
Pushdownは、データ処理をデータソースに近づける最適化手法です。例えば、WHERE句でフィルタリングされたデータベースへのクエリを想像してみてください。Pushdown が起こらない場合、CData Virtuality はすべてのデータをメモリに読み込んで、フィルタに該当しない行を削除しなければなりません。一方、プッシュダウンが発生した場合、WHERE句がデータソースのRDBMS で直接適用され、フィルタに適用される行のみが配信されます。ここでのパフォーマンスへの影響は、CData Virtuality でのデータ転送と処理時間が少なくて済むことです。
PushdownはFunction、Criteria、Join、Aggregationで使用できます。利用可能な Pushdown の設定はデータ Sources によって異なり、ドライバーと TRANSLATION の機能によって制限されます。
クエリプランでPushdownを識別するには、一般的にSource Accessノードで示されます:
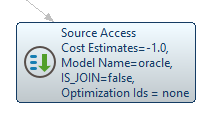
このノードをダブルクリックすると、CData Virtuality がソースに送信していたクエリ(DV SQL で、データソース側で実際に実行されたクエリではない)などの追加情報が表示されます:
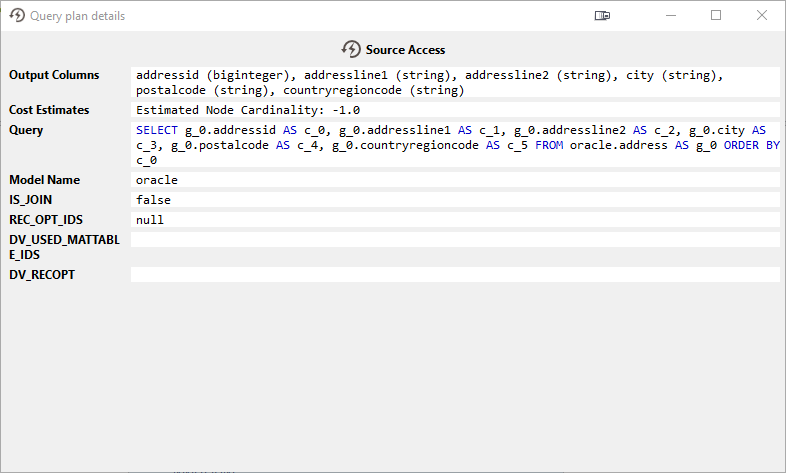
この例では、User Queryに設定されていないにもかかわらず、結果セットがソートされていることがわかります。CData Virtuality は、処理の次の処理ステップで効率的に結合できるように、ソートを自動的に適用(プッシュダウン)しました。
どのデータソースに対しても、このデータソースがさまざまな操作の Pushdown を処理する能力は、CData Virtuality Sources 内のいわゆるtranslator によって定義されます。しかし、これらの機能の多くは、特にリレーショナル・データベースの場合、hereに記載されている手動設定を使用して上書きすることができます。