the Connections page of the Sync dashboard.
-
Click Add Connection to open the Select Connectors page.
-
Click the Sources tab and locate the DB2 for i (Native) row.
-
Click the Configure Connection icon at the end of that row to open the New Connection page. This action opens the Add Connection dialog box.
Note: If the Configure Connection icon is not available, click the Download Connector icon to install the DB2 for i (Native) connector.
-
Enter a name for your connection in the Add Connection dialog box.
-
Click Add to open the Settings tab for your connector.
For more information about installing new connectors, see Connections.
Authenticate to DB2 for i
After you add the connector, you need to set the required properties.
-
Server: Enter the address or host name of the DB2 for i server. The default server is localhost.
-
Database: Enter the name of your DB2 for i database.
-
Port: Enter the port number for your server. The default port is 446.
-
User: Enter the username that you use to authenticate to the DB2 for i database.
-
Password: Enter the password that you use to authenticate to the DB2 for i database.
Complete Your Connection
To complete your connection:
-
Define advanced connection settings on the Advanced tab. (In most cases, though, you should not need these settings.)
-
Click Create & Test to create your connection.
Create a Change Data Capture (CDC) Job with Journal and Schema Selections
This section explains how to create a change data capture (CDC) job for DB2 for i and how to configure row identification for tables without primary keys.
Create the CDC Job
Follow these steps to create a CDC job for DB2 for i:
-
Enter a name for your job.
-
Select your DB2 for i source.
-
Select your destination.
-
Specify values for the following fields:
-
Journal Library
-
Journal Name
-
Source Schema
You can select the values for each of these properties from their drop-down lists. Sync validates these values against the DB2 for i system to ensure that the journal exists and is properly configured.
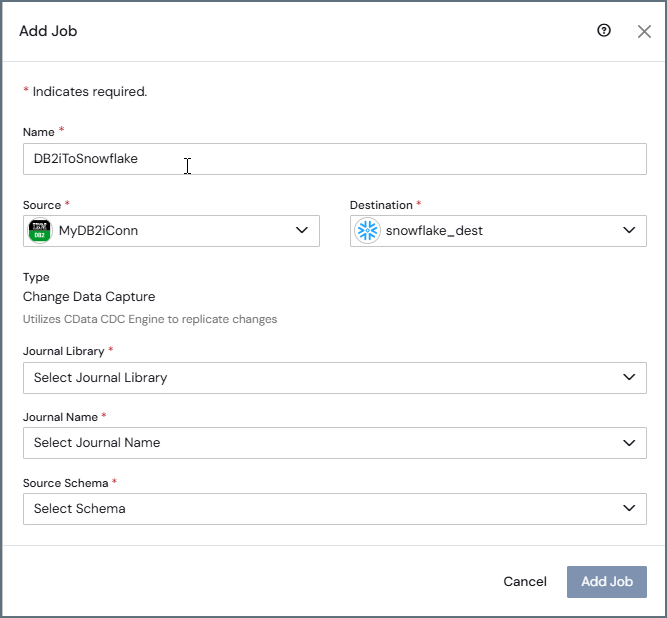
-
-
Click Add Job.
After the job is created, the journal settings are displayed in the CDC engine settings and cannot be modified.
-
Continue to the job’s Task tab for table selection. Only tables that meet the following criteria are displayed:
-
The table is journaled.
-
The table is associated with the selected journal.
-
The table belongs to the selected schema.
-
If you change the journal or schema, previously selected incompatible tables are automatically deselected.
Note: When you create DB2 for i CDC jobs through the API, you must provide the journal library and journal name.
Configure Row Identification for Tables without Primary Keys
When you configure a change data capture (CDC) job for DB2 for i, you can use the relative record number (RRN) as the value for the _cdatasync_id column. This approach provides a stable identifier for tables that do not have a primary key.
To use the RRN as the Sync identifier, set the following option:
SyncIdSourceColumn=Db2Rrn
When you set this option, Sync uses the RRN instead of the default MD5-based row hash to generate the _cdatasync_id value.
Note: For jobs that you create in Sync v26.2, the RRN is set as the identifer by default.
When you use the RRN-based identifier:
-
The
_cdatasync_idcolumn is represented as a BigInt data type. -
The identifier is derived directly from the physical row location in the source table.
-
The
_cdatasync_idcolumn can be used as a partition key for destinations that support partitioning.
This approach is recommended for new CDC jobs that involve tables that do not have primary keys.
Existing CDC jobs continue to use the hash-based identifier by default to maintain backward compatibility.
Warning: Reorganizing the source table resets the RRN values for all rows. This change invalidates previously generated _cdatasync_id values because they no longer correspond to the same physical rows. To correct this issue, you must perform a full re-sync of the affected tables. For details, see Re-Syncing Job Task Execution.