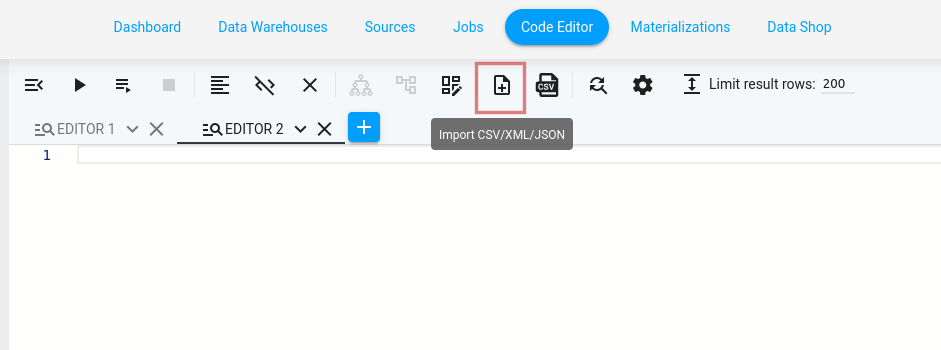
Starting the Builder
上部のアイコンバーにあるImport CSV/XML/JSON アイコンをクリックすると、Code Editor から Query Builder を起動できます:
Builder Elements
これが完全なクエリビルダーの外観です:
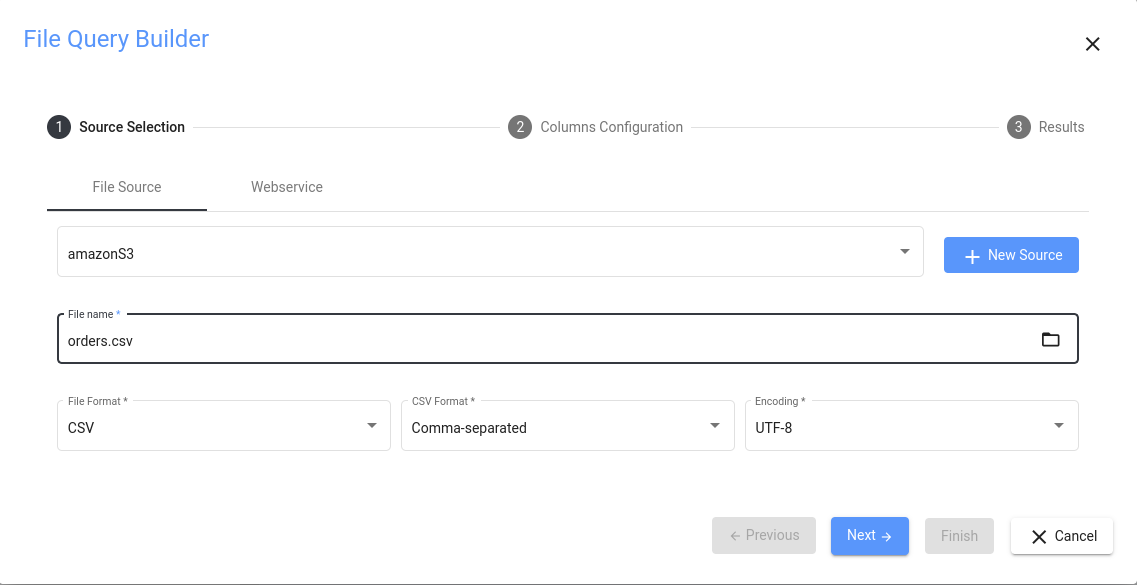
ビルダーは、以下に説明する複数のペインで構成されています。
Source Pane
ビルダーで最も重要なのはソースペインです。2つのオプションからお選びいただけます:
- File source タブを選択し、ファイルシステム内のアクセス可能なファイルからデータを取得します。これを使用するには、File タイプのデータソースが接続されていて、このディレクトリ内のファイルを読み取る適切な権限を持っていることが必要です。
- Web service タブを選択し、REST API からデータを取得します。REST API は URL 経由でデータを取得することができ、いくつかのパラメータを追加することもできます(Web Service アクセスのパラメータの設定方法については、Communicating with Web Services のセクションを参照してください)。データを取得するには、Web サービスのデータソースが必要です。
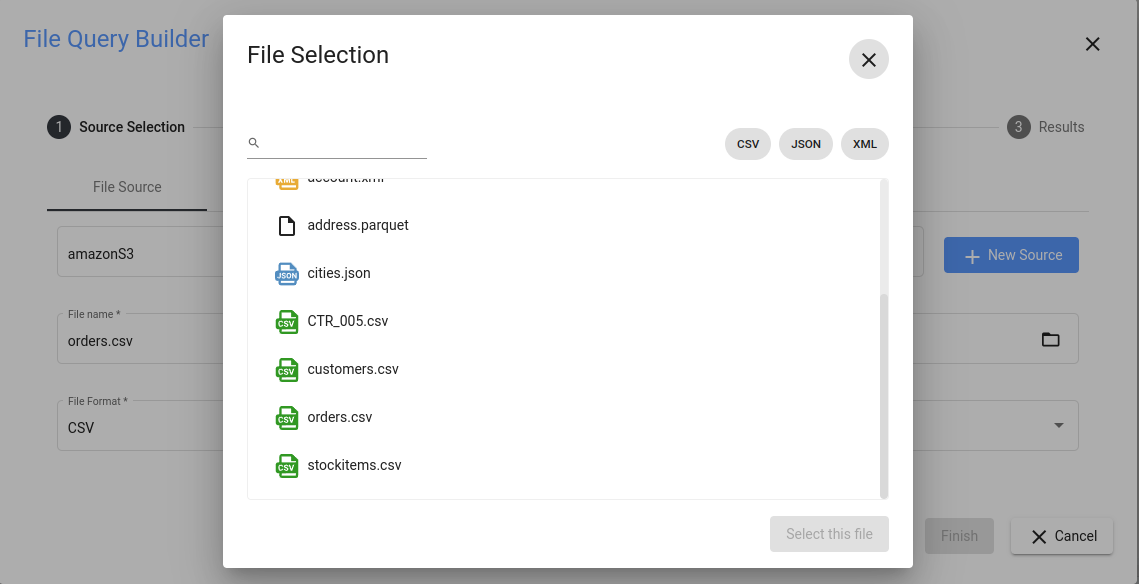
正しいデータソースを選択した後、フォルダアイコンをクリックし、開くダイアログからファイルを選択します:
Parsing
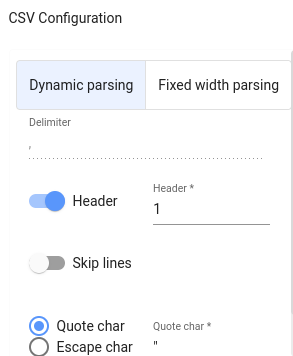
CSV データをテーブルに正しくマッピングするには、解析ペインを使用して、データの解析方法とそれに基づくテーブルの作成方法を決定するパラメータを指定します。ここで最も頻度の高い設定は以下のとおりです:
- 区切り文字(新しい列を示す文字)
- 引用 char(テキストを指定する特殊文字)
- ヘッダー(列名を含む行または行)
- スキップ行(行 x+1 から始まるデータのみインポート)
Always choose the data types for your columns carefully to avoid getting errors. The safest option is to select the type STRING if you are not sure.
Using the Query Builder to Import CSV Data
Getting the Raw Data (Source Pane)
最初のステップは、ソースから生データを取得することです(このガイドでは、ファイル・データ・ソースを使用し、ローカル・ファイルにアクセスします)。ウェブサービスからデータを取得したい場合は、まずCommunicating with Web Servicesのセクションを確認してください。
開いているSQL エディタ・タブから、下矢印のアイコンをクリックし、Open CSV Query Builder をメニューから選択して、前述のクエリ・ビルダーを起動します。あとはデータを取得する必要があります。この例では、filerというデータソースがあり、CData Virtuality Server が稼動しているシステムのファイルシステムフォルダを指していると仮定します。リストからデータソースを選択した後、フォルダアイコンをクリックし、インポートするファイルを選択します。この例で選択されているファイルは forecast_canonical.csv(hereで取得可能)で、天候情報を含んでい ます。
また、データのエンコーディングを指定する必要があります:
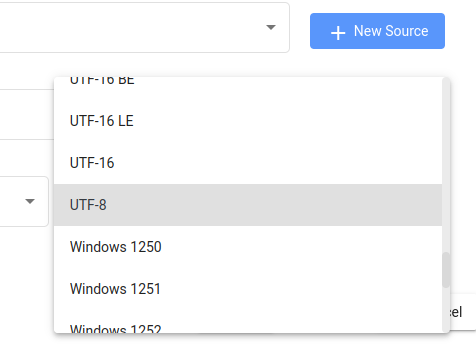
Please note that no matter how you get the desired data, you always have to specify an encoding; the most frequently used ones are UTF-8 and windows-1252.
完了したら、OK をクリックして次に進みます。
Autodetecting Columns (Column Pane and Preview Pane)
すべてが正しく選択されていれば、列ペインに移動し、アスタリスクの付いた小さなプラスアイコンをクリックします。これにより、先ほど設定した解析オプションに従って、すべてのカラムが自動的に検出されます。データの最初の行は、暗黙的に常に列名を含むとみなされることに注意してください。また、すべてのカラムはデフォルトでSTRING データ型に設定されています。プレビュー・ペインでは、結果プレビュータブに戻り、今終了したらテーブルがどのようになるかを確認できます:
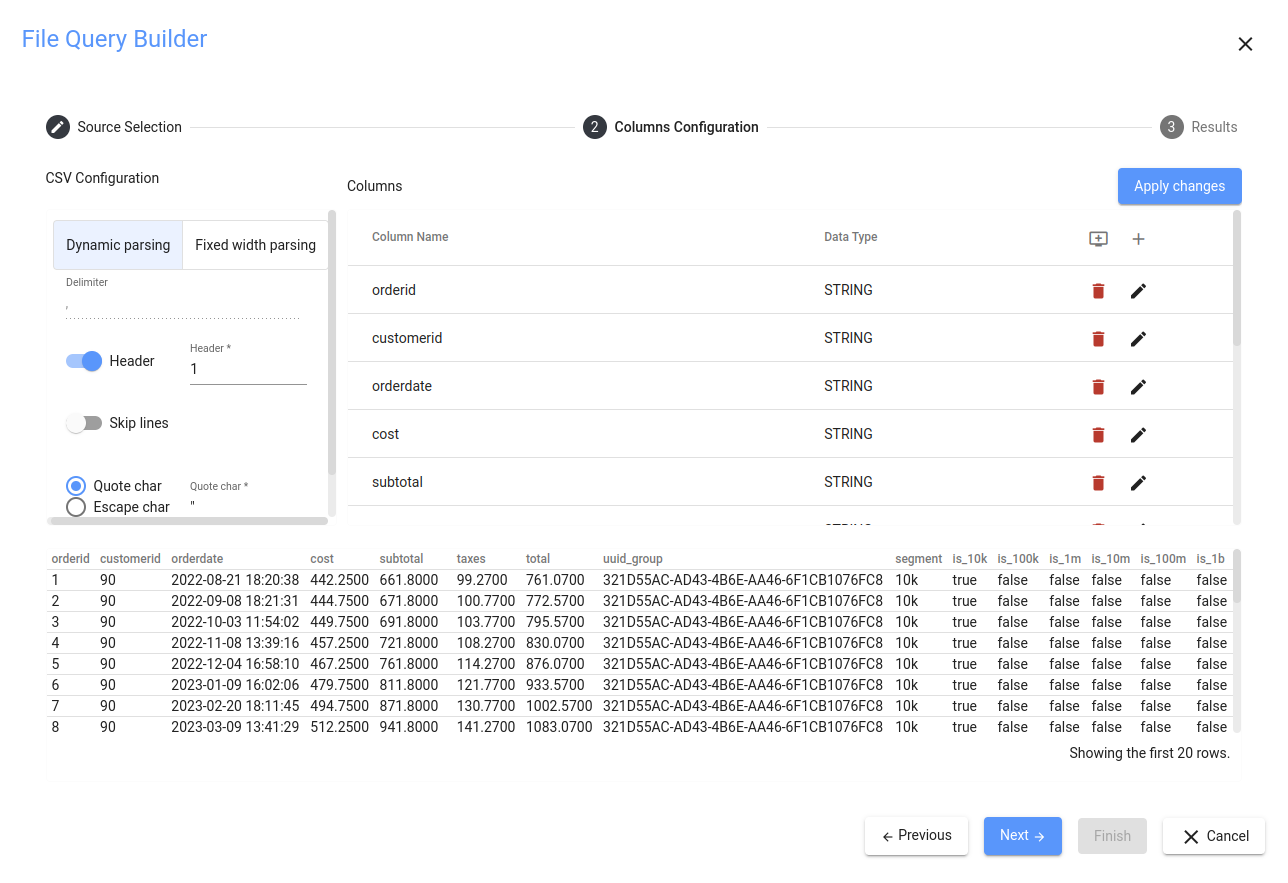
Adjusting Column Data Types (Column Pane and Parsing Pane)
列のデータ型を変更する前に、プレビュー・ペインに表示されている最初の行を削除する必要があります。この行は厳密なテキストを含んでおり、テキストベースでないものにデータをキャストしようとすると、このようなエラーで失敗します: 
解析ペインに移動し、Skip linesチェックボックスにチェックを入れ、数字が1であることを確認します。この方法では、CSVファイルの最初の行はデータとしてインポートされません:
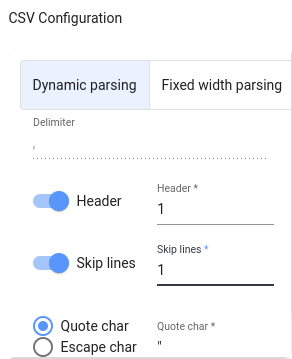
これでデータ型を自由に変更できるようになりました。
Be cautious when selecting the data types. The whole import will fail if a single data record cannot be cast to the set type. The most secure option is STRING.
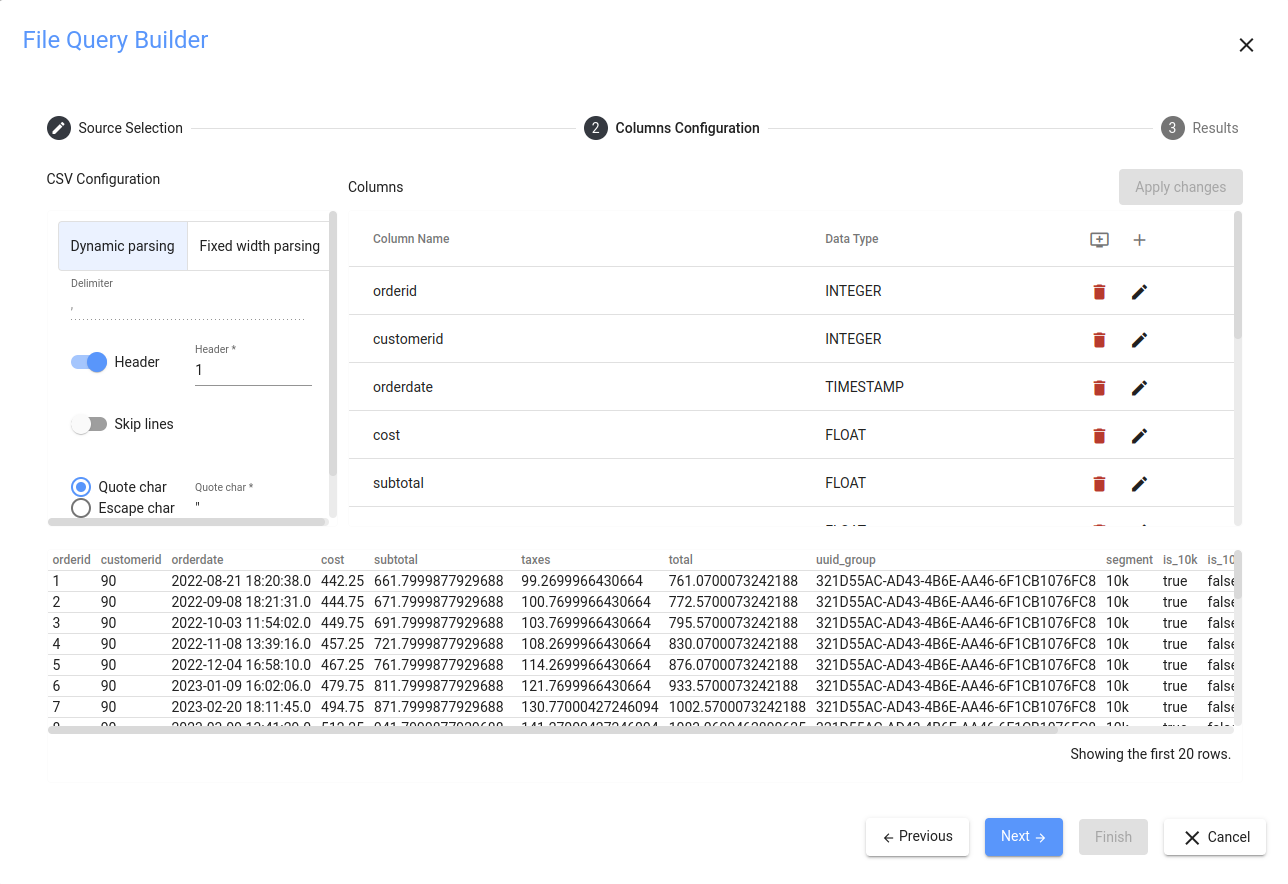
上のスクリーンショットは、サンプルのデータ型を指定する方法を示しています。
Reviewing and Finishing the Settings
これで完了です。終了する前に、すべてが正しいかどうかを再確認できます:
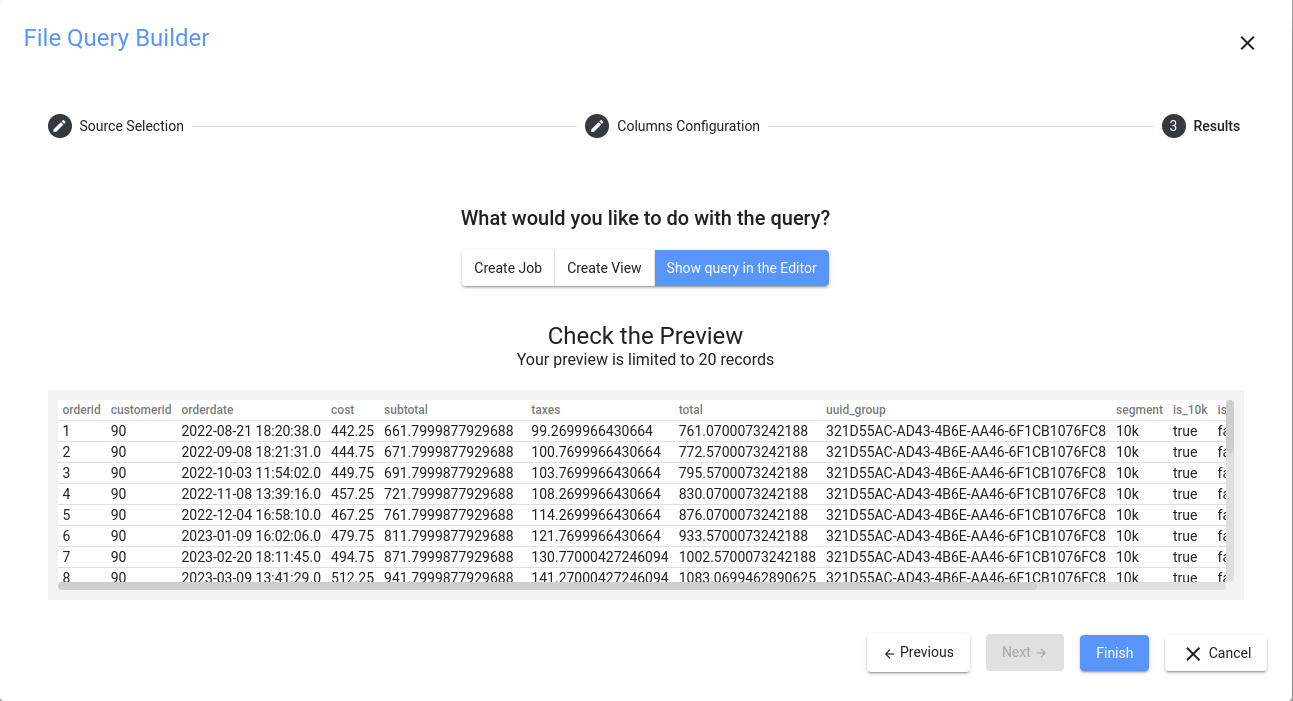
すべて問題ないので、OK をクリックして、CSV インポート用のコードを生成することを確認します。生成されたSQL ステートメントに対して以下のコードが表示されます:
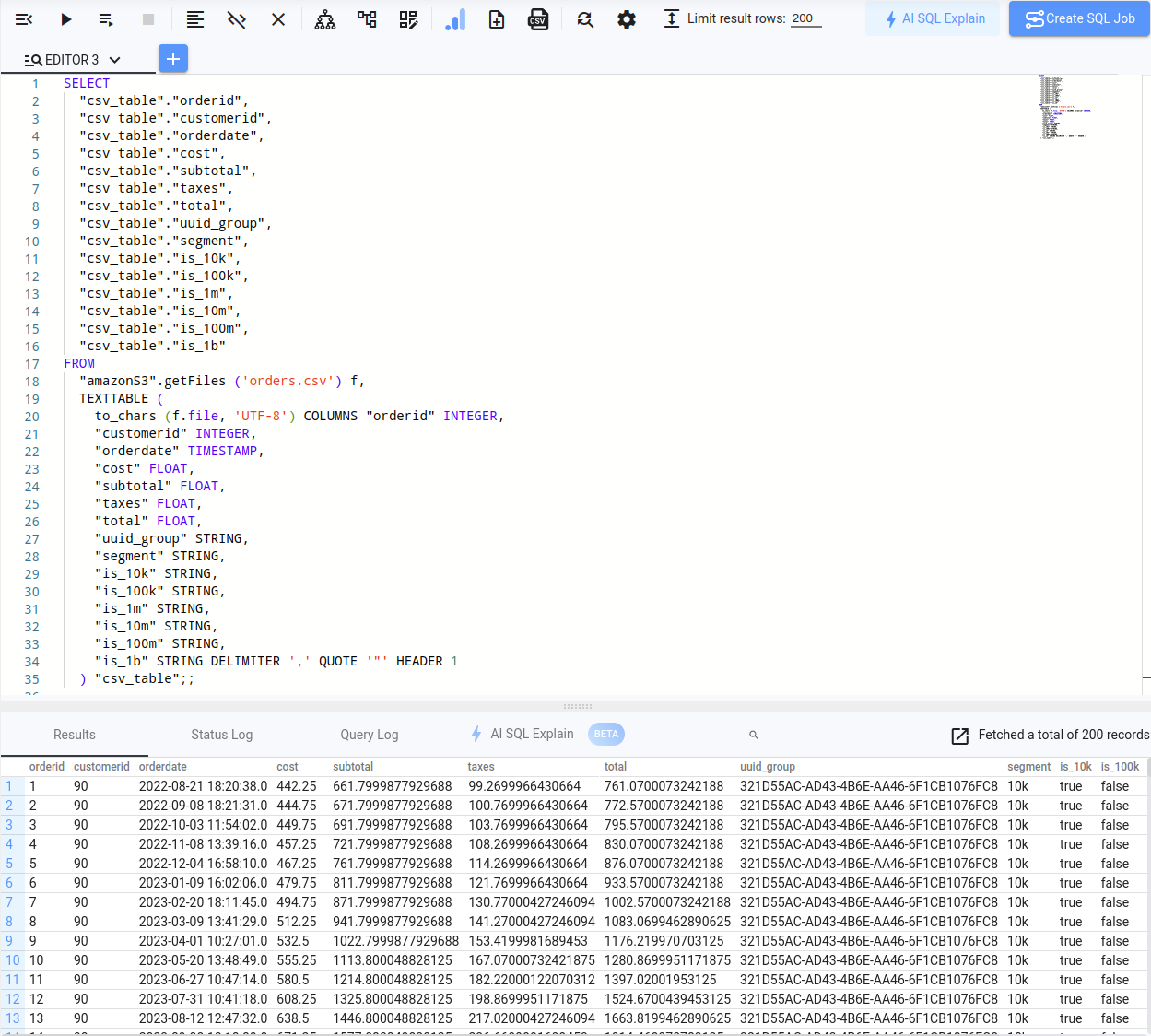
SELECT "csv_table"."orderid", "csv_table"."customerid", "csv_table"."orderdate", "csv_table"."cost", "csv_table"."subtotal", "csv_table"."taxes", "csv_table"."total", "csv_table"."uuid_group", "csv_table"."segment", "csv_table"."is_10k", "csv_table"."is_100k", "csv_table"."is_1m", "csv_table"."is_10m", "csv_table"."is_100m", "csv_table"."is_1b"FROM "amazonS3".getFiles ('orders.csv') f, TEXTTABLE ( to_chars (f.file, 'UTF-8') COLUMNS "orderid" INTEGER, "customerid" INTEGER, "orderdate" TIMESTAMP, "cost" FLOAT, "subtotal" FLOAT, "taxes" FLOAT, "total" FLOAT, "uuid_group" STRING, "segment" STRING, "is_10k" STRING, "is_100k" STRING, "is_1m" STRING, "is_10m" STRING, "is_100m" STRING, "is_1b" STRING DELIMITER ',' QUOTE '"' HEADER 1 ) "csv_table";;SELECT 句から不要な列を省略したり、組み込み関数を適用したりできるようになりました。例えば、FROM_UNIXTIME 関数を使用して、Start_Time とEnd_Time の列のデータを「実際の」タイムスタンプに変換することができます。これが最終結果です: