
クエリ エンジンは入力された SQL クエリを受け取ると、以下の処理を実行します:
- の解析 - 構文を検証し、内部形式に変換します。
- の解決 - すべての Identifiers を Metadata に、Function を関数ライブラリにリンクします。
- の検証 - メタデータ参照と型シグネチャに基づいて SQL セマンティクスを検証します。
- の書き換え - SQL を書き換えて式と条件を簡素化します。
- 論理プラン最適化 - 書き換えられた正規SQLを論理プランに変換し、詳細な最適化を行います。CData Virtuality Server オプティマイザは主にルールベースです。Query Structureとヒントに基づいて、特定のルール設定が適用されます。これらのルールは、さらに多くのルールの実行をトリガーします。CData Virtuality Server はまた、いくつかのルールで原価情報を利用します。論理プラン最適化のステップについては、Query Planner セクションで説明します。
処理計画変換 - 論理計画を、ノードが基本的な処理操作を表す実行可能な形式に変換します。最終的な処理計画はQuery Planとして表示されます。
論理クエリプランは、ソーステーブルのデータを期待される結果設定に変換する操作のツリーです。データはツリーの一番下(Tables)から一番上(Output)に流れます。主な論理操作は、select(条件に基づいて行を選択またはフィルタリング)、project(列値を投影または計算)、join、source(テーブルからデータを取得)、sort(ORDER BY)、duplicate removal(SELECT DISTINCT)、group(GROUP BY)、union(UNION)です。
例えば、1970年以降に生まれたすべてのエンジニア社員を検索する以下のクエリを考えてみましょう:
SELECT e.title, e.lastname FROM Employees AS e JOIN Departments AS d ON e.dept_id = d.dept_id WHERE year(e.birthday) >= 1970 AND d.dept_name = 'Engineering'論理的には、EmployeesテーブルとDepartmentsテーブルのデータが取得され、結合され、指定に従ってフィルタリングされ、最後に出力列が投影されます。正規のクエリプランはこのようになります:
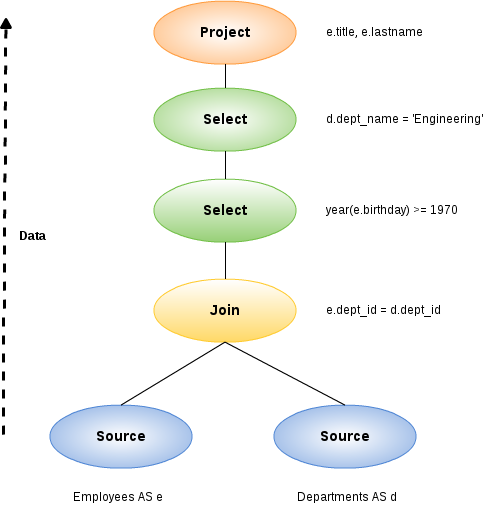
データは下部のテーブルから、結合、選択、そして最後にプロジェクトを経て、最終的な結果を生み出します。各ノード間で渡されるデータは、論理的には列と行を持つ結果セットです。
もちろん、これは論理的に起こることであり、計画がどのように実行されるかではありません。この初期計画から始めて、Query Plannerは、同じ結果をより速く取得する等価な計画を生成するために、Query計画木に対して変換を実行します。Federated Query Plannerもリレーショナルデータベースプランナーも、同じ概念と同じ計画変換の多くを扱います。この例では、DepartmentsテーブルとEmployeesテーブルのCriteriaは、できるだけ早い段階で結果をフィルタリングするために、ツリーの下にプッシュされます。
どちらの場合も、目標は可能な限り最速でクエリ結果を取得することです。しかし、リレーショナルデータベースプランナは、主にストレージからデータを引き出す際のアクセスパスをOptimizationすることでこれを行います。
対照的に、連携クエリプランナは、通常その負担をデータSourcesに押し付けるため、ストレージアクセスについてあまり懸念しません。連携されたQuery Plannerにとって最も重要なことは、データ転送を最小限にすることです。