
upsertプロシージャは、Analytical Storage に格納されたテーブルにソーステーブルを簡単に複製する方法を提供することを目的としています。これは、既存の行に対してUPDATE、新しい行に対してINSERT操作を実行できるため、完全レプリケーションや増分レプリケーションよりも洗練されたアプローチです。履歴更新とは異なり、キー列の値が異なる行に複数のエントリが存在することはありません。履歴更新に自動的に追加されるような、追加のタイムスタンプカラムは作成されません。
Parameters
To view the full table, click the expand button in its top right corner
Parameter | Type | Description |
|---|---|---|
| string | Target table (analytical storage/data source) the data will be put into. Should have the defined |
| string | Source object (analytical storage/data source) the data will come from |
| object | Key columns to decide whether |
| object | Set of columns which is used to determine which columns will be updated on existing rows |
| boolean | Determines which columns exactly will be updated depending on the value:
|
| string | Determines how to calculate the surrogate key depending on the value:
|
| string | If |
| string | Redshift table creation options ( |
| string | Check field or expression in update statement |
| string | Default value if check field or expression variable is |
Principle of Operation
このプロシージャは、指定されたソース ( source_table ) から現在のデータを取得し、そのデータを ローカルテーブル ( target_table / dwh_table ) に配置します。INSERTとUPDATEのどちらが使用されるかは、 キーカラム ( keyColumnsArray ) の設定に基づいて決定されます。ソース行のそれぞれについて、以下の 操作が実行されます:
キーカラムに同じ値を持つ行がない場合、
INSERT、新しい行が分析ストレージテーブルに追加されます;そうでない場合、分析ストレージテーブルの既存の行は、
updateColumns、invertUpdateColumns、次のようにパラメータに基づいて更新されます。invertUpdateColumns=FALSE:updateColumnsのすべてのカラムが更新されます。invertUpdateColumns=TRUE:updateColumnsの列を除くすべての列が更新されます。
keyColumnsArrayの列をcolumnsToCheckArrayに列挙することはできません。また、列が更新されることもありません。これは、行がまったく新しいエンティティを表すように変更されてしまうからです。
How It Works
upsert Updateを設定します:
Web UI で Replication ジョブを追加するには、次の手順を実行します:
Web UI でReplication Job ダイアログを開き、Optimization メニューに進みます。
Create New Jobをクリックし、Create Replication Jobをクリックします:
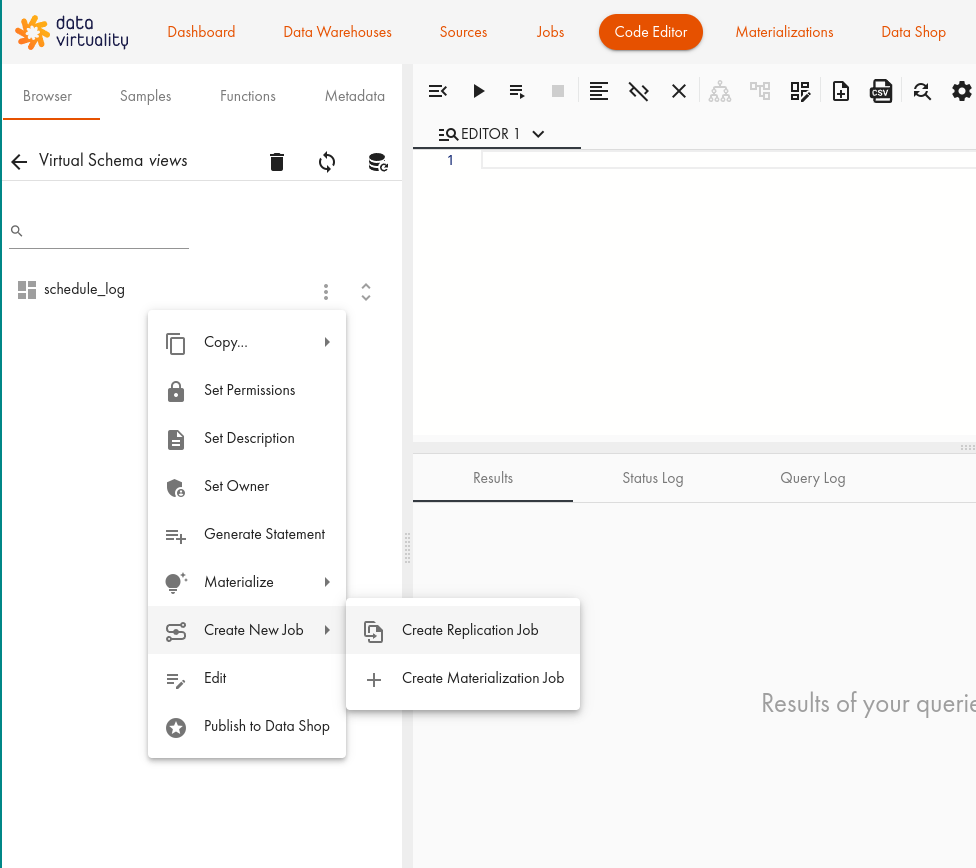
- ダイアログで、Upsert Updateタブを選択します:
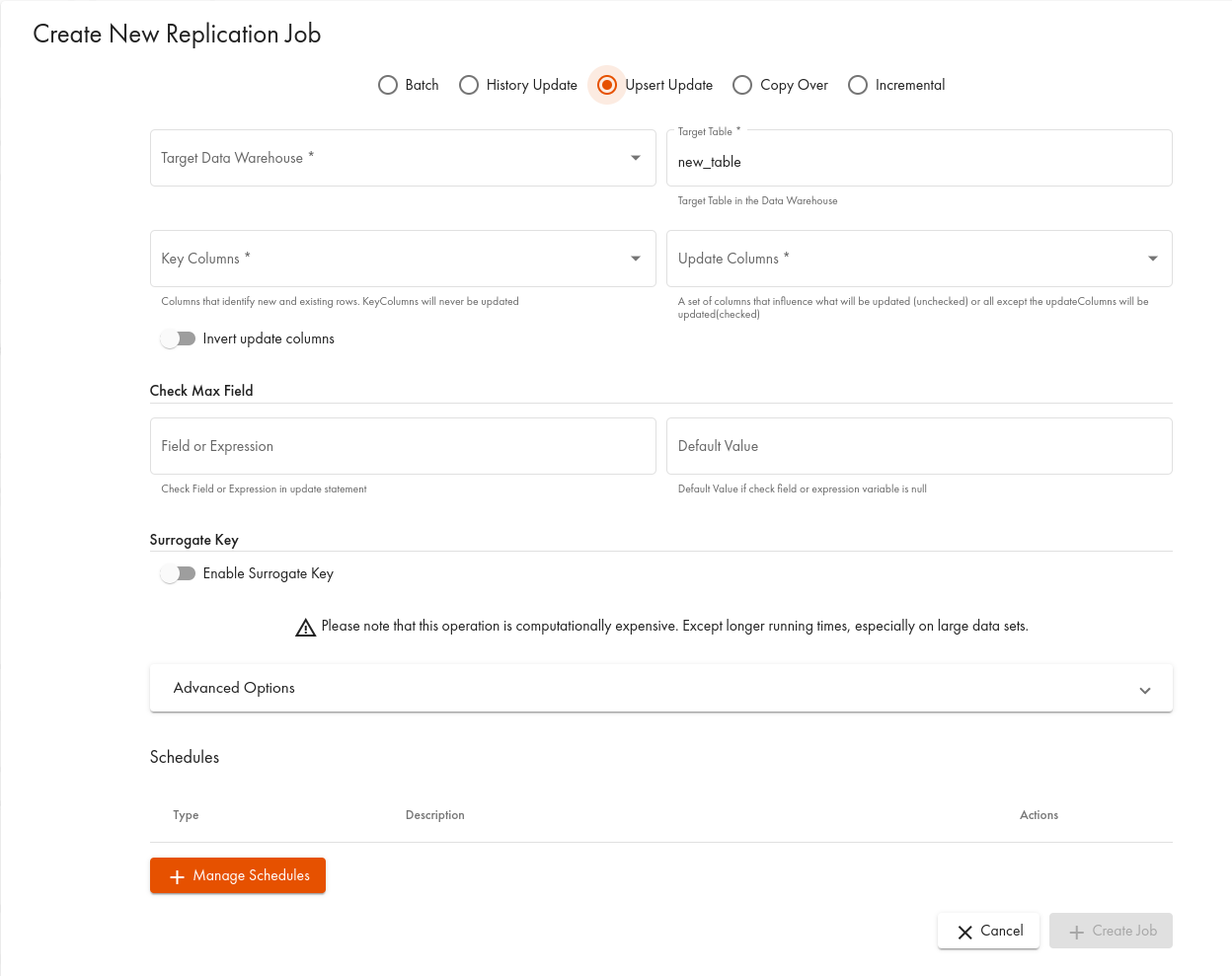
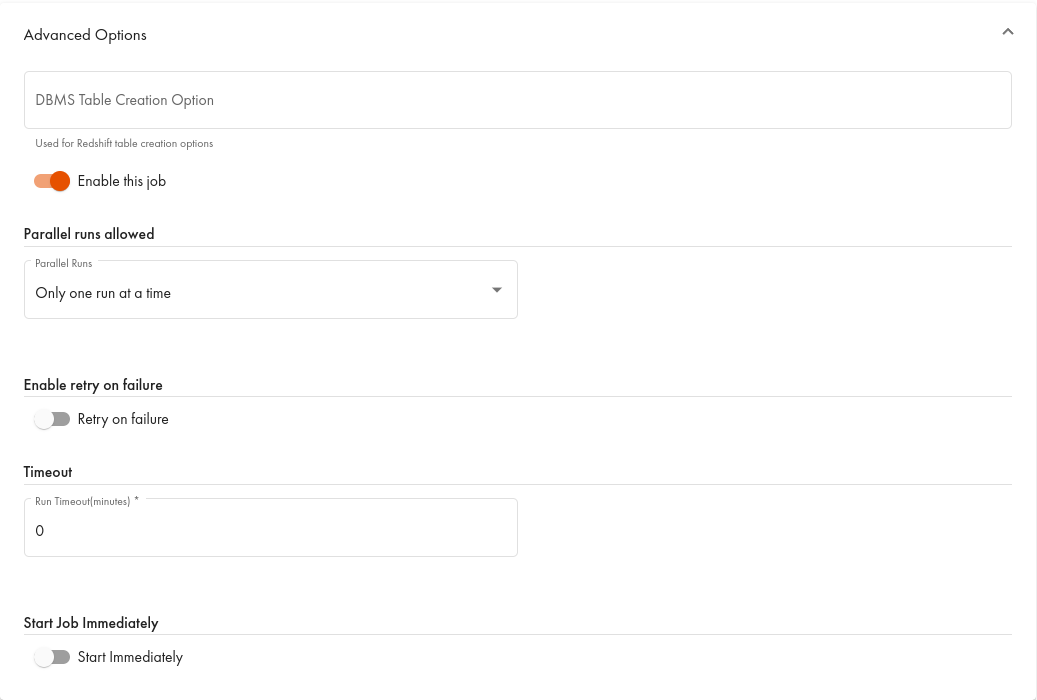
Examples
1. ソーステーブルに対してUpsert操作を実行し、指定された列のみを更新しながら、これらの行をターゲットテーブルに「Upsert」します:
CALL "UTILS.upsert" ( "target_table" => 'dwh.foo' , "source_table" => 'ds.bar' , "keyColumnsArray" => ARRAY('MyID') , "updateColumns " => ARRAY('col1', col2') , "invertUpdateColumns " => FALSE ) ;;この呼び出しは、ソーステーブルds.barに対して upsert 操作を実行し、これらの行をテーブルdwh.fooに「upsert」します。MyID列は、dwh.fooのどの行に挿入し、どの行を更新する必要があるかを識別するために使用されます。更新が実行された場合、col1、col2列のみが更新され、その他の列は変更されません。
2. ソーステーブルに対してUpsertオペレーションを実行し、指定された列を除くすべての列を更新しながら、これらの行をターゲットテーブルに「Upsert」します:
CALL "UTILS.upsert" ( "target_table" => 'dwh.foo' , "source_table" => 'ds.bar' , "keyColumnsArray" => ARRAY('MyID') , "updateColumns " => ARRAY('col1', col2') , "invertUpdateColumns " => TRUE ) ;;この呼び出しは、ソーステーブルds.barに対して upsert 操作を実行し、これらの行をテーブルdwh.fooに「upsert」します。MyID列は、dwh.fooのどの行に挿入し、どの行を更新する必要があるかを識別するために使用されます。更新が実行された場合、MyID、col1、col2列はそのまま残り、残りの列はすべて更新されます。これは、更新するカラムの設定が更新しないカラムの設定よりもはるかに大きい場合に便利です。
これらの例では、ターゲットテーブルのどの行を挿入/更新するかを識別するために1つの列を使用しましたが、複数の列を使用することも可能です。次の2つの例はその方法を示しています。
3. ソース・テーブル上でUpsertオペレーションを実行し、ターゲット・テーブルに挿入/更新する行を特定するために複数の列を使用して、これらの行をターゲット・テーブルに「Upsert」します:
CALL "UTILS.upsert" ( "target_table" => 'dwh.foo' , "source_table" => 'ds.bar' , "keyColumnsArray" => ARRAY('MyID', 'SomeID', 'SomeOtherID') , "updateColumns " => ARRAY('col1', col2') , "invertUpdateColumns " => TRUE ) ;;この呼び出しは、ソーステーブルds.barに対して upsert 操作を実行し、これらの行をテーブルdwh.fooに「upsert」します。MyID , SomeID , SomeOtherID列は、dwh.fooのどの行に挿入し、どの行を更新する必要があるかを識別するために使用されます。これらは一種の複合キーを形成しています。更新が実行された場合、MyID、SomeID、SomeOtherID、col1、col2のカラムはそのまま残り、残りのカラムはすべて更新されます。
4. 特殊なケース:同じ操作を実行しますが、将来的に新しい行を追加しやすくするために、データソースにカウンタを挿入します:
CALL "UTILS.upsert" ( "target_table" => 'exa.foo' , "source_table" => 'ds.bar' , "keyColumnsArray" => ARRAY('id1') , "updateColumns " => ARRAY('col1', col2') , "invertUpdateColumns " => TRUE , "surrogateKeyName" => 'SurrColumn' , "surrogateKeyType" => 'COUNTER' , "checkMaxFieldId" => 'id1' , "defaultValueIfCheckMaxFieldIsNull" => '0' ) ;;この呼び出しは、ソーステーブルds.barに対して upsert 操作を実行し、これらの行をテーブルexa.fooに「upsert」します。id1列は、exa.fooのどの行に挿入し、どの行を更新する必要があるかを識別するために使用されます。更新が実行されると、col1とcol2列が更新され、残りの列は変更されません。これは、更新するカラムの設定が更新しないカラムの設定よりもはるかに大きい場合に便利です。SurrColumnという名前のサロゲート・キーがデータ・ソースに追加されます。値はlongのインクリメンタルカウンターになります。upsertの実行中、exa.fooのid1列の最大値との比較が実行され、ds.barid1から最大値を超える行のみがupsertされます。これは、更新の必要がなく、新しい行を追加するだけでよいことがわかっている場合に便利です。
See Also
A short guide on data replication types and use cases. Incremental and Upsert Replication - Upsert Update とその使用例については、CData Virtuality ブログの投稿をご覧ください。