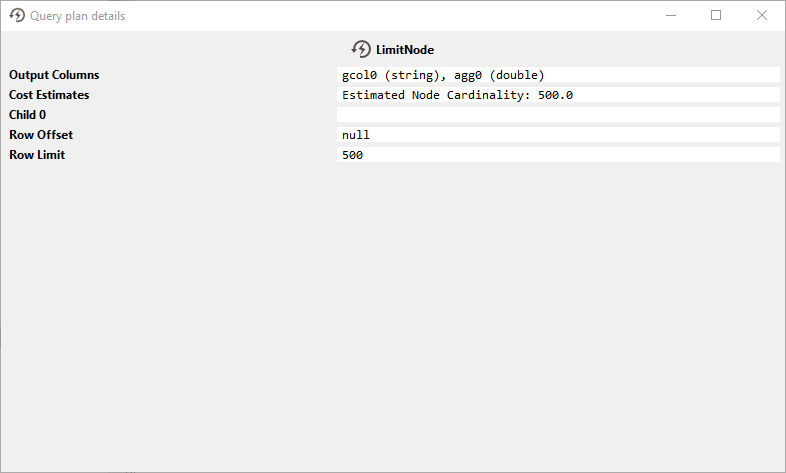
この例では、クエリはGROUP BY、SUM:
SELECT "ProductID" ,sum ("UnitPrice")FROM "mssql_advworks_2019.AdventureWorks2019.Sales.SalesOrderDetail"GROUP BY "ProductID" LIMIT 500;;MS SQLは両方の操作をサポートしているため、クエリ全体がデータソースにプッシュダウンされます。これは、Query Plansを検査することで確認できます。
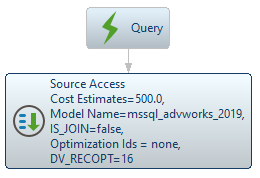
次の例では、クエリはGROUP BY、SUM、ORDER BYの同様の操作を実行していますが、これらの操作をネイティブにサポートしていない別のデータソースに対して実行しています:
SELECT "salespersonid" ,sum(CAST("totaldue" AS float)) AS "totaldue"FROM "no_pushdown_sum.SalesOrderHeader_All"GROUP BY "salespersonid"ORDER BY "salespersonid" LIMIT 500;;クエリプランを見てみると、大きく異なっていることがわかります:
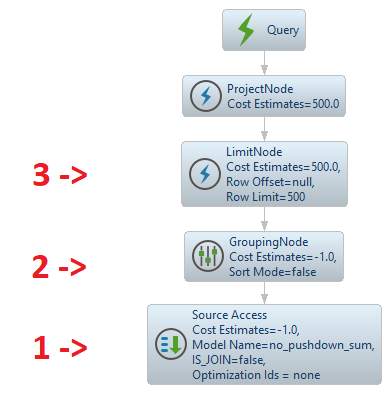
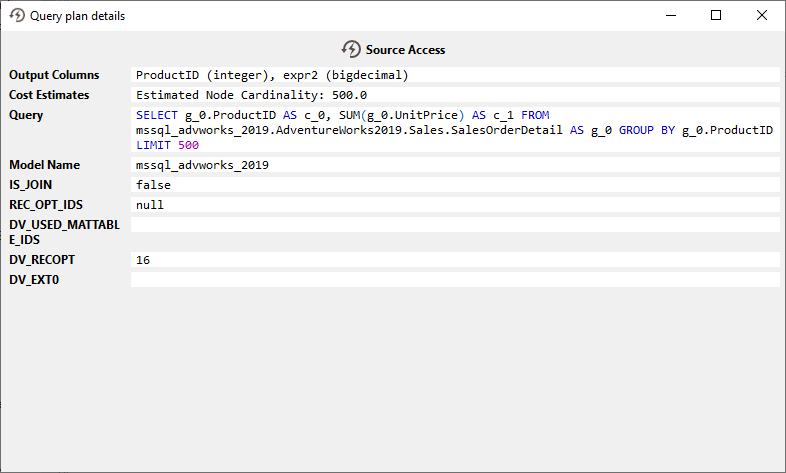
1の詳細なQuery Plansを以下に示します。データソースはGROUP BYもSUMも実装していないため、最初のステップはCData Virtualityにすべてのデータを読み込むことです:
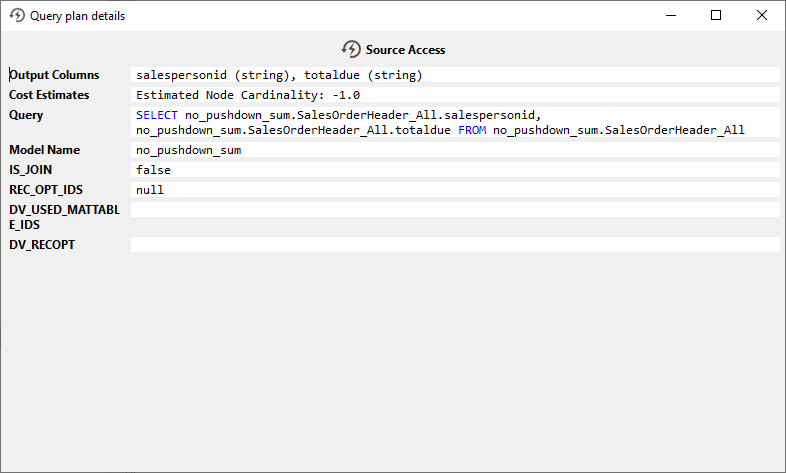
ステップ#2では、CData Virtuality がメモリ内でグループ化と集計を実行します:
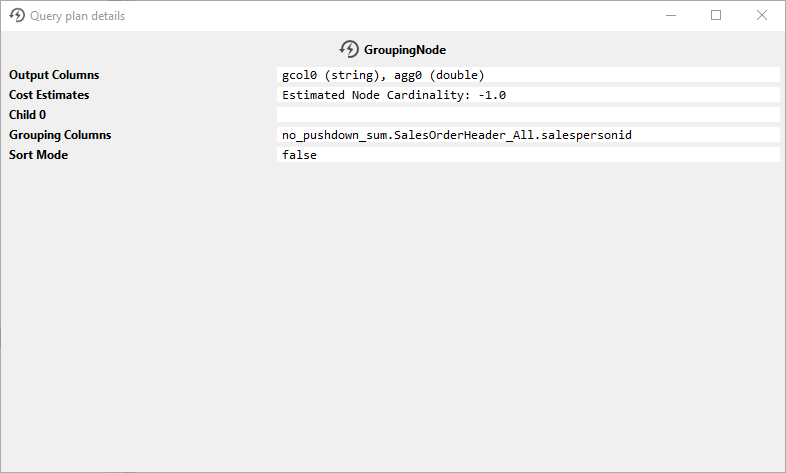
ステップ#3では、CData Virtuality がクエリのLIMIT 500: