
場合によっては、データの変更を追跡する必要があります。Incremental、Incremental、またはBatch Replicationでは、常に利用可能なすべてのデータを含むテーブルが作成されます。IncrementalまたはBatch Updateでは、データソースに存在しなくなった「古い」データを保持できる場合があります。しかし、一般的にデータの変更を追跡することはできず、ユーザーは常に最新の情報で作業することを余儀なくされます。
データがいつ、どのように変更されたかを知る必要がある場合は、履歴更新が適切なレプリケーションタイプです。このタイプのレプリケーションを実装する方法はいくつかありますが、このページではCData Virtuality Server で使用されているタイプについて説明します。
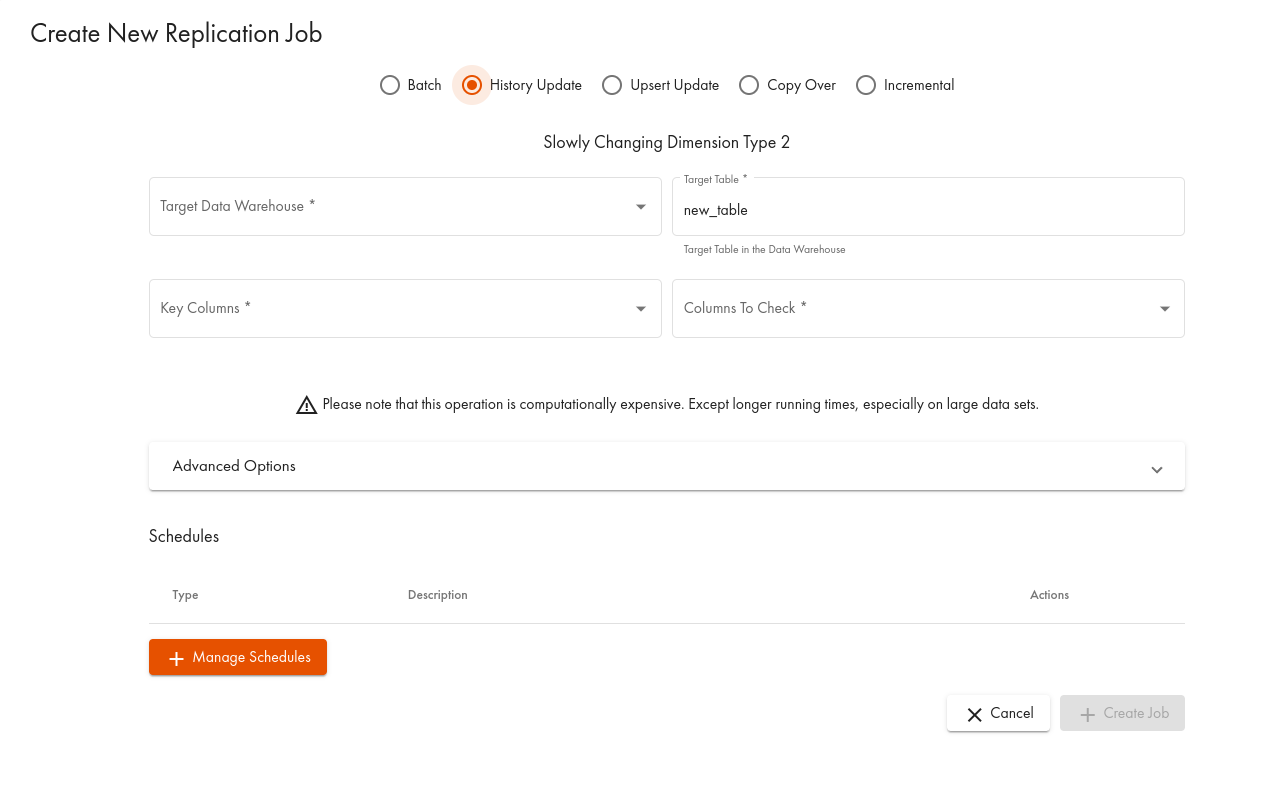
これは、ローカルに最適化されたデータが格納されている分析ストレージテーブルに2つのカラムを追加することで、データレコードに一種のバージョニングを実行することに基づいています。fromtimestampおよびtotimestampと呼ばれるこれらの列は、指定されたレコードが有効なバージョンであった期間の情報を提供します。この機能を使用するには、以下の操作が必要です:
- ソースオブジェクト(テーブルまたはビュー)のキーとなる列を選択します。フィールドは、重複(すべてのフィールドに同じ値を持つ行全体)が発生しないように選択する必要があることを覚えておいてください。
- レプリケーション・ジョブの実行時に更新を追跡する列をSELECTします。
How It Works
History Updateを設定します:
Web UI で Replication ジョブを追加するには、次の手順を実行します:
Web UI でReplication Job ダイアログを開き、Optimization メニューに進みます。
Create New Jobをクリックし、Create Replication Jobをクリックします:
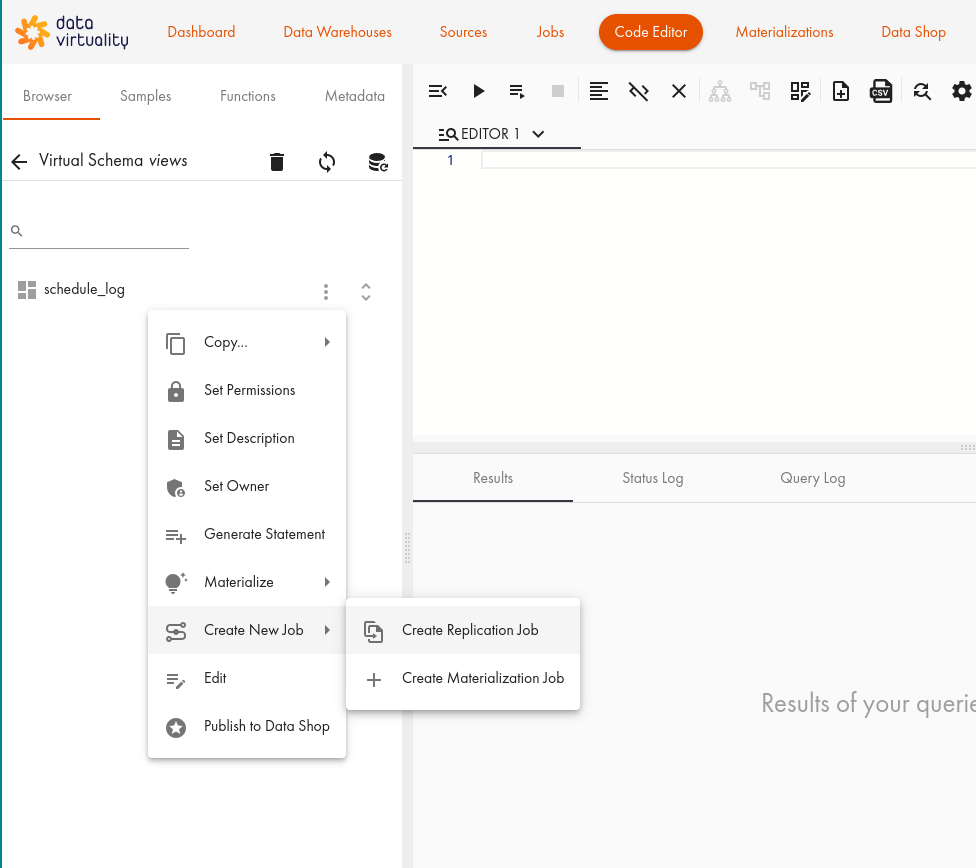
- ダイアログで、History Updateタブを選択します:
テーブルの名前はhExで、IDをキーカラムとしています。age列が既存のエントリの値を変更したときにチェックしたいのです。レプリケーション・ジョブが初めて実行された後(ここではスケジュールの追加やジョブの手動実行は省略しています)、ソース・オブジェクトの各レコードには、現在のタイムスタンプをfromtimestampとし、可能な限り大きなタイムスタンプ9999-01-01 00:00:00.0をtotimestampとした1行が存在します。
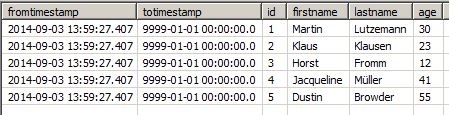
さて、通常の作業を行っている間にソースが変わり、Martin Lutzemannの年代が変わります。同じID(キー列)で異なる年齢(チェックする列)のレコードがすでにあるため、次にHistory Updateを実行すると2つ目のエントリが作成されます。Martinの最新のエントリは、ジョブ実行のタイムスタンプに設定された修正totimestamp、新しいレコードは同じfromtimestamp、特別なtotimestamp:
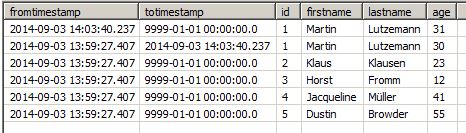
スクリーンショットに示すように、タイムスタンプ「9999-01-01- 00:00:00.0」は、これが同じキーを持つレコードの最新のものであることを示しています。
カラムがCData Virtuality Server によって監視されていない場合(つまり、チェックするカラムの1つとして選択されていない場合)、ローカルテーブルに変更はありません。これらのフィールドの変更は、追跡されたフィールドの値が変更され、それぞれのエントリの新しい「バージョン」が作成された時点で表示されます。
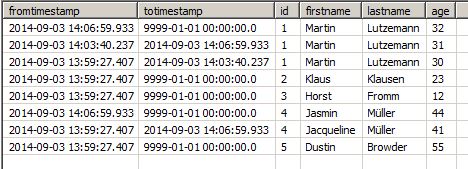
Jacqueline が名前を変更し、3 歳年を取るなど、ソースにさらに変更が加えられた場合、次の実行では新しいバージョンの記録が作成されます。トラックされたカラムがすべて変更され、多くのカラムがあったとしても、レコードの新しいバージョンはもちろん1つだけです。
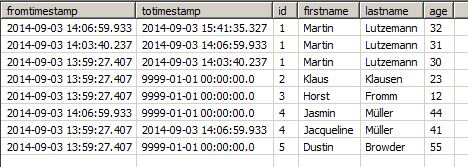
非推奨エントリがデータソースから削除されると、それらはローカルの分析ストレージテーブルに保持されますが、擬似的な無限totimestamp、適切なものを取得します。マーティン・ルツェマンがSources Tableから削除されても、History Updateには残ります:
See Also
A short guide on data replication types and use cases. History replication - 履歴レプリケーションについては、CData Virtuality ブログの投稿をご覧ください。