
CData Virtuality Server at a Glance
CData Virtuality Server は、複数の異種データソースを1つの統合プラットフォームで結合できる、シンプルかつ強力なツールを提供します。完全に動的なアプローチにより、異なるデータソースのスキーマを自動検出することで、時間のかかるETLプロセスに関与することなく、分析ストレージを迅速に構築することができます。仮想リレーショナルレイヤーを通して、よく知られたSQL 構造を使用することで、複数のデータソースを含むあらゆるクエリを実行することができます。CData Virtuality Server はデータソースと分析ストレージの間のレイヤーに過ぎないので、分析ストレージをホストするプロバイダーをさまざまな一般的なプロバイダーから選択することができ、ローカルにホストされたコンテンツではなくライブデータをクエリする際に最高のパフォーマンスを可能にする最先端のインメモリ技術の恩恵を受けることができます。CData Virtuality Server は、JDBC とODBC の両方のインターフェースを提供しているため、Tableau、QlikView などの一般的なビジネスインテリジェンスツールに直接接続することができます。この図は、BIに特化した環境におけるCData Virtuality(Server はその不可欠な一部)の役割を示しています:
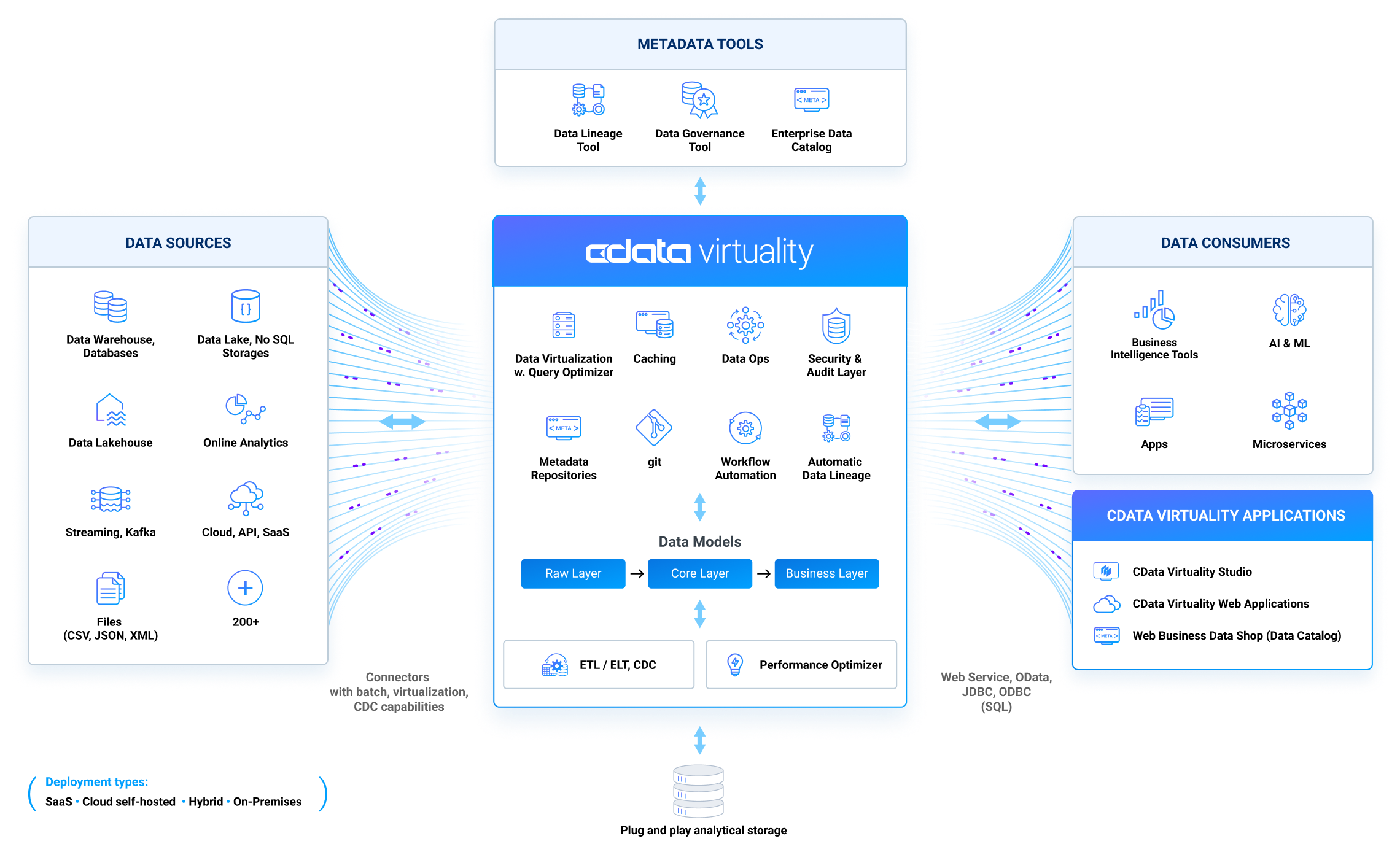
Different Data Sources - No ETL
CData Virtuality Server の強みは、分析ストレージの作成が可能なだけでなく、それ以上に、ETL プロセスからユーザーを解放することにあります。この統合データプラットフォームは、あらゆる種類のデータソースを追加して使用することができます。接続したいすべてのデータソースは、必須情報のみを必要とするシンプルなウィザードで追加できます。その後、Server はデータ ソースの構造を検出し、仮想リレーショナルレイヤとして表示します。これは、特に非リレーショナルな方法でデータをホストしている場合に便利です(最も一般的な例は、MongoDB、Salesforce、Google AdWords、Google Analyticsです)。CData Virtuality Server はデータソースの構造を自動的に検出し、データをリレーショナルモデルで表示するため、すぐに作業を開始できます。ETLを省略することで、ライブデータを分析ストレージに取り込むことなく、即座にクエリを実行できます。最先端のインメモリ技術により、高いパフォーマンスを発揮します。したがって、CData Virtuality Server は、ライブデータを使用してビジネスレポートを簡単かつコスト効率よく実行するための直感的なプラットフォームを提供します。
See the complete list of data sources supported by CData Virtuality here.
Analytical Storage Hosting
Analytical Storage は、CData Virtuality がマテリアライゼーションを配置し、必要に応じてインデックスを作成して自動的に最適化し、基礎となるデータベースのタイプによって許可される特別なデータベースです。分析ストレージを活用することで、クエリのパフォーマンスを劇的に向上させることができます。
CData Virtuality Server のもう一つの大きな特徴は、分析ストレージを動的に構築する手段を提供することです。ETL処理を省いたリレーショナル・レイヤーを使用することで、アプローチをよりダイナミックなレベルに活用することができます。Analytical Storageをホストするプロバイダーは、幅広い選択肢から選ぶことができます。繰り返しクエリの定義を素早く手元に置くためのオプションを提供するパーソナルビューを作成することができます。ビューは、データソースが提供するすべてのデータではなく、重要なデータのみを分析ストレージに格納するための良い代替手段でもあります。もちろん、ソースからのライブデータを使用するか、ローカルに保存されたデータを使用するかは、非常に細かい方法でクエリを実行するときに決めることができます。
See the complete list of analytical storage providers supported by CData Virtuality here.
Optimizations
Data Sourcesから提供されたデータを使用する作業を通じて、情報の最新性に関して柔軟に対応することが望まれます。CData Virtuality Server を支えるテクノロジーにより、ローカル分析ストレージに保存するデータと、クエリの実行時にソースからライブで取得するデータを自由に決定することができます。必要なデータのローカルコピーを取得する処理である Materialization は、テーブル全体や特定の作成された View に対して使用できます。さらに、CData Virtuality Server は、テーブル、ビュー、頻繁に使用されるJOIN や集約の使用頻度を追跡します。CData Virtuality Server は、これらの統計情報を使用して、これらの頻度をグラフィカルに可視化し、クエリのパフォーマンスを最適化するために分析ストレージに格納すべき頻度をアドバイスします。また、クエリにおけるカラムの出現状況に応じて、インデックスを作成すべきカラムを提案します。特定のテーブルからの特定のクエリにライブデータを使用したい場合、最新のインメモリ技術がCData Virtuality Server がこれらの処理を実行する際の最小実行時間を保証します。ライブデータ、Analytical Storageホストされたデータ、またはその両方の組み合わせが可能です。
Replications
Analytical Storageテクノロジーを使用する場合、ローカルコンテンツを定期的に更新する必要があります。スケジュールベースのレプリケーションは、Analytical Storage データの更新に役立ちます。レプリケーションにはさまざまなタイプがあります。ローカルの1対1のコピーを取得する完全なレプリケーションから、すべての外部データとその変更を時系列で追跡できる履歴更新まで。後者の概念は、ゆっくりと変化するディメンションとしても知られており、変更されたデータ、または現在では削除されている可能性のあるデータに依存する一部のビジネスレポートで重要な役割を果たすことがあります。さまざまなタイプのスケジュールが必要な粒度を提供します。スケジュールは1回限りのシンプルなものから定期的なものまで、また非常に正確なcron ジョブや先行するスケジュールに依存するものまであります。
SQL and Business Intelligence
CData Virtuality Server は、仮想リレーショナルスキーマを介してさまざまなタイプのデータソースにアクセスできるようにする中間レイヤとして理解されるため、これらの異なるソースから簡単に情報を収集することが非常に重要です。そのため、CData Virtuality Server はこのタスクのために一般的なSQL コンストラクトを提供します。このソフトウェアでは、単純なSELECTステートメントから、動的SQL を使用した独自のプロシージャまで、あらゆることが可能です。このため、余分な言語を学ぶ必要がなく、一般的なビジネスインテリジェンスツールやフロントエンドはすべて、CData Virtuality Server に基づいてレポートを作成することができます。また、定義済みのストアドプロシージャを使用してCData Virtuality Server 全体を管理することも可能です。提供されるJDBCとODBCのサポートは、レポートタスクとビジネス洞察の収集のための大規模なツールセットを提供します。