
Google BigQuery is a fully managed cloud data warehouse for analytics. When Google BigQuery works in conjunction with Google Storage for interactive analysis of massively large data sets, it can scan TeraBytes in seconds and PetaBytes in minutes.
Type Name
bigquery
Connection Properties
Template name: bigquery
Appropriate translator name: bigquery
Properties:
projectId(required)transformQuery(default:TRUE); (obsolete)credentialFactory(default:com.datavirtuality.dv.core.oauth.credential.BigQueryOAuthCredentialFactory)allowLargeResults (obsolete)largeResultsDefaultDatasettableMaxResultsfetchSizerefreshTokenaccessTokenexpirationTimeMillisecondsregionauthCoderedirectUriuser-name(required)password(default: empty)ClientIdClientSecretdriver(default:bigquery)driver-class(default:com.datavirtuality.jdbc.bq.BQDriver)storageProjectId(default: empty)storageUser(default: empty)storagePassword(default: empty)new-connection-sqlcheck-valid-connection-sql(default:select 1)min-pool-size(default:2)max-pool-size(default:70)readTimeout(default:20000,0for an infinite, a negative for the default)connectTimeout20000,0for an infinite, a negative for the default)
Here is an example:
CALL SYSADMIN.createConnection('bq2','bigquery','projectId=XXXX,[email protected],password=$${jboss.server.config.dir}/../deployments/bigquery.p12') ;;CALL SYSADMIN.createDatasource('bq2','bigquery','importer.useFullSchemaName=false,importer.useCatalogName=false','supportsNativeQueries=true,uploadMode=CLOUDSTORAGE,bucketName=dv_upload_bucket,useDdl=false') ;;It is highly recommended to specify a bucketName when creating a BigQuery data source because of the following:
- a bucket creation limit that can be exceeded while performing multiple data inserts. Please refer to the Google Cloudstorage documentation for detailed information;
- region mismatch between a BigQuery data set and a temporary bucket which may cause errors while inserting data. Please, refer to the Google BigQuery documentation for more details.
Translator Properties
Translator Properties Shared by All JDBC Connectors
(Properties listed in alphabetical order)
To view the full table, click the expand button in its top right corner
Name | Description | Default value |
|---|---|---|
| Sets a template to convert Examples comparisonStringConversion=%s-- no conversion will be appliedcomparisonStringConversion=binary %s-- WHERE binary someStringExpression LIKE someOtherStringExpressioncomparisonStringConversion=(%s COLLATE Latin1_General_CS_AS)-- WHERE (someStringExpression COLLATE Latin1_General_CS_AS LIKE someOtherStringExpression) |
|
| Database time zone, used when fetching date, time, or timestamp values | System default time zone |
| Specific database version, used to fine-tune pushdown support | Automatically detected by the server through the data source JDBC driver, if possible |
| Only considered when |
|
| If |
|
| Maximum size of prepared insert batch |
|
| Sets a template to convert Examples OrderByStringConversion=%s-- no conversion will be appliedOrderByStringConversion=(binary %s)-- ORDER BY (binary someStringExpression)OrderByStringConversion=cast((%s) as varchar(2000) ccsid 1208)-- ORDER BY cast((someStringExpression) as varchar(2000) ccsid 1208) |
|
| If |
|
| Forces a translator to issue a Example SELECT x.* FROM table ( CALL "dwh.native"("request" => 'SELECT query, pid, elapsed, substring FROM svl_qlog ORDER BY STARTTIME DESC LIMIT 200') ) w , ARRAYTABLE( w.tuple COLUMNS query string, pid integer , elapsed string, "substring" string ) x; |
|
| If If |
|
| If If |
|
| If |
|
| if |
|
| Embeds a / comment / leading comment with session/request id in the source SQL query for informational purposes |
|
The names of the translator properties are case-sensitive.
Translator Properties Specific for Google BigQuery
To view the full table, click the expand button in its top right corner
Name | Description | Default value |
|---|---|---|
| String property. If set, the translator replaces all null characters in strings before executing | Single space |
| Values:
|
|
| Value: bucket name Only for the default ( | |
| Value: bucket prefix Only for the default ( | |
| Value: name of a folder in a bucket Only for the default ( | |
| Value: boolean If |
|
| If set to If set to |
|
Data Source Properties
Data Source Properties Shared by All JDBC Connectors
(Properties listed in alphabetical order)
To view the full table, click the expand button in its top right corner
Name | Description | Default |
|---|---|---|
| Replaces |
|
| Database catalogs to use. Can be used if the Only for Microsoft SQL Server and Snowflake:
| Exasol: EXA_DBAll others: empty |
importer.defaultCatalog |
| |
|
Please note that writing into a data source is only possible if this parameter is set. | Empty |
| Turns on metadata cache for a single data source even when the global option is turned off. Together with |
|
| Case-insensitive regular expression that will exclude a matching fully qualified procedure name from import | Empty |
| Comma-separated list of schemas (no | Oracle: APEX_PUBLIC_USER,DIP,FLOWS_040100,FLOWS_020100,FLOWS_FILES,MDDATA,ORACLE_OCM,SPATIAL_CSW_ADMIN_USR,SPATIAL_WFS_ADMIN_USR,XS$NULL,BI,HR,OE,PM,IX,SH,SYS,SYSTEM,MDSYS,CTXSYSAll others: empty |
| Case-insensitive regular expression that will exclude a matching fully qualified table name from import. Does not speed up metadata loading. Here are some examples: 1. Excluding all tables in the (source) schemas importer.excludeTables=(.*[.]sys[.].*|.*[.]INFORMATION_SCHEMA[.].*)2. Excluding all tables except the ones starting with "public.br" and "public.mk" using a negative lookahead: importer.excludeTables=(?!public\.(br|mk)).*3. Excluding "tablename11" from the list ["tablename1", "tablename11", "company", "companies"]: importer.excludeTables=.*\.(?!\btablename1\b|\bcompan).*
| Empty |
| Fetch size assigned to a resultset on loading metadata | No default value |
| If set to |
|
| If set to |
|
| If set to |
|
| If set to Please note that it is currently not possible to import procedures which use the same name for more than one parameter (e.g. same name for |
|
| Set to |
|
| If set to |
|
| If set to |
|
| Procedure(s) to import. If omitted, all procedures will be imported. | Empty |
| If set to |
|
| If set to |
|
| If set to |
|
| If set to |
|
| Schema(s) to import. If omitted or has "" value, all schemas will be imported. | Empty |
| If set to |
|
| Table(s) to import. If omitted, all tables will be imported. | Empty |
| Comma-separated list (without spaces) of table types to import. Available types depend on the DBMS. Usual format: Other typical types are | Empty |
| If set to | |
| If set to Please note that this may lead to objects with duplicate names when importing from multiple schemas, which results in an exception |
|
| If set to |
|
| If set to |
|
Creating/Dropping Tables and Inserting Data
In order to create/drop tables and insert data into a BigQeury data source, the importer.defaultSchema data source property should be set to the name of the target dataset. Here is an example:
CALL SYSADMIN.createConnection(name => 'bq', jbossCliTemplateName => 'bigquery', connectionOrResourceAdapterProperties => 'projectId=XXXX,[email protected],password=PATH_TO_KEY_FILE') ;;CALL SYSADMIN.createDatasource(name => 'bq', translator => 'bigquery', modelProperties => 'importer.useCatalogName=false,importer.defaultSchema=TARGET_DATA_SET,importer.schemaPattern=SCHEMA_PATTERN_INCLUDING_TARGET_DATASET,importer.useFullSchemaName=false') ;;Segmenting with Partitioned Tables
The BigQuery partitioning functionality is supported in both API and DDL (useDdl=TRUE) modes.
Partitioning is supported via the OPTIONS clause.
Types of Partitioning
Integer range partitioning
You can partition a table based on ranges of values in a specific INTEGER column.
Time-unit column partitioning
You can partition a table on a DATE or TIMESTAMP column in the table.
For the TIMESTAMP column, the partitions can have either hourly, daily, monthly, or yearly granularity. For DATE columns, the partitions can have daily, monthly, or yearly granularity. Partitions boundaries are based on UTC time.
Ingestion time partitioning
Valid only for DDL mode.
An ingestion-time partitioned table has a pseudocolumn named _PARTITIONTIME. The value of this column is the ingestion time for each row, truncated to the partition boundary (such as hourly or daily). Instead of using _PARTITIONTIME, you can also use _PARTITIONDATE. The _PARTITIONDATE pseudocolumn contains the UTC date corresponding to the value in the _PARTITIONTIME pseudocolumn.
You can choose hourly, daily, monthly, or yearly granularity for the partitions.
Partitioning Options
partition_expiration_days
When you create a table partitioned by ingestion time or time-unit column, you can specify a partition expiration. This setting specifies how long BigQuery keeps the data in each partition. The setting applies to all partitions in the table, but is calculated independently for each partition based on the partition time.
Accepts FLOAT values.
require_partition_filter
Specifies whether queries on this table must include a a predicate filter that filters on the partitioning column. The default value is FALSE.
partition_expression
Partition_expression
| description | partitioning type | valid for mode |
|---|---|---|---|
| Partition by ingestion time with daily partitions | Ingestion time | DDL |
| Equivalent to | Ingestion time | DDL |
| Partition by the | Time-unit column | API/DDL |
| Partition by the | Time-unit column | API/DDL |
| Partition by the | Time-unit column | API/DDL |
| Partition by the | Time-unit column | DDL |
| Partition by ingestion time with the specified partitioning type | Ingestion time | DDL |
| Partition by the | Time-unit column | API/DDL |
| Partition by an integer column with the specified range, where:
| Integer range | API/DDL |
Examples
1. Partitioning by the DATE column with daily granularity, keeping data for 3 days in partition and required filter that filters on the partitioning column for querying from table which means that the select query should contains where clause with DATE column:
CREATE TABLE bigquery.partition1 (i INTEGER, d DATE, s STRING) OPTIONS (partition_by 'd',partition_expiration_days '3', require_partition_filter 'true') ;;2. Creating a table partitioned on a timestamp range with monthly granularity:
CREATE TABLE bigquery_ddl.partition_ddl_date (i integer, d timestamp, s string) OPTIONS (partition_by 'DATE_TRUNC(d, MONTH)') ;;3. Creating a table partitioned on integer range required filter that filters on the partitioning column for querying from table which means that the SELECT query should contains where clause with the INTEGER column:
CREATE TABLE bigquery_ddl.partition_ddl_integer (i integer, d timestamp, s string) OPTIONS (partition_by 'RANGE_BUCKET(i, GENERATE_ARRAY(0, 100, 10))', require_partition_filter 'true') ;;Partitioning options and integer-range, date-unit partitioning for API mode are available since v4.10
Clustering
Clustering is supported via the OPTIONS clause:
CREATE TABLE bigquery.cluster (i integer, d date, ts timestamp, s string, b boolean) OPTIONS (cluster_by 'i,d,ts,s') ;;Partitioning and Clustering for Materialization of Recommended Optimizations
Materialized tables in BigQuery can be partitioned and clustered using the SYSADMIN.createCreationParam procedure.
Parameter keys:
partition_bycluster_bypartition_expiration_daysrequire_partition_filter
Example
-- Add "partition_by" creation parameterCALL "SYSADMIN.createCreationParam"("recOptId" => 1,"paramKey" => 'partition_by',"paramValue" => 'RANGE_BUCKET(i, GENERATE_ARRAY(0, 100, 10))');;-- Add "require_partition_filter" creation parameterCALL "SYSADMIN.createCreationParam"("recOptId" => 1,"paramKey" => 'require_partition_filter',"paramValue" => true);;For the recommended optimization with an ID equal to 1 a materialized table will be created with partitioning as in the following example:
CREATE TABLE bigquery_ddl.partition_ddl_integer (i integer, d timestamp, s string) OPTIONS (partition_by 'RANGE_BUCKET(i, GENERATE_ARRAY(0, 100, 10))', require_partition_filter 'true') ;;Configuring 3-legged OAuth for BigQuery
To set up 3-legged OAuth with BigQuery, follow these steps:
1. Log in to the Developer Console for your BigQuery project.
2. Generate new OAuth2 credentials (a pair of CLIENT_ID and CLIENT_SECRET keys).
3. Substitute CLIENT_ID in the link below with your CLIENT_ID and follow this link in the browser:
4. Choose 'Allow' to provide access:
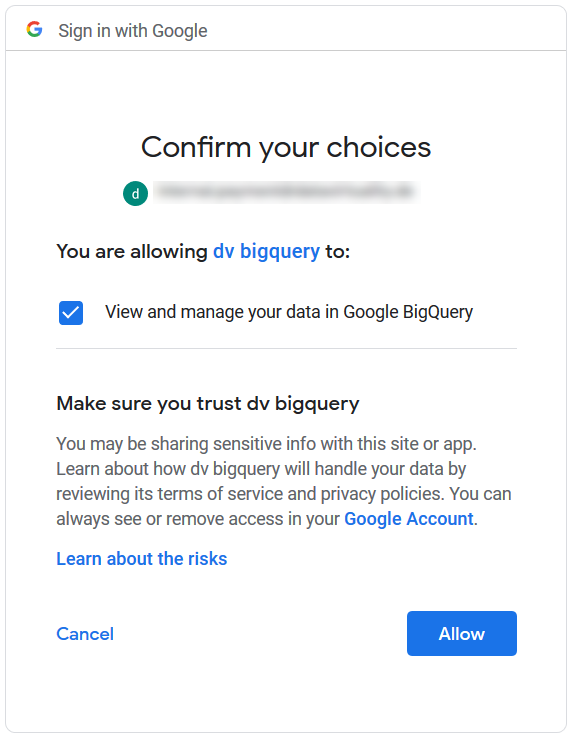
5. You will be redirected to a non-existent page, which is correct. Copy the page URL to obtain the code:
![]() The OAuth code is only valid for 10 minutes
The OAuth code is only valid for 10 minutes
|
6. Create a data source using the CLIENT_ID and CLIENT_SECRET obtained in step 3, AUTH_CODE obtained in step 5, and PROJECT_ID of your BigQuery project. The redirectUrl should be the same as in steps 3 and 5:
CALL SYSADMIN.createConnection('bq3legged','bigquery','authType=OAUTH,projectId=PROJECT_ID ,authCode=AUTH_CODE ,redirectUri=http%3A%2F%2Flocalhost%3A9000%2Fredirect.html%3Fto%3Dconnect/bigquery/oauth,user-name=CLIENT_ID,password=CLIENT_SECRET') ;;CALL SYSADMIN.createDatasource('bq3legged','bigquery','importer.schemaPattern=bq_schema_pattern,importer.defaultSchema=bq_schema, importer.useFullSchemaName=false,importer.useCatalogName=false','supportsNativeQueries=true') ;;See Also
Partitioning Tables in BigQuery to learn how to convert a non-partitioned table into a partitioned one for improved query performance