
CData Virtuality Server には、入力されたユーザークエリを評価し、その構造を推定し、以前に発行されたクエリとの同一性をチェックするマッチングコンポーネントが含まれています。発行されたクエリのすべての構造コンポーネントを認識し、それぞれについてRecommendedOptimizationsテーブルに適切な行を格納します。
例えば、以下のクエリを考えてみましょう:
SELECT year(h.ORDERDATE),sum(d.linetotal) AS sFROM oracle_DB.SALESORDERDETAIL d JOIN adventureworks_part_three.salesorderheader h ON d.SalesOrderID=h.SalesOrderID GROUP BY year(h.ORDERDATE)ORDER BY year(h.ORDERDATE);その結果、2 つの Optimizations が推奨されます:
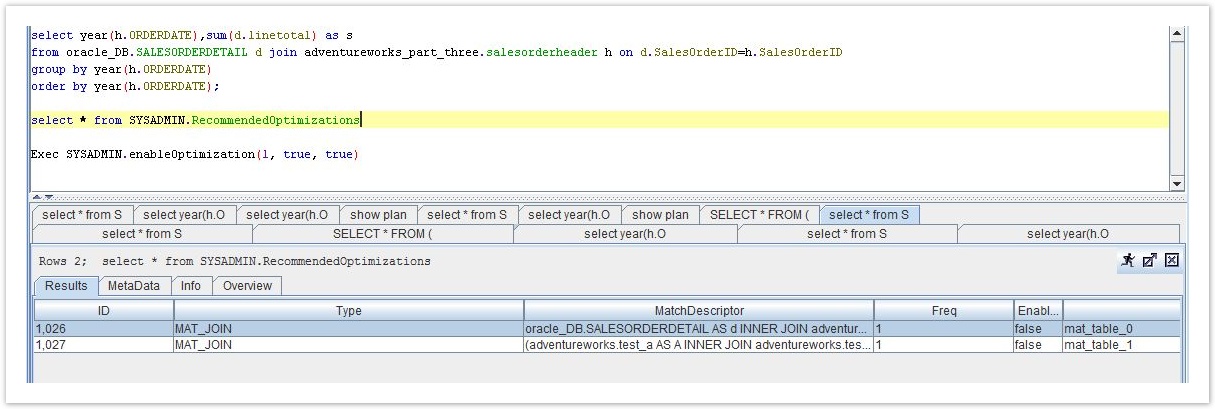
作成された推奨されるOptimizationはどちらもMAT_JOIN、クエリの適切な(サブ)構造は2つの要素のJOIN。SELECT * FROM datasourceA.tableXのような単一テーブルに対する要求が発行されたときに作成されるTABLEも推奨される最適化の一種です。
作成された2つのOptimizationの推奨頻度は1です。これは、JOINが過去に一度だけ発行されたことを意味します。元のissueを繰り返すと、Freq列のカウンタが両方とも1つ増えます。同様の構造を持つ別のリクエストも、適切なカウンタを増やします。
上記と同じクエリで、エイリアスを変えたり、JOINの側を変えたりした場合を考えてみましょう:
SELECT year(hh.ORDERDATE),sum(dd.linetotal) AS s FROM oracle_DB.SALESORDERDETAIL dd JOIN adventureworks_part_three.salesorderheader hh ON dd.SalesOrderID=hh.SalesOrderID GROUP BY year(hh.ORDERDATE) ORDER BY year(hh.ORDERDATE);SELECT year(h.ORDERDATE),sum(d.linetotal) AS sFROM adventureworks_part_three.salesorderheader h JOIN oracle_DB.SALESORDERDETAIL d ON d.SalesOrderID=h.SalesOrderIDGROUP BY year(h.ORDERDATE)ORDER BY year(h.ORDERDATE);特定のクエリの構造は変わらず、適切なカウンタは増加し、追加の推奨最適化は作成されません。