
Incremental Materializationは、新しく追加されたデータのみをソース・テーブルから分析ストレージにコピーするため、Complete Materializationよりも効率的です。どのような場合に役立つかをいくつかご紹介します:
ソース・テーブルは新しいエントリのみを取得し、更新/削除は行いません(顧客の購入データを含むテーブル);
ソース テーブルは非常に大きいですが、変更された行の量は比較的少ないです;
ソースから削除されても、すべての記録を保持する必要があります。
インクリメンタルMaterializationの厄介な点は、どの行が新しく、どの行がそうでないかを簡単に判断するために使用できる、信頼できるタイムスタンプ値を持つカラムを必要とすることです。例えば、Modified、行が変更(新規挿入または更新)されたことを正確に表示するカラムや、自動インクリメントされたIDを提供するカラムなどです。
理論的には、どの列でも行チェックフィールドとして使用することができますが、その内容が変更または新規エントリを反映できることを確認することをお勧めします。そうでない場合、ソースから取得したばかりの行が偽である可能性があります(行の欠落、更新の欠落、重複行など)。
この材料化の主な側面は、ソースの行に関連する時間の知識であることに注意してください。インクリメンタル・マテリアライゼーション自体は、マテリアライズド・テーブルにステージを使用しません。しかし、さらに Complete Materialization を実行することで、ステージを利用することができます。Materialization が完了するたびに、使用されているマテリアライズドテーブルの新しいステージが提供されます。次の Complete Materialization まで、各 Incremental ジョブは最新のステージを使用し、それ以上ステージを追加しません。その結果、Incremental Materialization(インクリメンタル・マテリアライゼーション)だけを使用した場合、フォールバックするステージがなくなります。
材料化ジョブが実行されると、材料化テーブルの現在のデータがスキャンされ、特定の列の最大値が生成されるか、ユーザー定義の式が計算されます。
この例では、TIMESTAMPとused-defined式を使用します。
How It Works
Web UI で Optimizations を追加するには、次のようにします:
- Web UIでブラウザを開き、メニューに進みます。
- Create New Jobをクリックし、Create Materialization Jobをクリックします:
- ダイアログで、Incrementalタブを選択します:
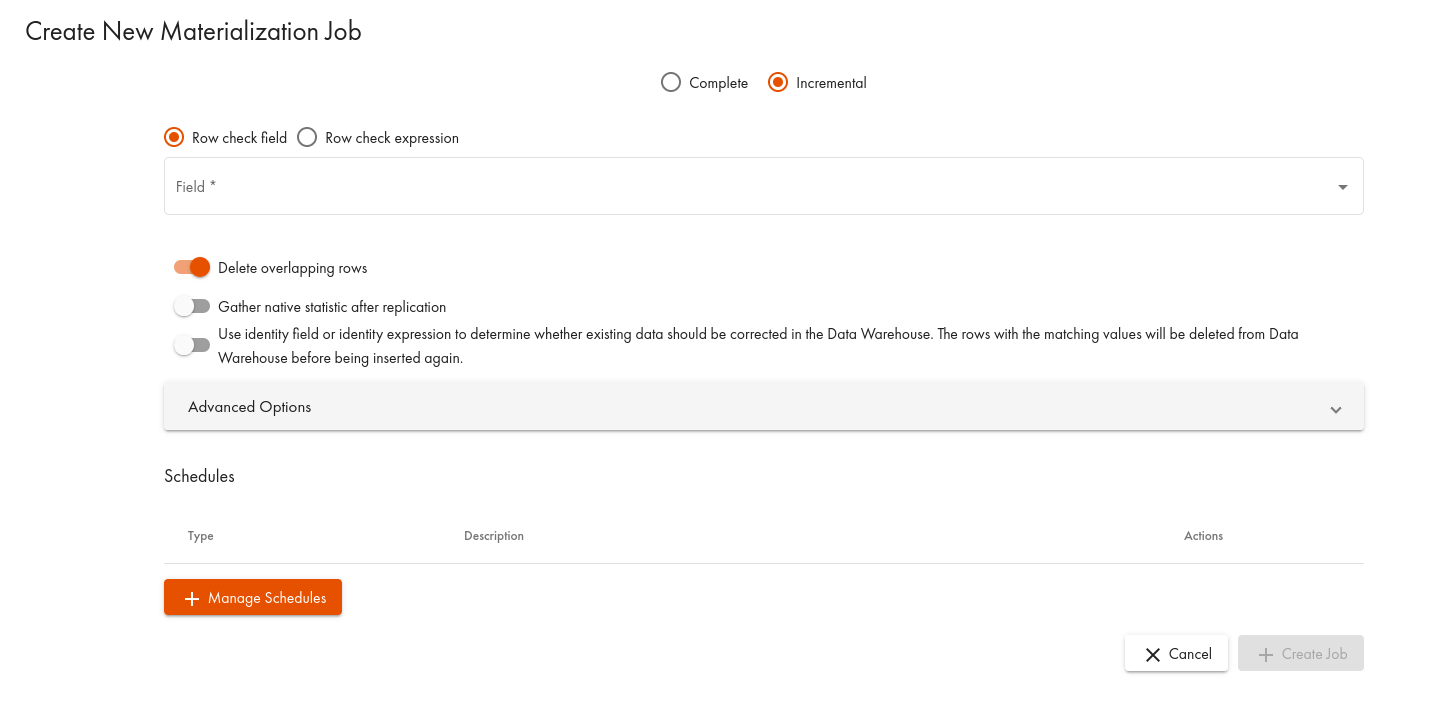
上図のように、ROW チェックフィールド 'modified' が選択されています。レプリケーションが初めて実行される場合、現在のソース・データは分析ストレージ・テーブルに保存されます。この結果はどの設定にも依存しませんが、重要なのはレプリケーション・ジョブの2回目の実行です。この例では、ソース・データは2行のみで構成されています:

Delete Old Data
Row チェックフィールド以外に何も指定されていない場合、次の実行では、modified > 2014-09-08を持つすべての行をソースにクエリします。この値は、マテリアライズド・テーブルの最近のデータから動的に計算されます。 ここで、ソーステーブルが同じ日付に更新や挿入を受けると考えた場合、これらの行は更新の対象にはなりません。Delete old dataのチェックを外すと、更新値が「2014-09-09」以上のレコードのみがマテリアライズド・テーブルにロードされます。その結果、分析ストレージデータとSourcesの実際のデータとの間にギャップが生じる可能性があります。ソースにさらに3つのエントリが作成されたと仮定すると、次のジョブの実行により、Delete old dataに応じて、以下のテーブルが得られます:

古いデータの削除設定の有無で、レプリケーション・ジョブに大きな違いが生じることがあります。これは、ROWチェック・フィールドのデータ型とジョブが実行される時間に大きく依存します。ベストプラクティスは、TIMESTAMPデータ型(日付と時刻)を提供するカラムを使用し、設定を有効にすることです。また、同じ日付(またはタイムスタンプ)の行を更新することもできます。
以下は、そのコンセプトを示す基礎となるステートメントです:
古いデータを削除せず、Row チェックフィールドとして変更します。
SELECT ... INTO ... FROM ... WHERE source.modified > (SELECT MAX(modified) FROM <materializedTable>)古いデータを削除し、Row チェックフィールドとして変更した場合
SELECT ... INTO ... FROM ... WHERE source.modified >= (SELECT MAX(modified) FROM <materializedTable>)新しい行が適切な後の日付で表示された場合、エントリは常にローカルテーブルにロードされます。記録が本当に新しいものであり、既存のものの更新版でない限り、これは問題ではありません:

Identity Columns
IDカラムの概念は非常にシンプルです。ソース・テーブルが新しいレコードのみを取得し、既存のレコードを更新しない場合、マテリアライズド・テーブルに重複したエントリが存在することはありません。しかし、既存の行に更新があり、日付(またはTIMESTAMP)の値も増加する場合はどうでしょうか?その後、更新された行がソースから取得され、CData Virtuality Server はどのように処理を進めるかを知る必要があります。
IDフィールドが使用されていない場合、更新された行は既存の行の追加行としてローカルテーブルに挿入され、重複してしまう可能性があります。

Wayland Smithersは2日で10歳年を取り、Tablesは古い行と更新された行を表示しています。ID フィールドを選択する (または ID 式を指定する) ことで、これらの重複を回避できます。このオプションでは、CData Virtuality Server は新しい行をスキャンし、ソースから受信した行が既存のローカル行の単なる更新であるかどうかをチェックし、更新を実行します。この例では、ID フィールドとしてカラム 'ID' を使用しています。
上に示したように、レコードは一度だけ存在しますが、最新の値であり、重複はありません。
Delete old data および IDITY 設定を使用するかどうかを判断するには、ソース・オブジェクトの構造を注意深く精査する必要があります。
インクリメンタル更新はソースからの特定の新しい行のみをチェックできるため、ソースで削除されたレコードはマテリアライズドテーブルに残ります。この方法では、どのレコードが削除されたかを判断することはできません。
Overview of Incremental Materialization Settings
To view the full table, click the expand button in its top right corner
Setting | Purpose | Unused Setting | Used Setting |
|---|---|---|---|
Row check field (Row check expression) | Determine which rows to retrieve from the source | Mandatory setting | All records in the source with a value below the maximum of this column in the local table will be ignored |
Delete old data | Specifies whether new rows will be retrieved with | Can lead to missing rows from the source | Will never miss new rows and might even update ones with the same value in the Row check field |
Identity field (Identity expression) | Specifies how to detect duplicates | No detection for duplicates. A record can occur several times (one additional row per update at worst) | Duplicates are detected by column value (or expression), and the old rows will be updated with the new values |