
増分レプリケーションは、ソース・テーブルから分析ストレージに新しく追加されたデータのみをコピーするため、場合によってはより効率的です。どのような場合に役立つかをいくつかご紹介します:
ソース・テーブルは新規エントリと更新のみを取得し、削除は行いません(例えば、顧客の購入データを含むテーブル);
ソース テーブルは非常に大きいですが、変更された行の量は比較的少ないです;
ソースから削除されても、すべての記録を保持する必要があります。
インクリメンタルレプリケーションの厄介な点は、どの行が新規または更新され、どの行が更新されていないかを簡単に判断するために使用できる、信頼できるタイムスタンプ値を持つカラムが必要なことです。例えば、Modified、行が変更(新規挿入または更新)されたことを正確に表示する列や、自動インクリメントされたIDを提供する列(更新ではなく、挿入の場合のみ)などがあります。
理論的には、どの列でも行チェックフィールドとして使用することができますが、その内容が変更または新規エントリを反映できることを確認することをお勧めします。そうでない場合、ソースから取得したばかりの行が偽である可能性があります(行の欠落、更新の欠落、重複行など)。
この例では、TIMESTAMPとused-defined式を使用します。
How It Works
Web UI で Replication ジョブを追加するには、次の手順を実行します:
Web UI でReplication Job ダイアログを開き、Optimization メニューに進みます。
Create New Jobをクリックし、Create Replication Jobをクリックします:
ダイアログで、Incrementalタブを選択します:
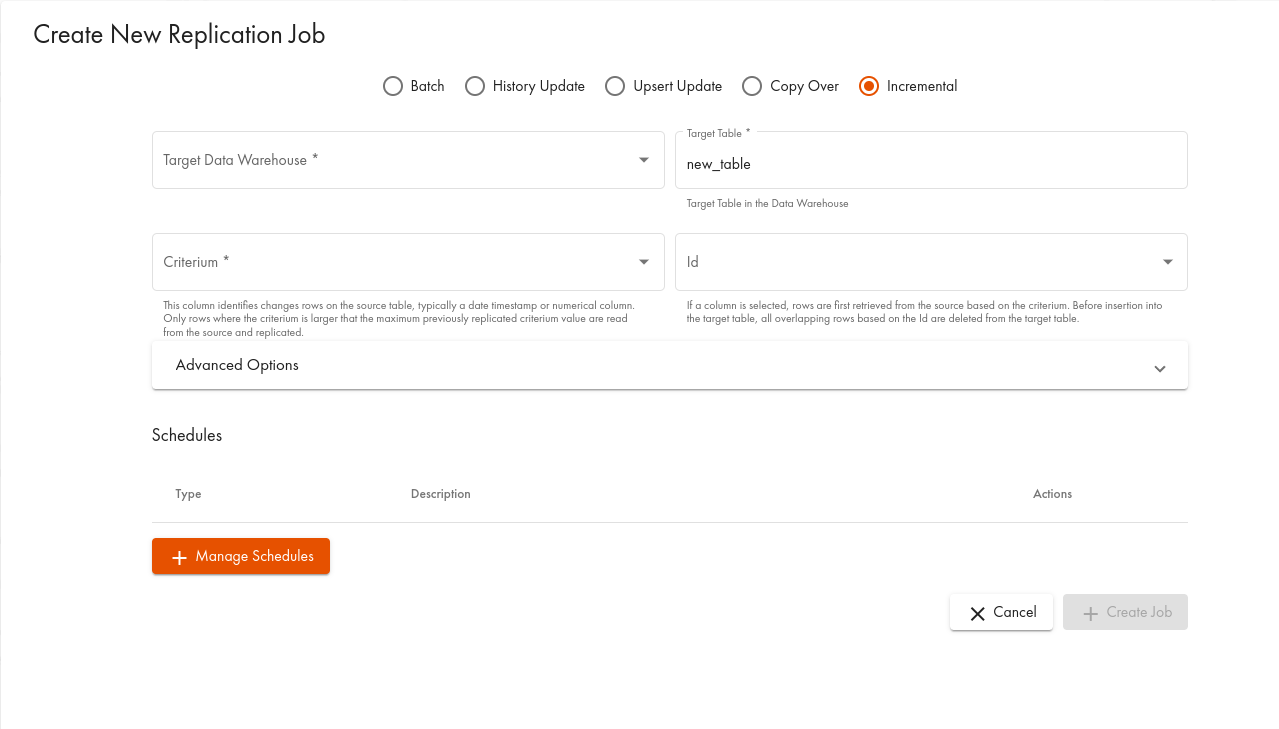
以下はフィールドの説明です:
Parameter | Description |
|---|---|
Target data source | Fully-qualified name of the source. Must be an existing table; mandatory |
Target table | Fully-qualified name of the target; mandatory |
Criterium | Criterium column name. This is the column name of the incremental field. Usually, this will be an integer/long or timestamp column. The procedure calculates the maximum value of this field and inserts/updates the records from the source table with a value larger than already existing in the target table; mandatory |
Id | ID column name to handle updated rows. If this parameter is specified, existing rows with a criterium larger than the maximum will be deleted and re-inserted to handle modified rows. If this parameter is omitted, all rows with a larger criterium will be inserted into the target table. If the key column exists in the source table, but was not specified, the result table will contain multiple entries for each key |
See Also
incrementalReplication - id およびcriterium カラムによって定義されるターゲットへのソースのインクリメンタルレプリケーションを実行するための専用のユーティリティプロシージャについては、こちらをご覧ください。
A short guide on data replication types and use cases. Incremental and Upsert Replication - Incremental Replication とその使用例については、CData Virtuality ブログの投稿をご覧ください。