
このガイドでは、CData Virtuality で利用可能なレプリケーションの種類を説明し、設定方法をステップバイステップで説明します。
The guide uses sample data from the MySQL and PostgreSQL sample databases. See this guide for instructions on connecting to the sample databases to use the provided sample data. Additionally, since this procedure involves adding records to the data source, an external Microsoft SQL Server (Northwind database) is added to the data sources.
The replication process in this guide will use Snowflake as the data warehouse.
About Replication
データ仮想化機能によるリアルタイムのデータアクセスに加え、CData Virtuality はバイモーダルデータレプリケーションによるデータコラボレーションをサポートし、ETL / ELT を提供します。
レプリケーションとマテリアライゼーションには共通点がありますが、それぞれ目的は異なります:
マテリアライゼーション:パフォーマンスを最適化するために設計されたキャッシュと一時保存のメカニズム。パフォーマンス(レスポンスタイム)やデータソース側(高負荷)に影響を与えることなくデータアクセスが可能になります。
レプリケーション:データをソースからデータウェアハウスなどのデータストアにコピーして蓄積するプロセス。
これがCData Virtuality のレプリケーションプロセスの仕組みです:
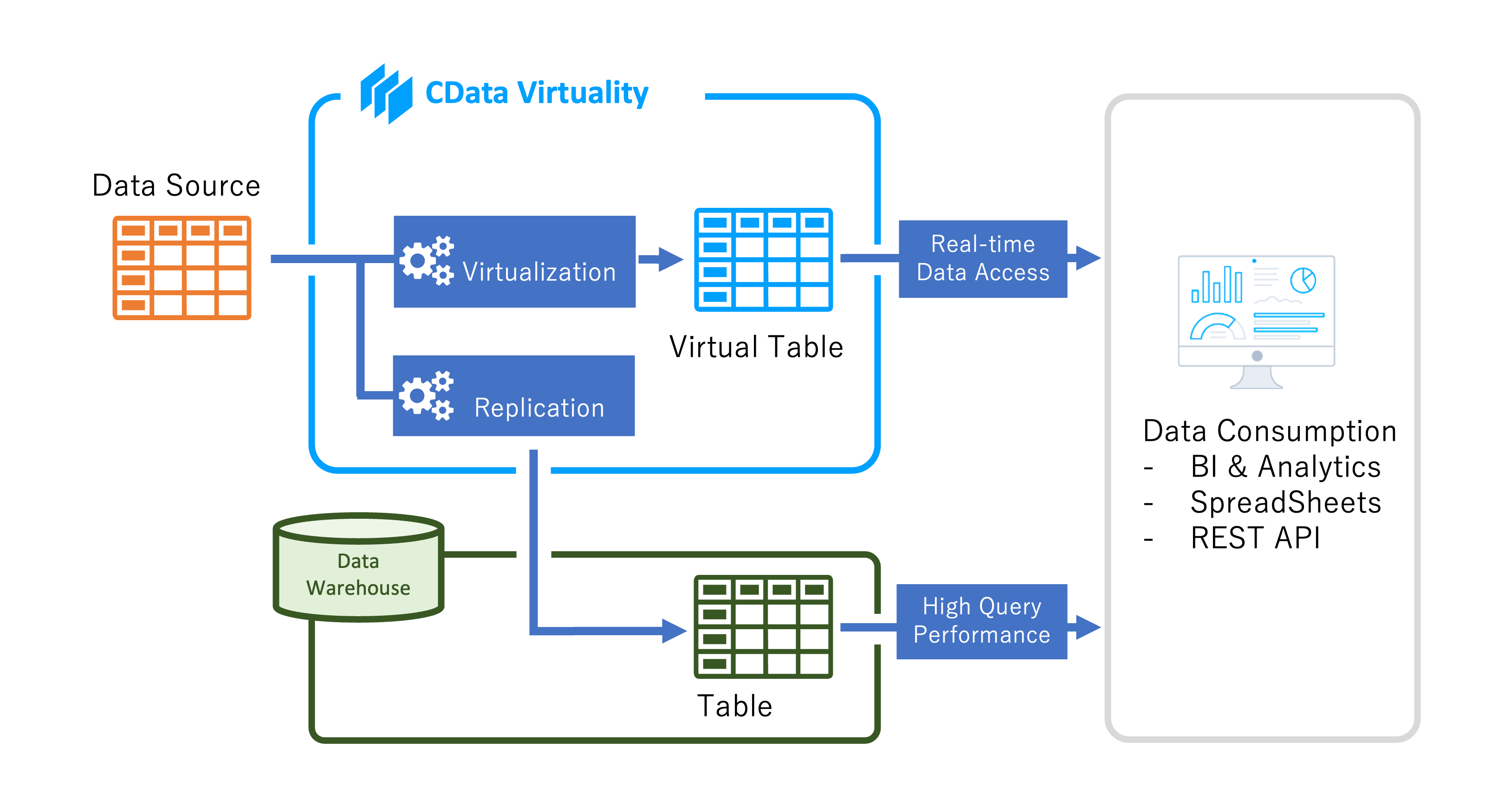
Replication Types
CData Virtuality は5種類のレプリケーションを提供します。このガイドでは、CData Virtuality Web UI を使用した各パターンのセットアップについて説明します:
Copy Over/Full(全件更新/完全):全件を再取り込みします。データウェアハウス側で同じ名称のテーブルがすでに存在する場合は、選択された方法(Drop / Delete)によって処理されます。
Incremental(増分更新):新しく追加されたレコードのみをコピー先のデータウェアハウスにコピーします。
Batch(バッチ更新):レプリケーションジョブが実行されるたびに、データウェアハウス内の既存のテーブルを更新します。
History update(履歴更新):データに加えられた変更を履歴として保管します。
Upsert update(アップサート更新):既存の行を更新し、新しい行を挿入します。
Copy Over/Full (Update All)
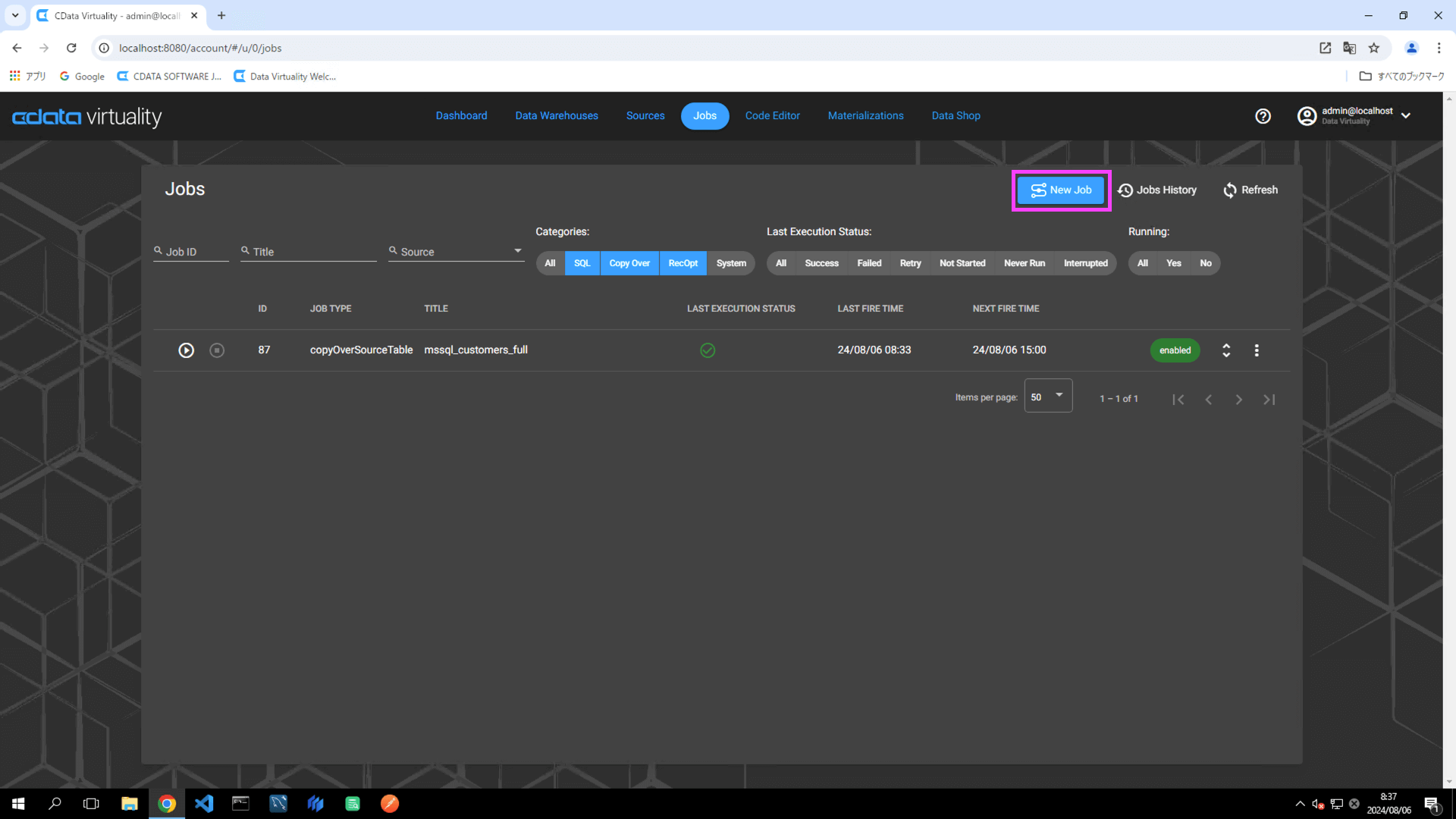
Jobs を開き、New Job ボタンをクリックします:
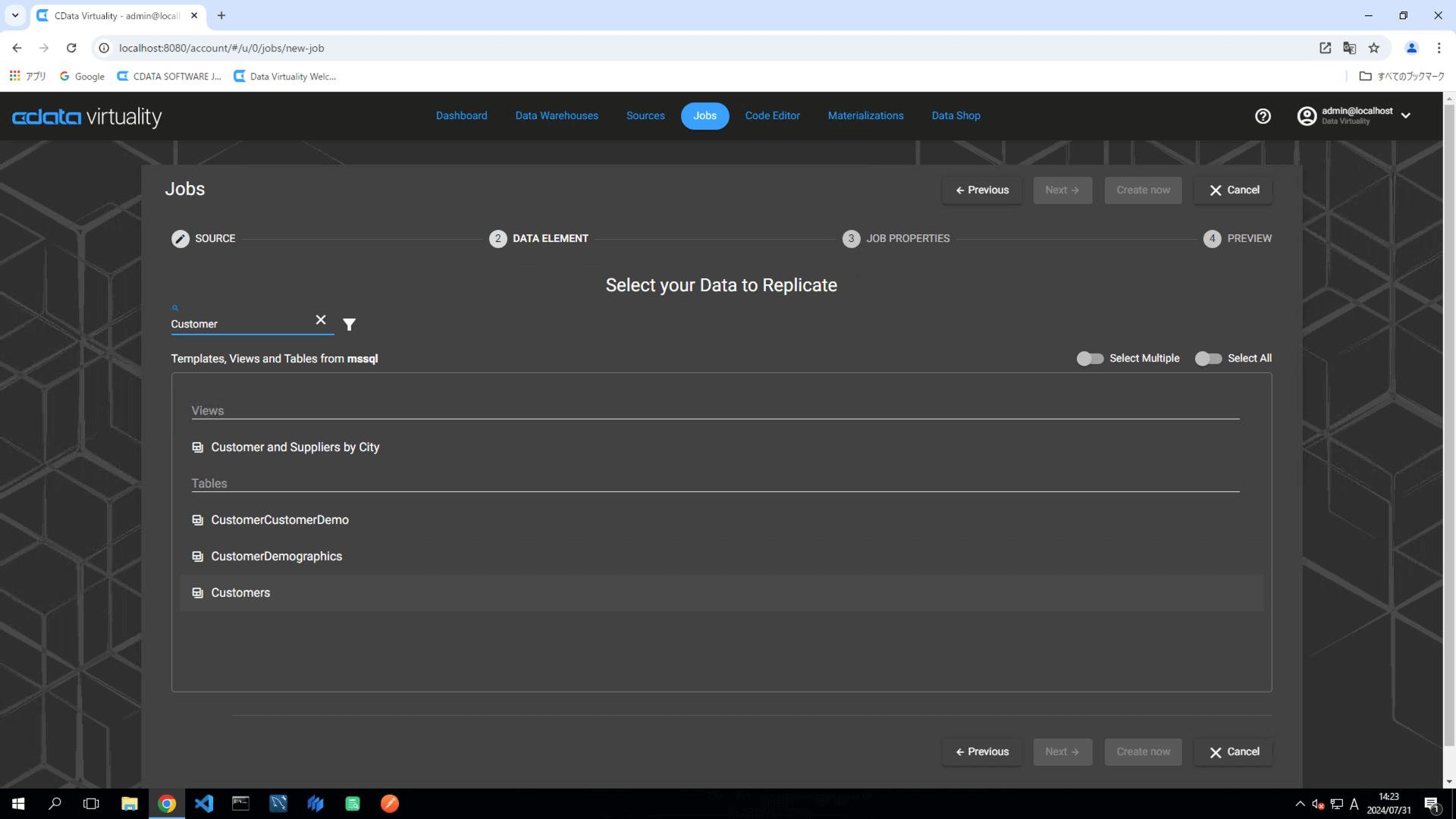
Select your Data to Replicate 画面で、レプリケートするテーブルを選択し、Next ボタンをクリックします:
For this example, the Customers table in Microsoft SQL Server is selected.
レプリケーションのタイプとしてFull を選択し、次に進みます:
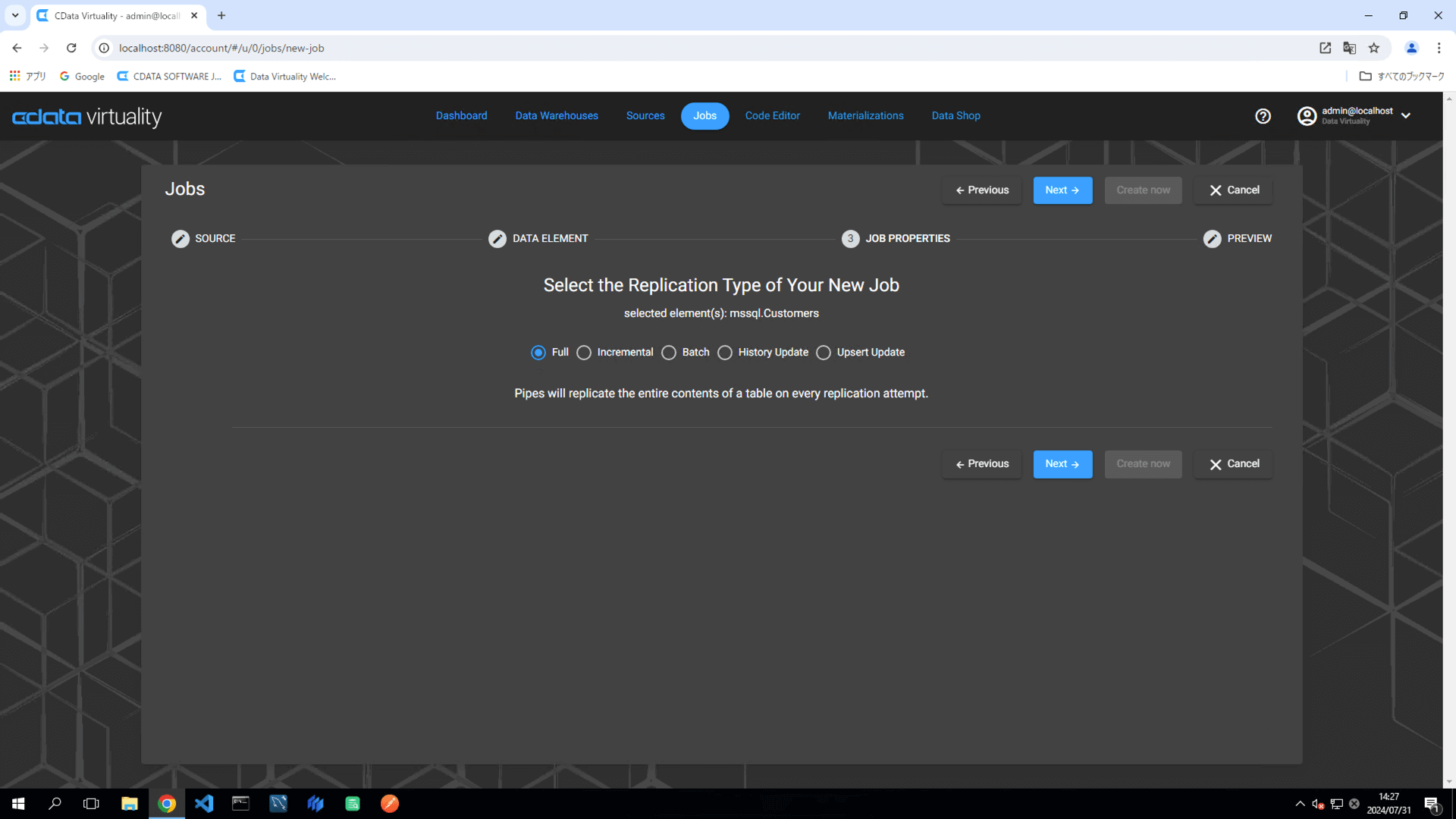
パイプライン構成に以下の要素を設定します:
Data Warehouse:対象のデータウェアハウスを選択します。
Target Schema:対象スキーマを指定します。
Title:パイプラインの名前を
mssql_customers_fullに変更します。Schedule:希望の実行スケジュールを設定します。
Start Immediately:すぐに実行する場合はトグルをON にします。
より柔軟なスケジュール設定を行うには、Advanced Scheduling ボタンをクリックします。
Create now ボタンをクリックしてレプリケーションジョブを実行します。
Dashboard 画面が開きます。緑色のバーが、ジョブが正常に作成されたことを示します:
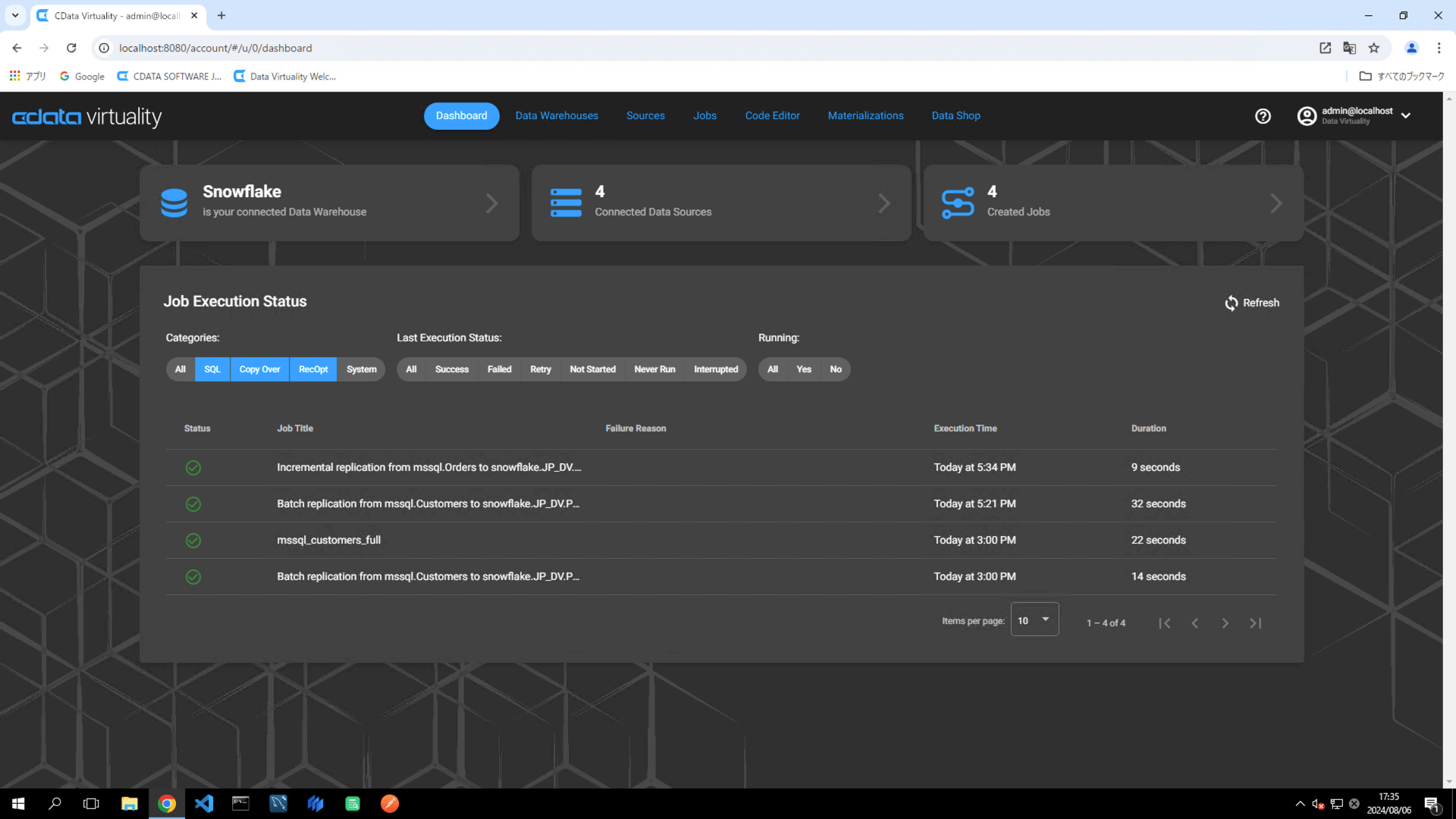
ジョブが実行されたら、Dashboard画面のStatus がSuccessful になっていることを確認します。ステータスが自動的に更新されない場合は、Refresh ボタンをクリックして画面を更新してください:
Snowflake にアクセスし、該当テーブルにデータが格納されていることを確認します:
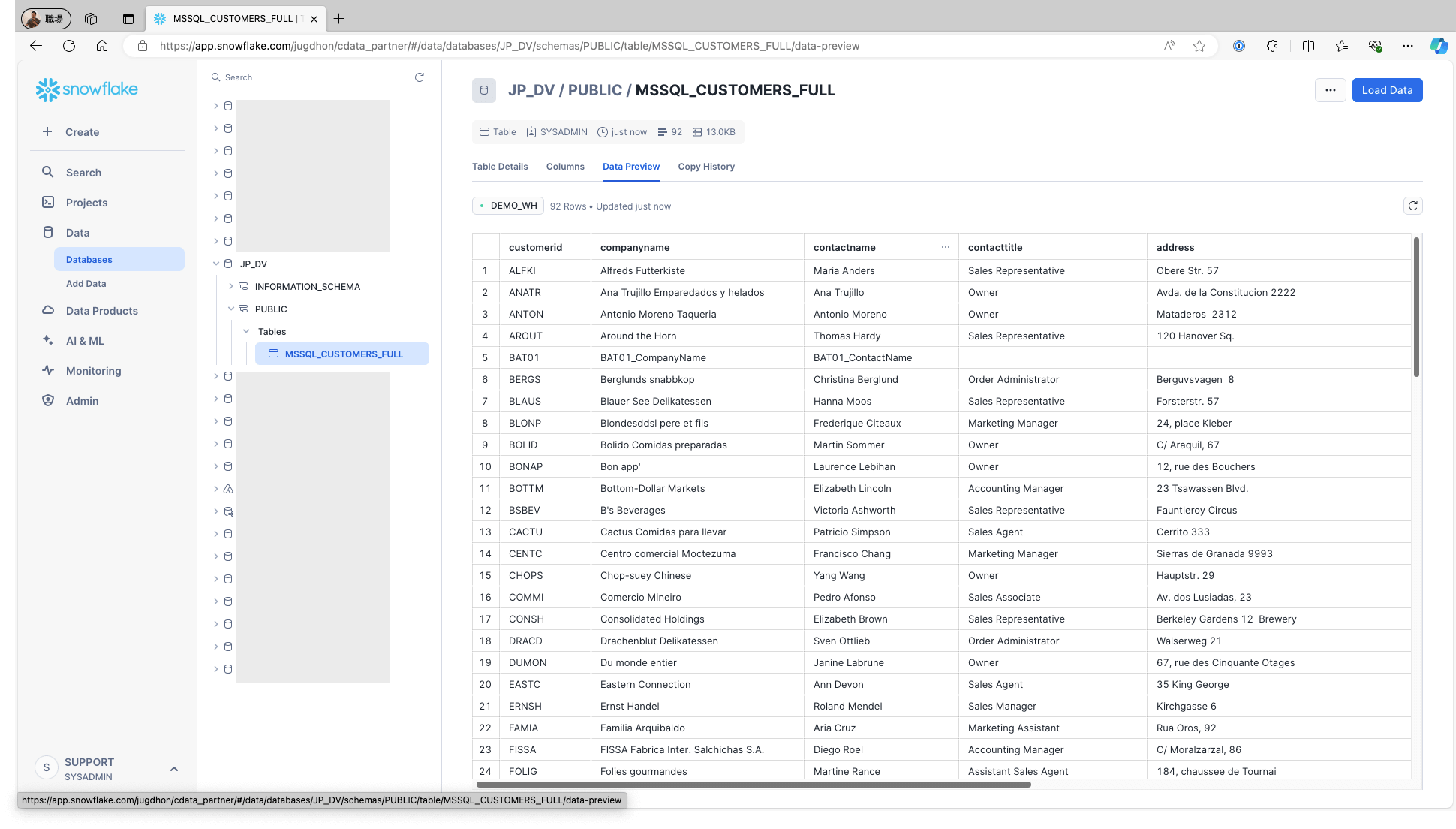
Jobs 画面では、JOB TYPE がcopyOverSourceTable と表示されますが、これはCopy Over またはFull レプリケーションと同義です:
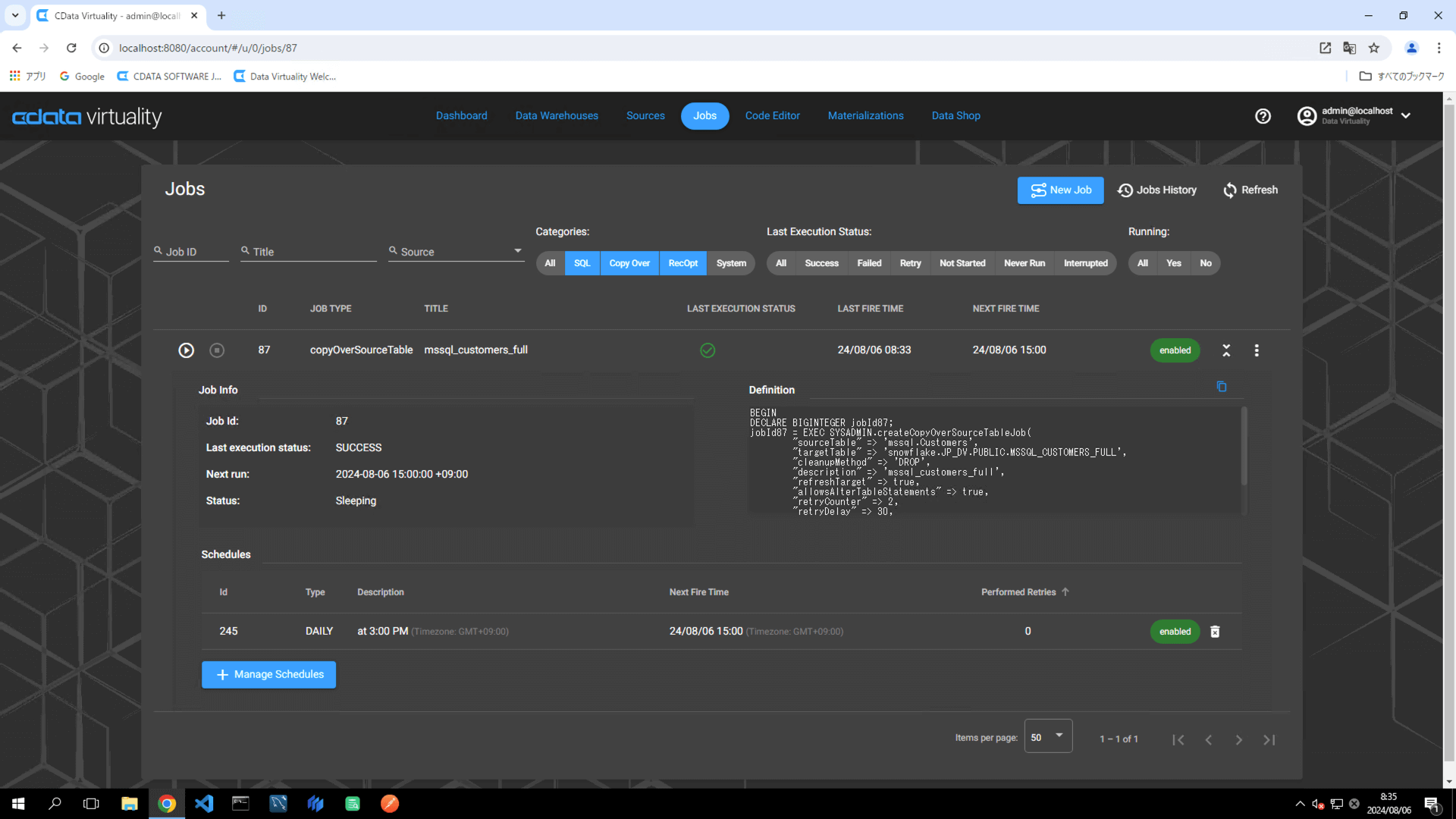
ジョブ設定を編集するには、目的のジョブを見つけ、ジョブの横にある縦三点リーダーをクリックします。コンテキストメニューからEdit Job を選択します:
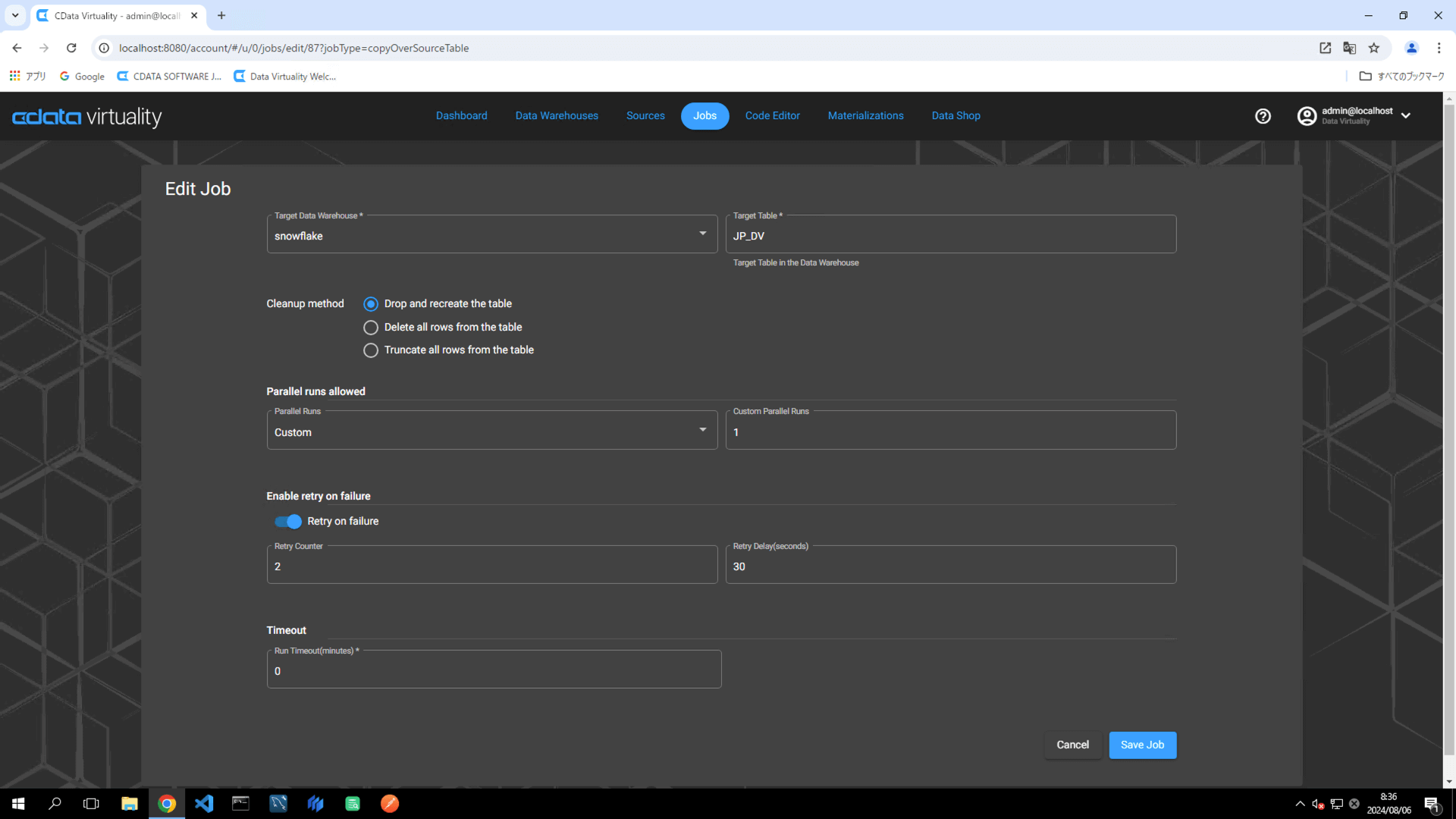
レプリケーションジョブのクリーンアップ方法は、以下の3つのオプションから選択できます:
Drop and recreate the table
Delete all rows from the table
Truncate all rows from the table
デフォルト設定はDrop and recreate the table で、ジョブの実行時に一度データウェアハウス側のテーブルを削除してから、新しいテーブルを作成します。
Incremental
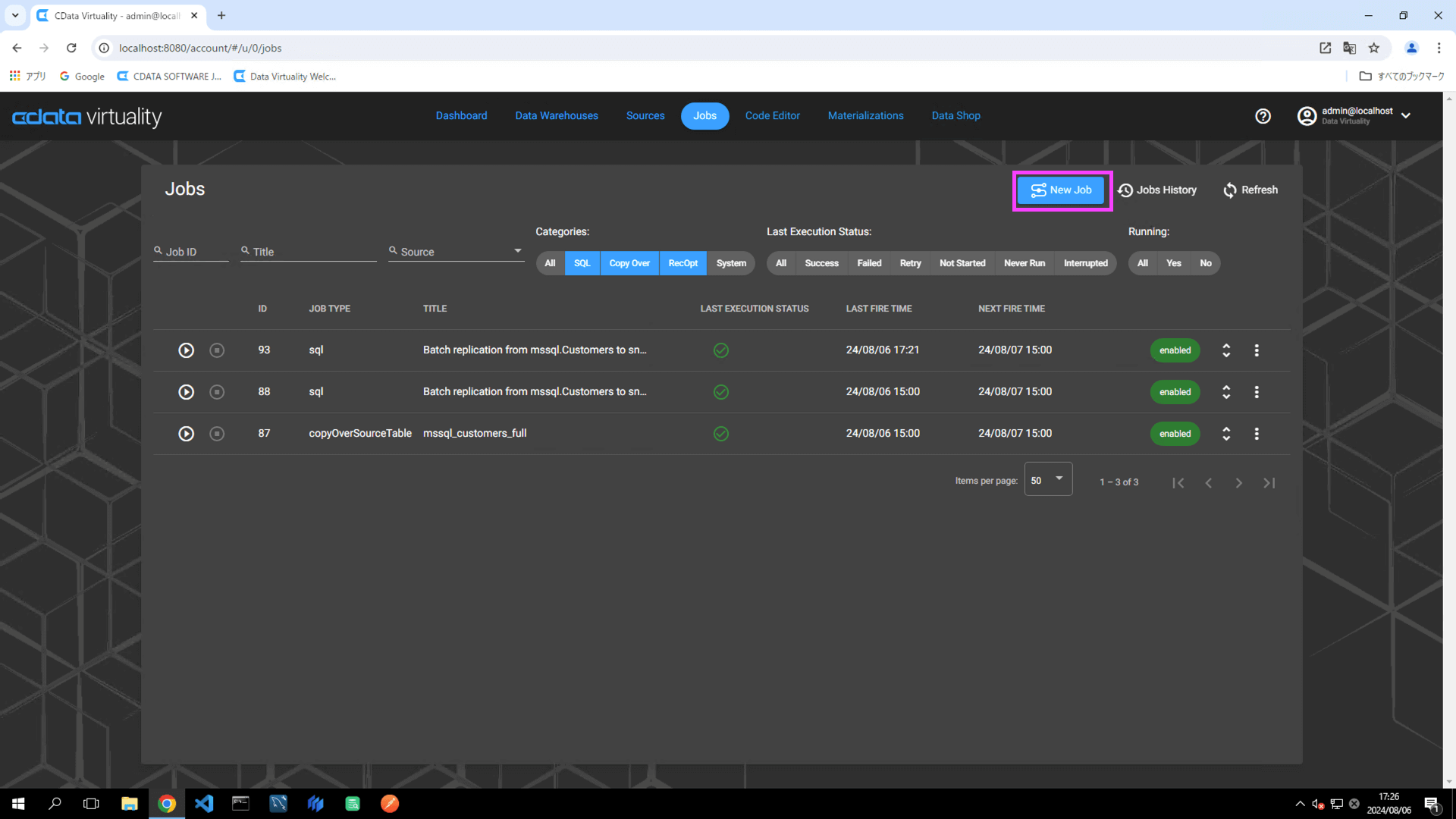
Jobs を開き、New Job ボタンをクリックします:
Select your Data to Replicate 画面で、レプリケートするテーブルを選択し、Next ボタンをクリックします:
For this example, the Orders table in Microsoft SQL Server is selected.
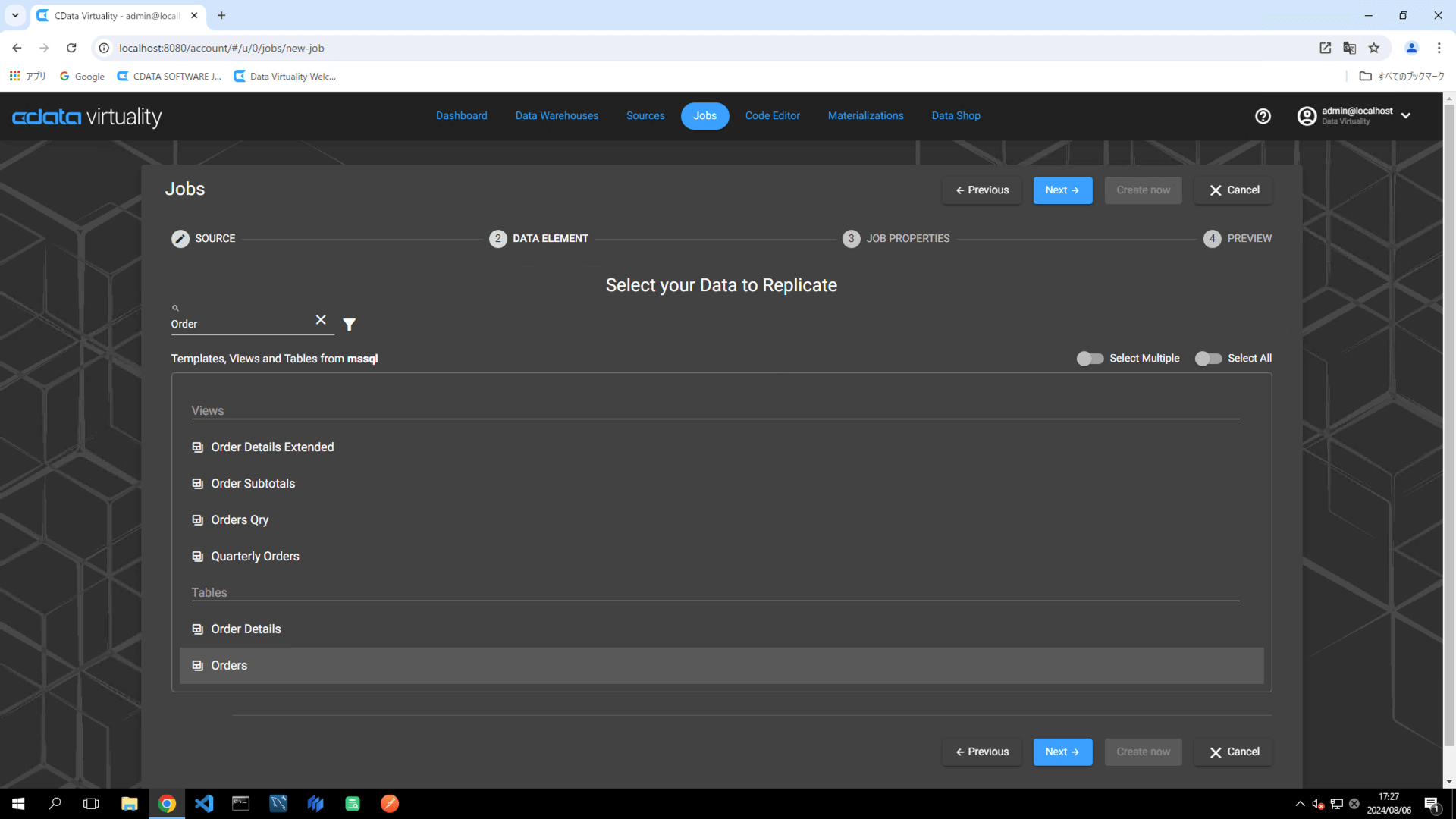
増分更新では、2つのフィールドが必要です:
変更された行を識別するためのフィールド。通常は、日付のタイムスタンプまたは数値カラム(例:OrderDate)。
各レコードを一意に識別するためのID フィールド(例:OrderID):
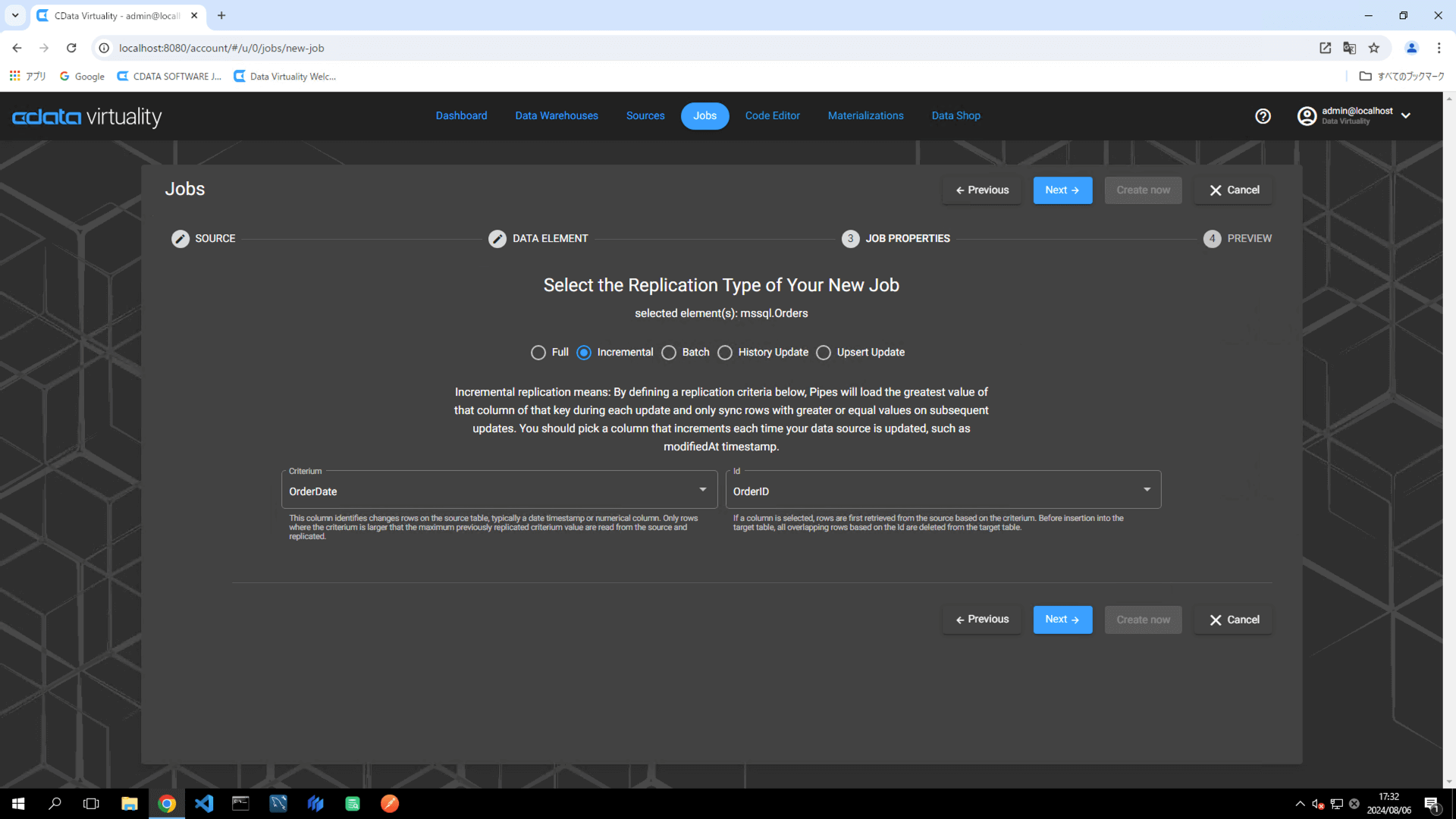
パイプライン構成に以下の要素を設定します:
Data Warehouse:対象のデータウェアハウスを選択します。
Target Schema:対象スキーマを指定します。
Title:パイプラインの名前を
mssql_orders_incrementalに変更します。Schedule:希望の実行スケジュールを設定します。
Start Immediately:すぐに実行する場合はトグルをON にします。
より柔軟なスケジュール設定を行うには、Advanced Scheduling ボタンをクリックします。
Create now ボタンをクリックしてレプリケーションジョブを実行します:
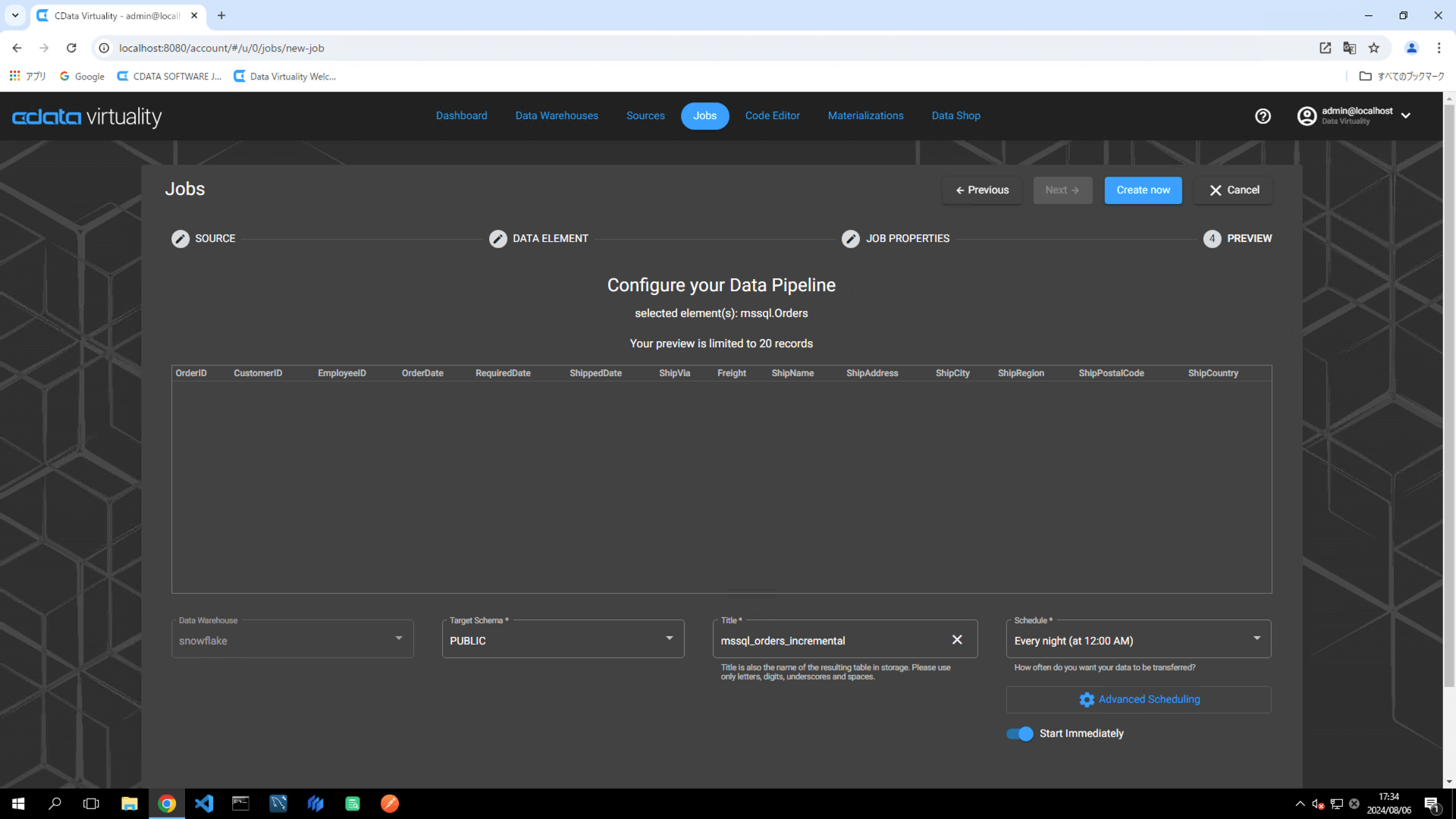
Dashboard 画面が開きます。緑色のバーが、ジョブが正常に作成されたことを示します:
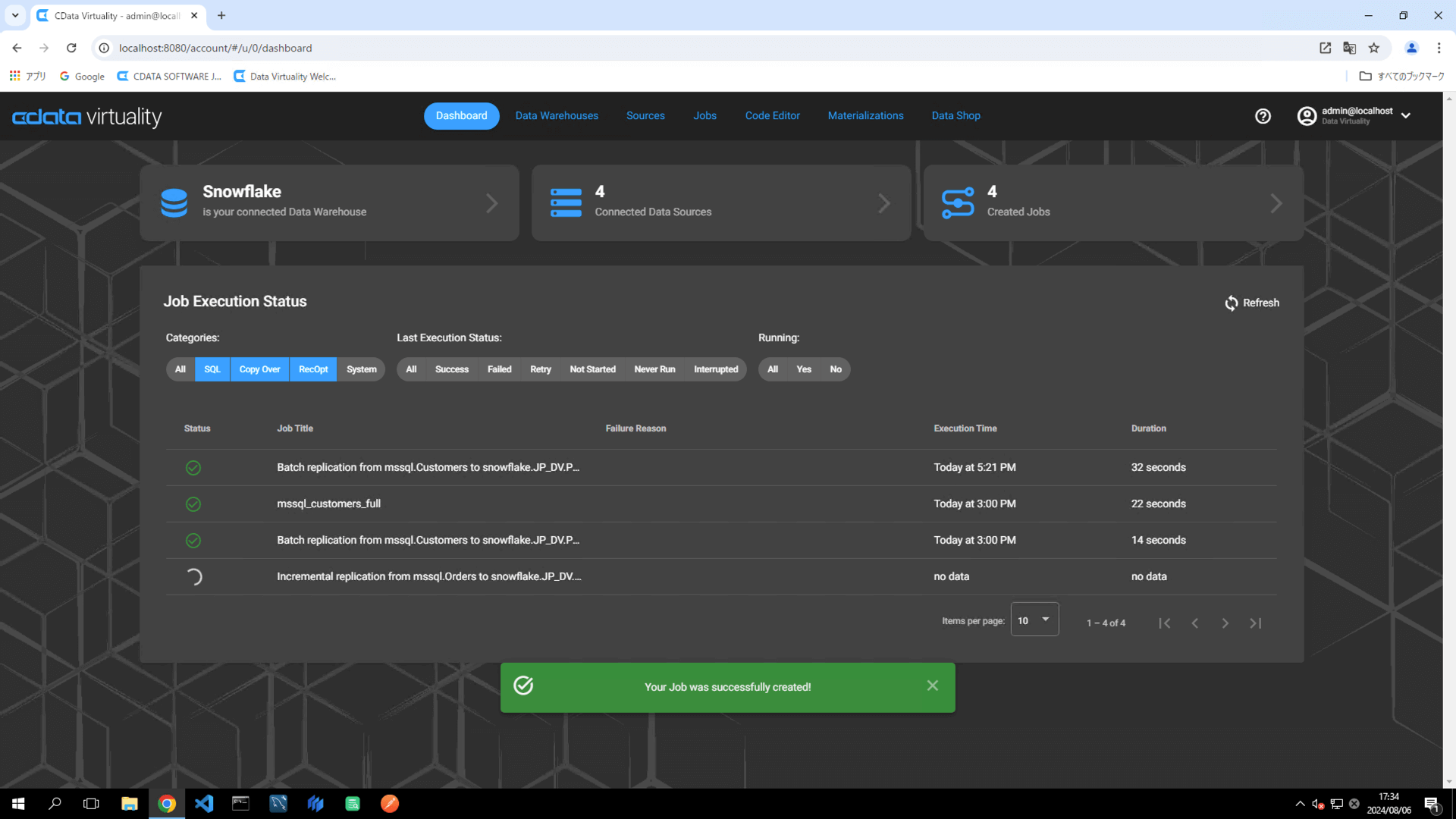
ジョブが実行されたら、Dashboard画面のStatus がSuccessful になっていることを確認します。ステータスが自動的に更新されない場合は、Refresh ボタンをクリックして画面を更新してください:
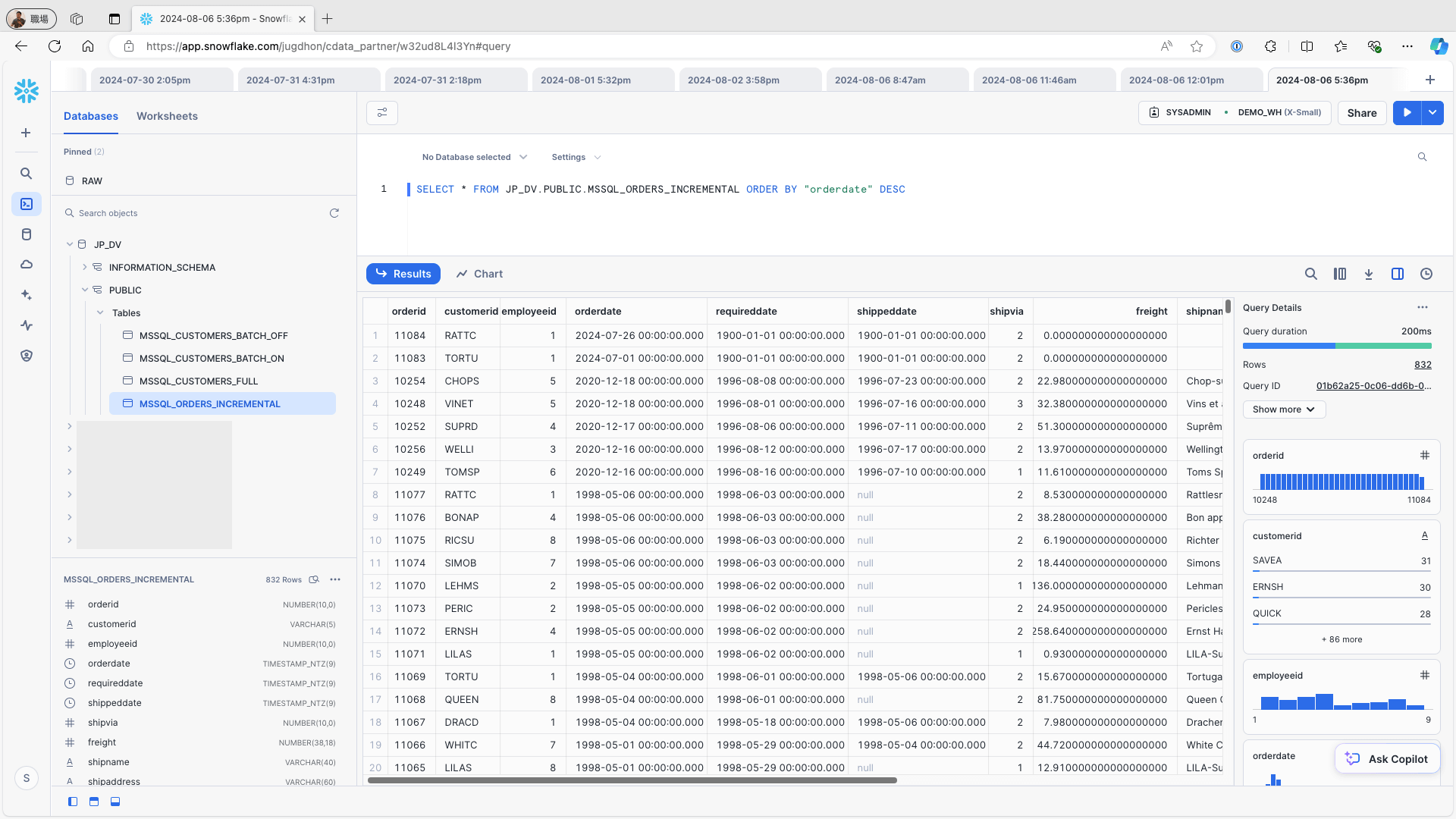
Snowflake にアクセスし、該当テーブルにデータが格納されていることを確認します:
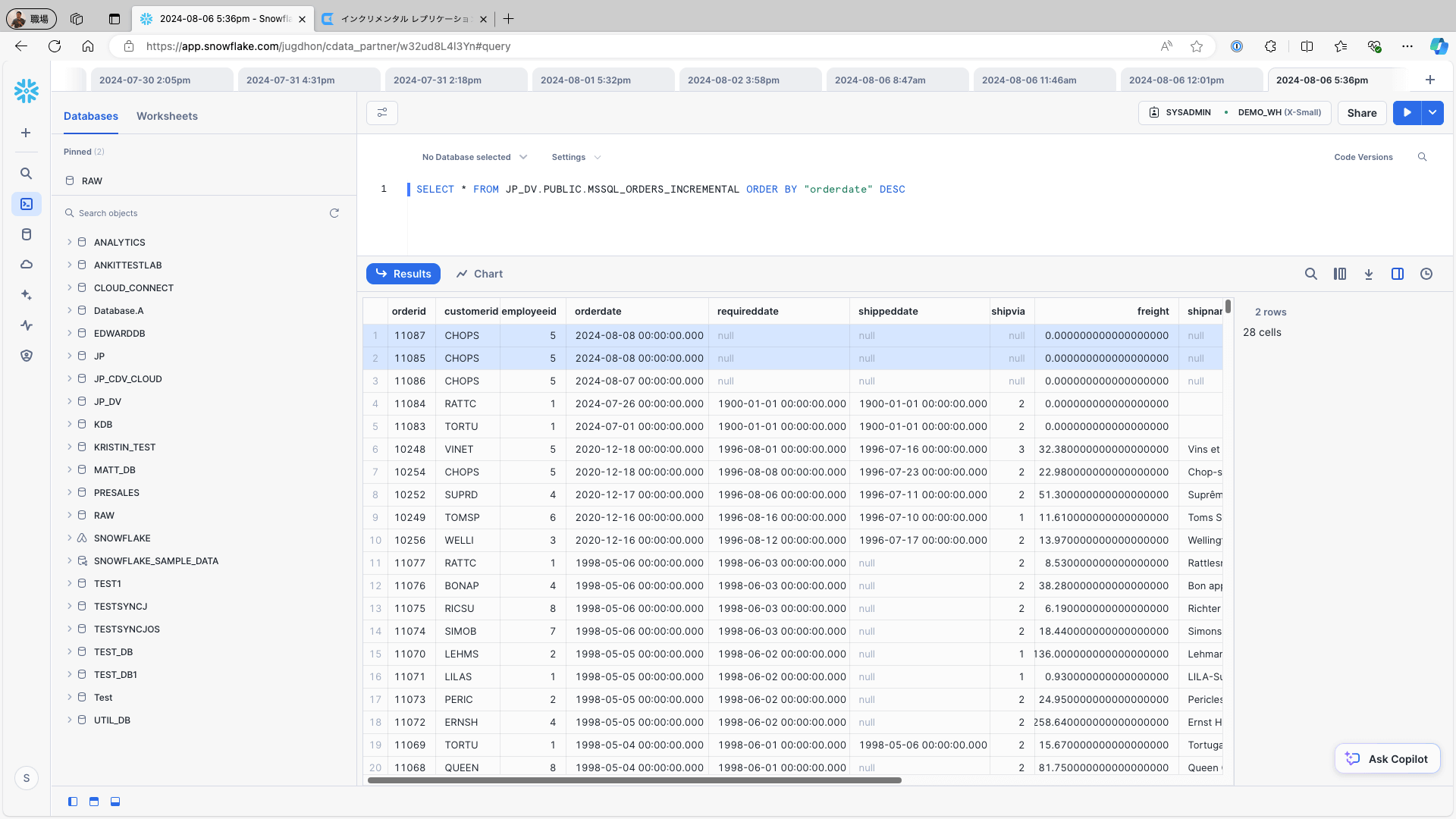
データソース(例えば、Microsoft SQL Server のOrders テーブル)に新しいレコードを追加するには、次のクエリを使用して1レコードを変更し、レプリケーションジョブを再実行します:
INSERT INTO Orders (CustomerID, EmployeeID, OrderDate,ShipCountry) VALUES ('CHOPS', 5, '2024/08/08', 'USA');UPDATE Orders SET OrderDate = '2024/08/08' WHERE OrderID = 11085;Snowflake にアクセスし、レプリケーション先のテーブルを確認します。データソースから新たに追加・更新されたレコードがレプリケーション先のテーブルに正確に反映されていることを確認し、レコードがレプリケーション先に正しくリンクされていることを確認します:
Batch Update
Jobs に移動し、New Job ボタンをクリックします:
Select your Data to Replicate 画面で、レプリケートするテーブルを選択し、Next ボタンをクリックします:
For this example, the Customers table in Microsoft SQL Server is selected.
レプリケーションのタイプとしてBatch を選択し、Use identity field... トグルがOFF になっていることを確認します。
パイプライン構成に以下の要素を設定します:
Data Warehouse:対象のデータウェアハウスを選択します。
Target Schema:対象スキーマを指定します。
Title:パイプラインの名前を
mssql_customers_batch_offに変更します。Schedule:希望の実行スケジュールを設定します。
Start Immediately:すぐに実行する場合はトグルをON にします。
より柔軟なスケジュール設定を行うには、Advanced Scheduling ボタンをクリックします。
Create now ボタンをクリックしてレプリケーションジョブを実行します。
Dashboard 画面が開きます。緑色のバーが、ジョブが正常に作成されたことを示します:
ジョブが実行されたら、Dashboard画面のStatus がSuccessful になっていることを確認します。ステータスが自動的に更新されない場合は、Refresh ボタンをクリックして画面を更新してください:
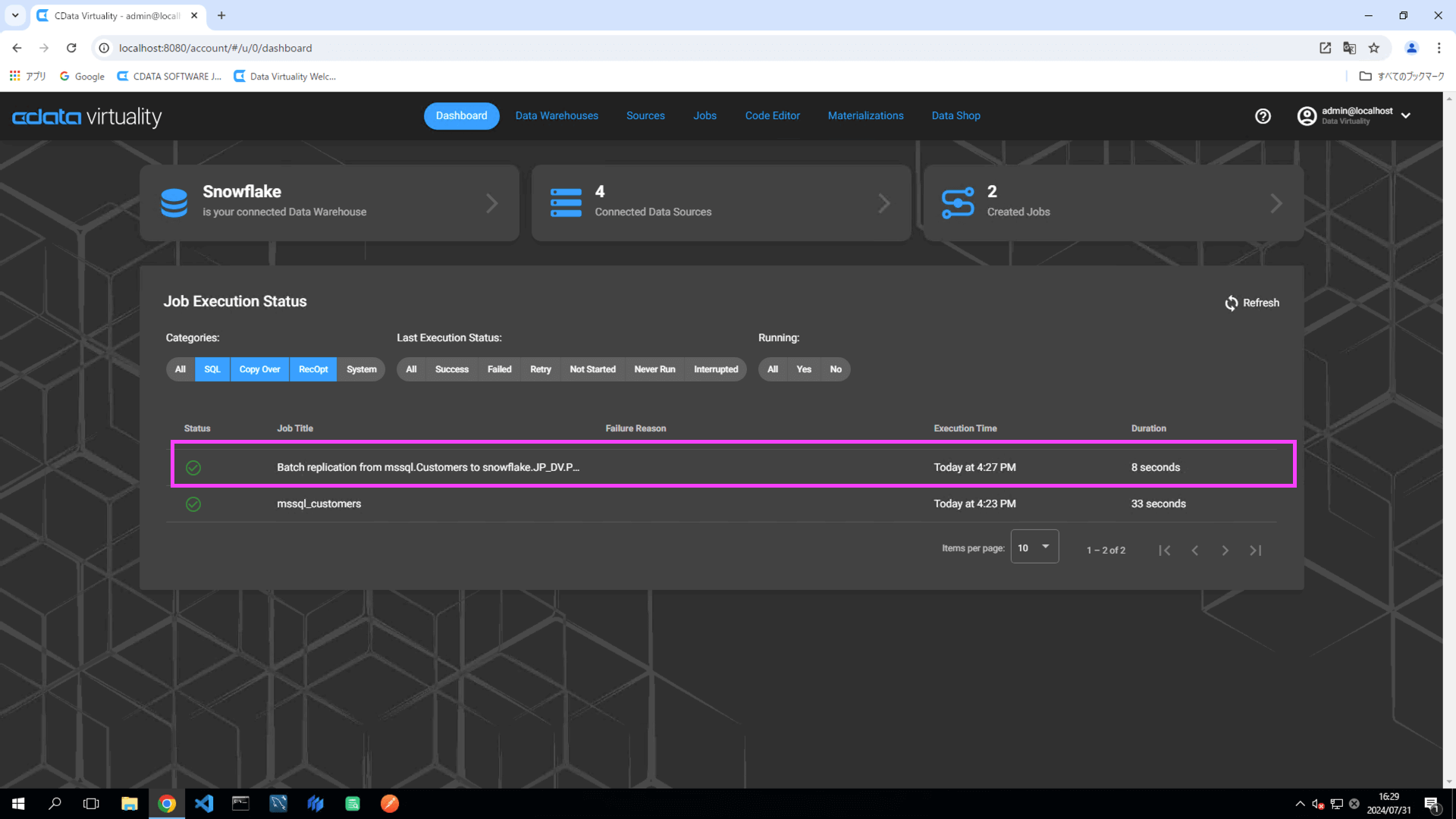
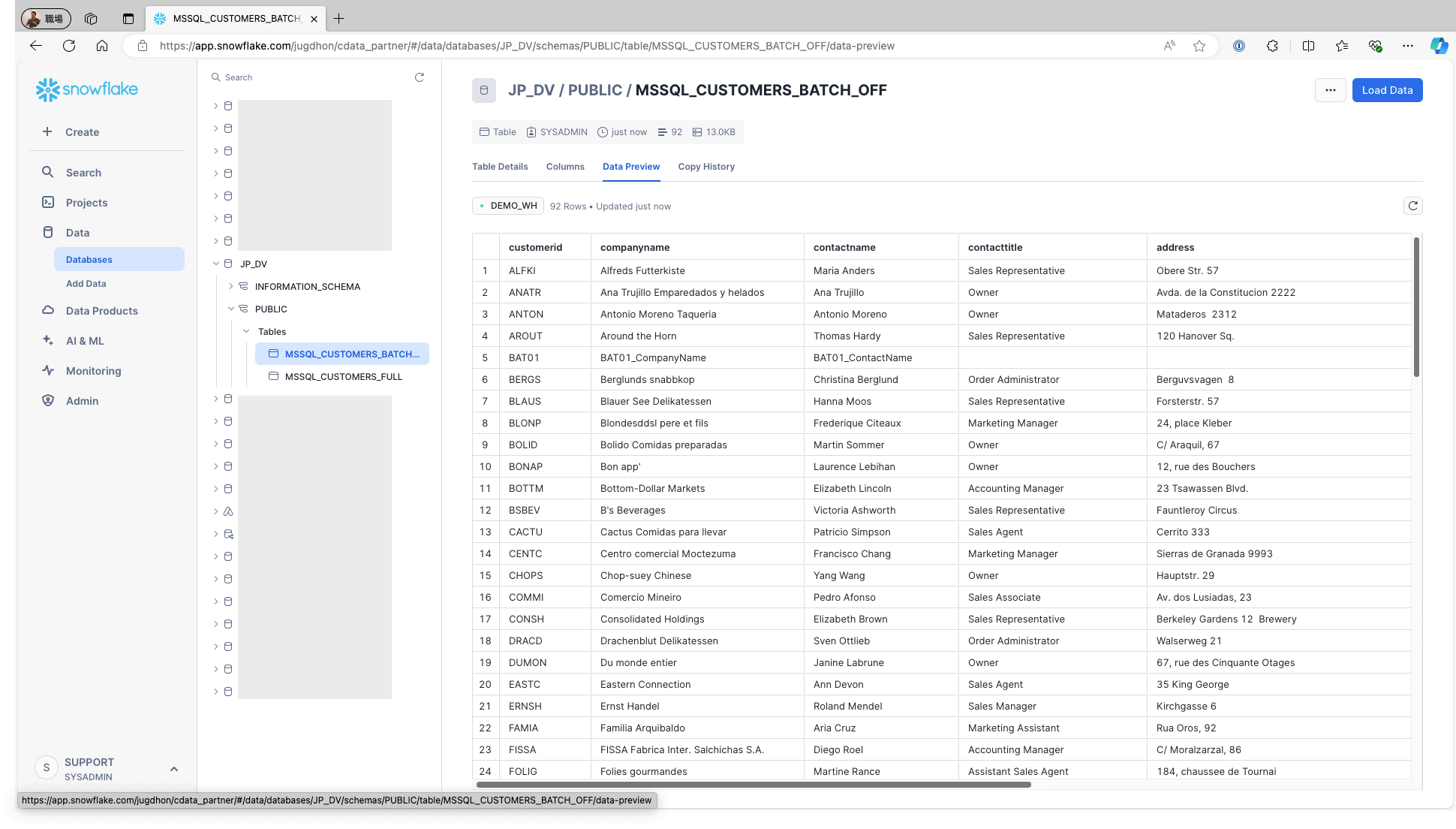
Snowflake にアクセスし、該当テーブルにデータが格納されていることを確認します:
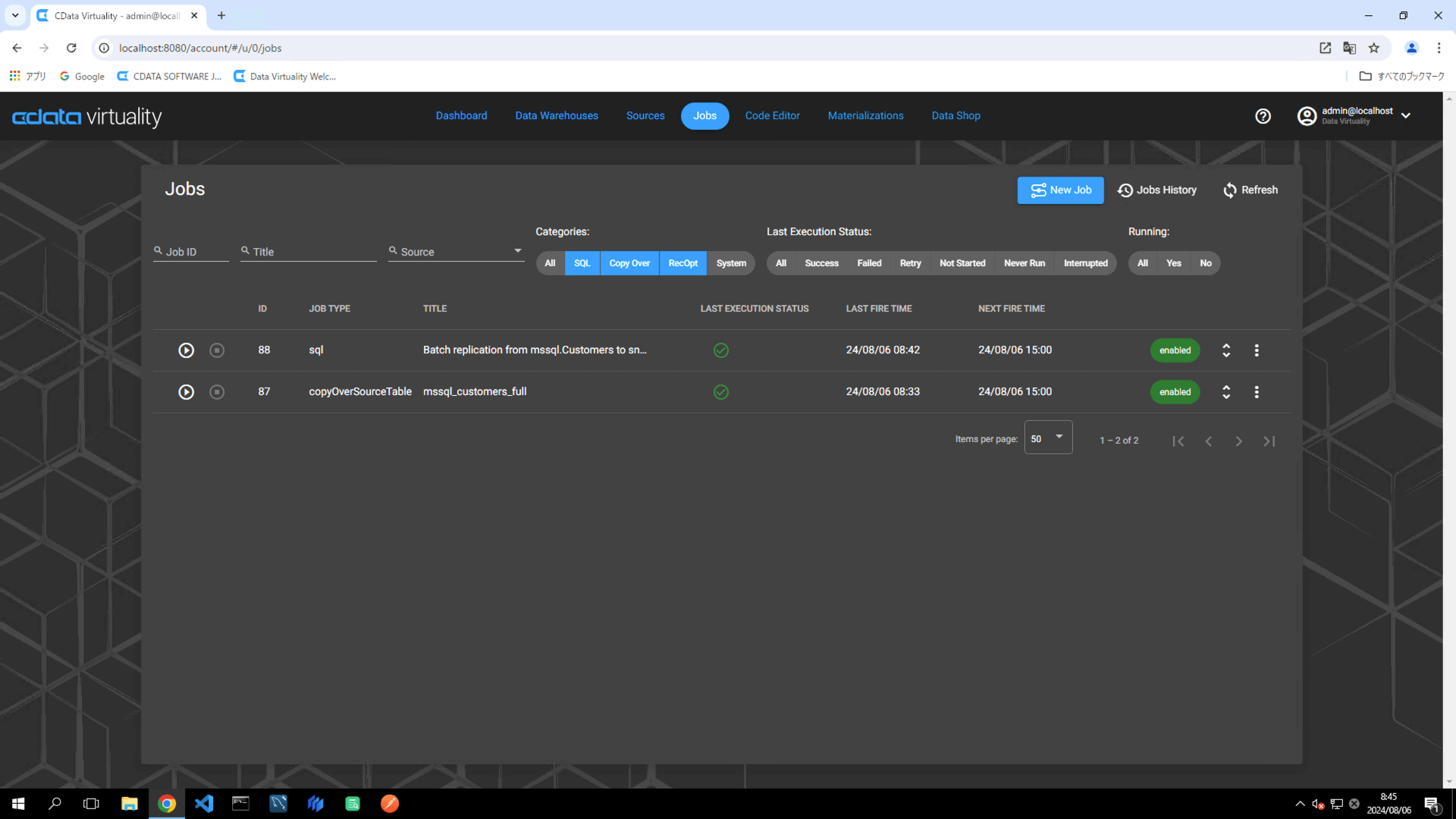
作成したジョブの詳細は、Jobs 画面からアクセスし、変更することができます。このジョブでは、JOB TYPE はsql に、TITLE はBatch replication from mssql.Customers to snowfl に設定されています:
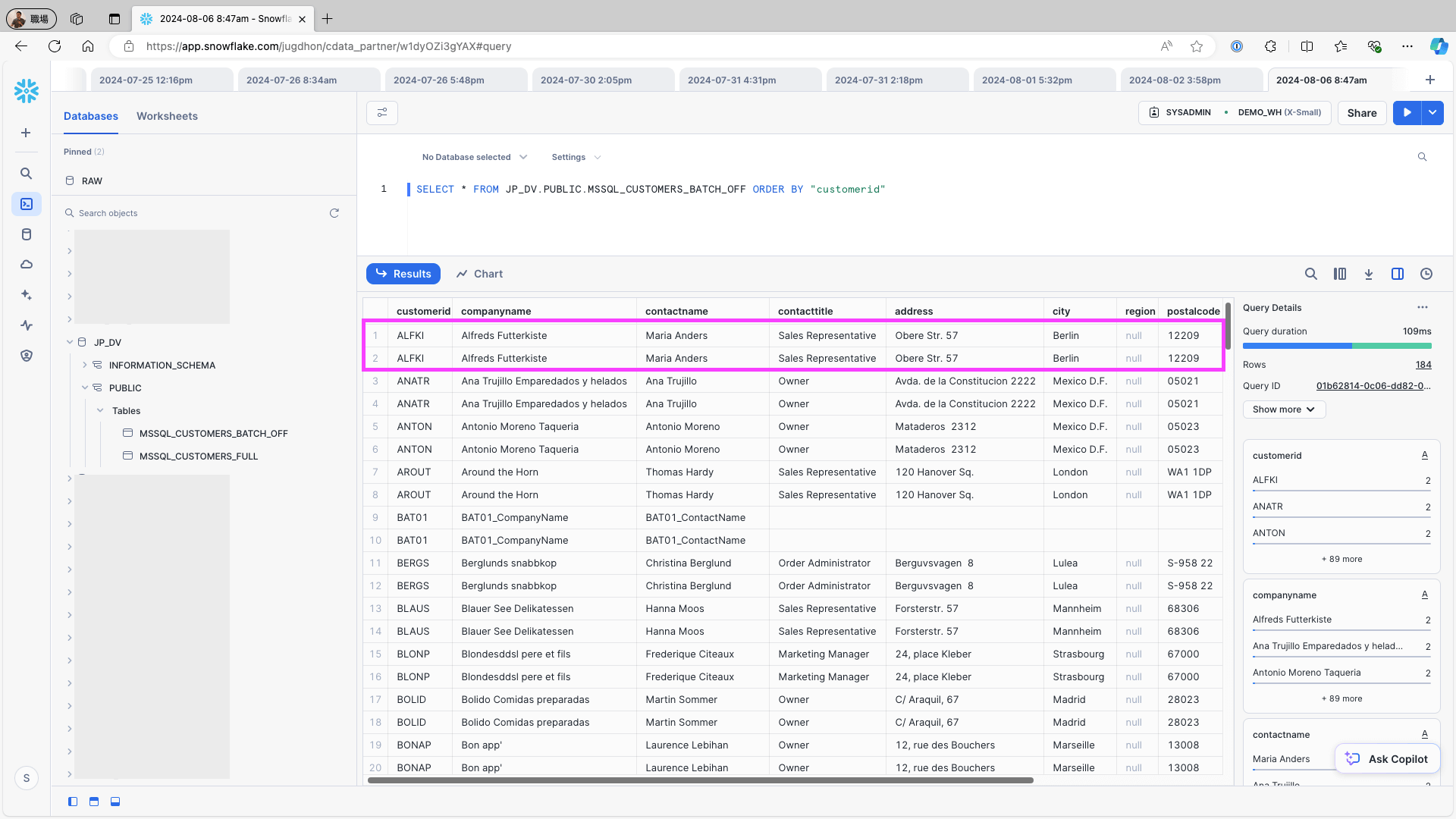
データがデータウェアハウス(例:Snowflake)に正しく保存されていることをテストするには、同じジョブを再実行します。Use identity field... トグルをON にしてジョブを実行した場合、ジョブを実行するたびにすべてのレコードが既存のテーブルに追加されるため、レコードが重複して登録されます。
Use identify field… トグルをON に切り替えた場合に何が起こるかをテストするには、以下のようにジョブを設定します:
Create Job 画面で、テーブルを選択します(例:Microsoft SQL Server のCustomers テーブル)。
レプリケーションタイプをBatch(バッチ更新)に設定します。
Use identity field... トグルをON にします。
Identity Field にはデーターソース側のテーブルでユニークなID ナンバーを生成するフィールド(例:CustomerID)を指定して次に進みます。
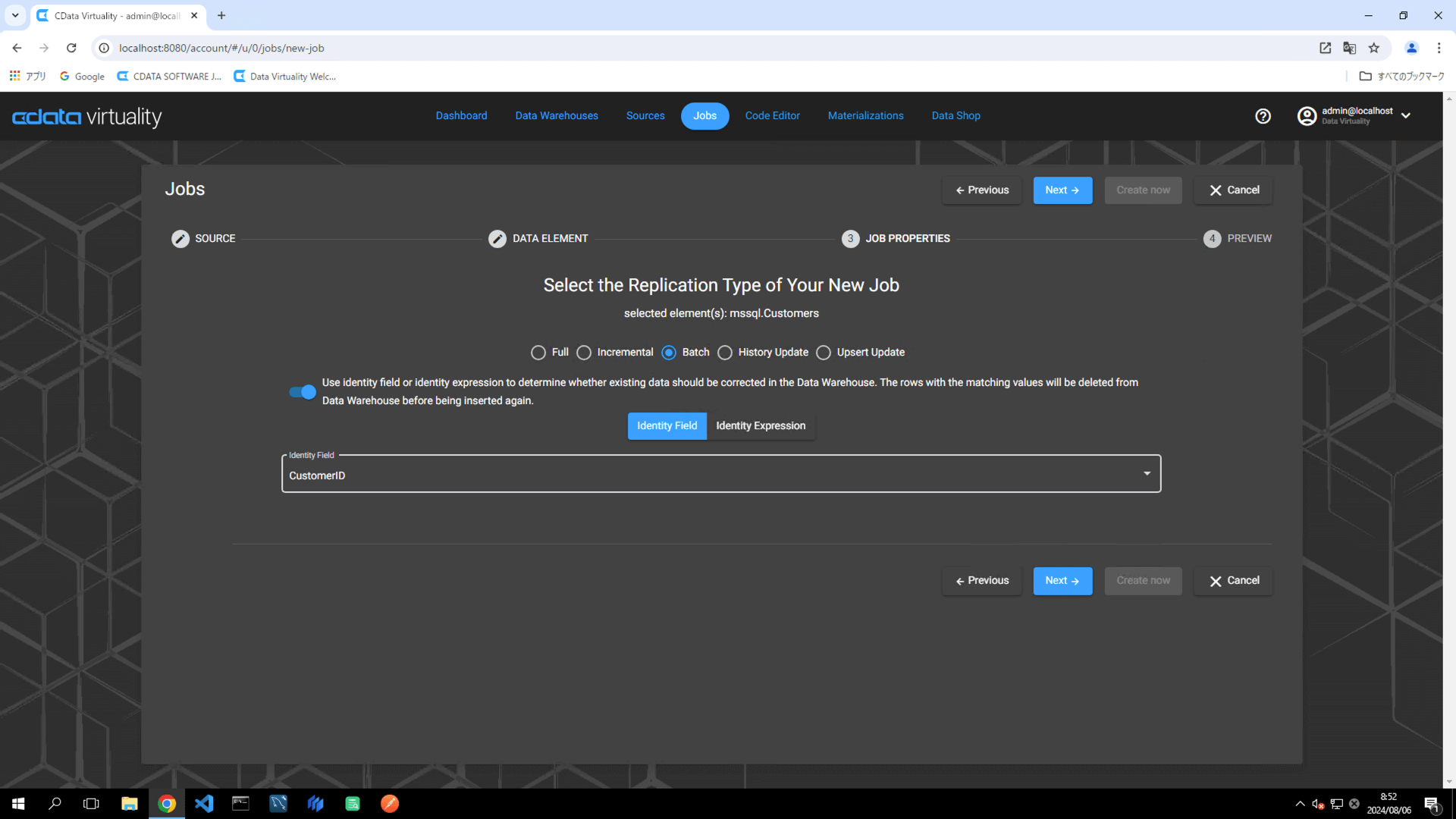
パイプライン構成に以下の要素を設定します:
Data Warehouse:対象のデータウェアハウスを選択します。
Target Schema:対象スキーマを指定します。
Title:パイプラインの名前を
mssql_customers_batch_onに変更します。Schedule:希望の実行スケジュールを設定します。
Start Immediately:すぐに実行する場合はトグルをON にします。
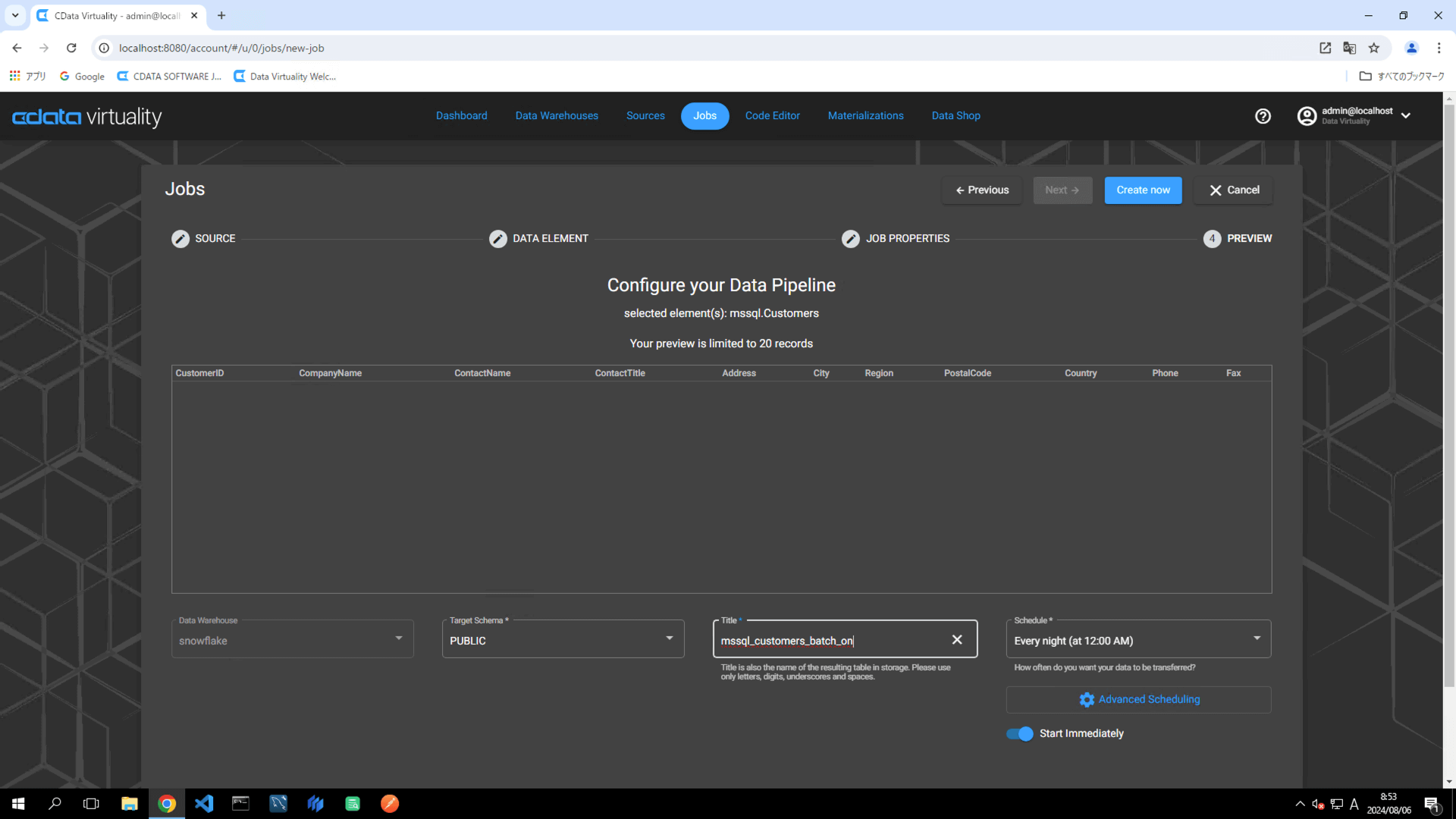
Create now ボタンをクリックしてレプリケーションジョブを実行します。ダッシュボード画面に移動し、ジョブの実行が正常に完了したことを確認します:
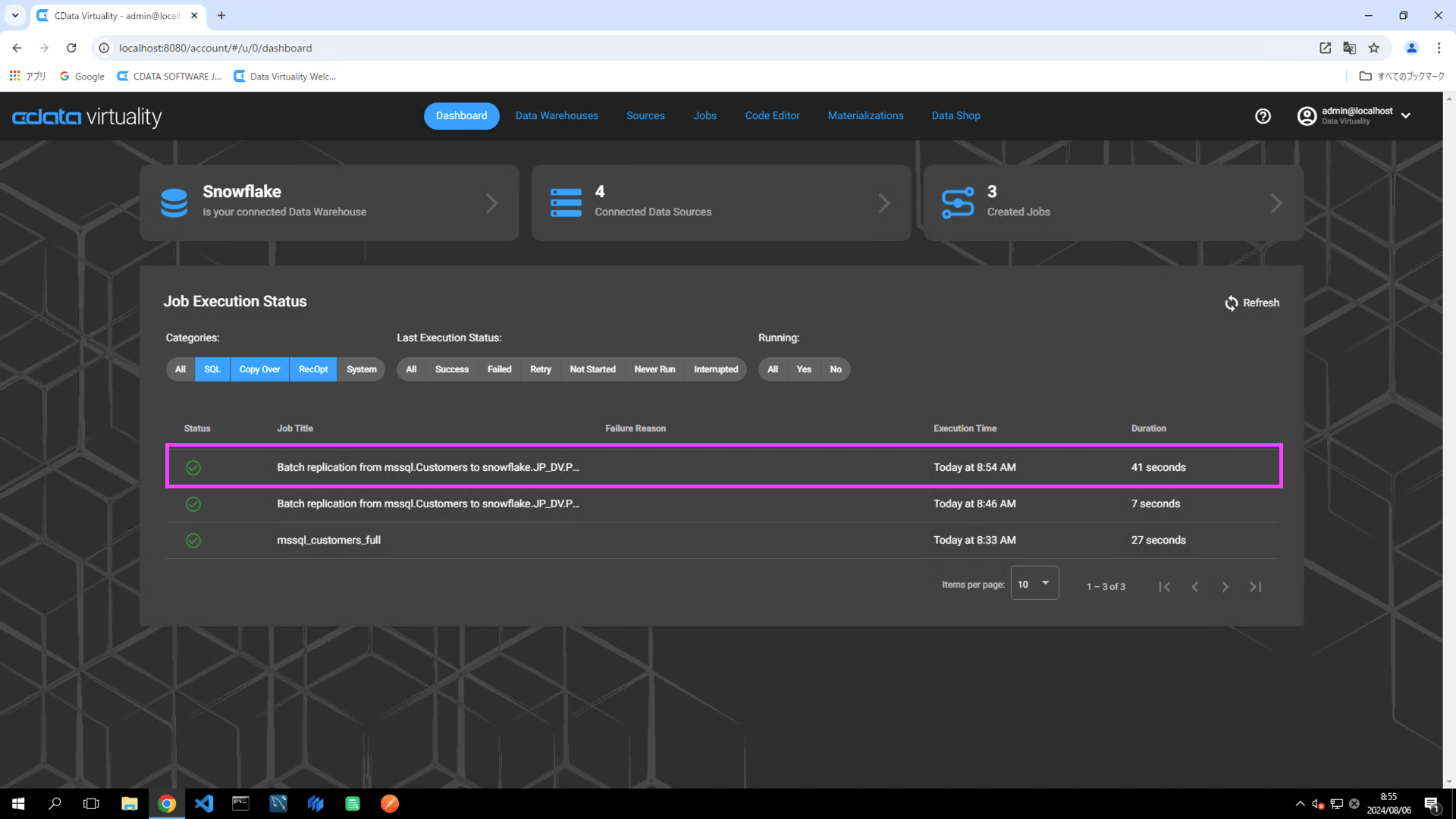
Snowflake にアクセスし、レプリケーション先のテーブルでデータが正常にレプリケートされたことを確認します。
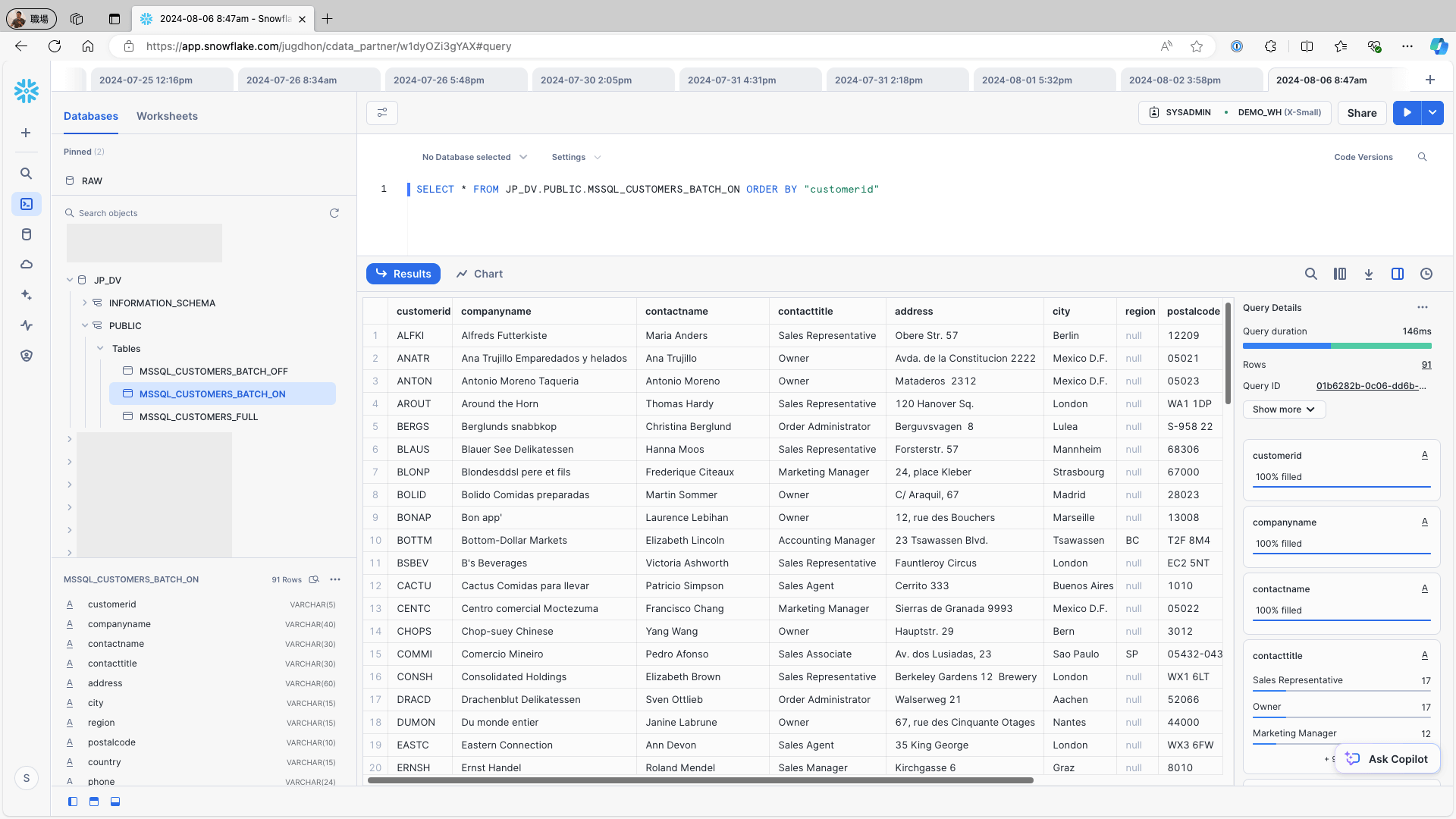
データソース(例:Microsoft SQL Server のCustomers テーブル)に新しいレコードを追加するには、次のクエリを使用してレプリケーションジョブを再実行します:
INSERT INTO Customers (CustomerID, CompanyName, ContactName, ContactTitle, Address, City, Region, PostalCode, Country, Phone, Fax) VALUES ('BAT01 ', 'BAT01_CompanyName', 'BAT01_ContactName', '', '', '', '', '', '');Snowflake にアクセスし、レプリケーション先のテーブルを確認します。データソースに新しく追加されたレコードがレプリケーション先のテーブルに反映されていることを確認し、重複レコードが生成されていないことを確認します:
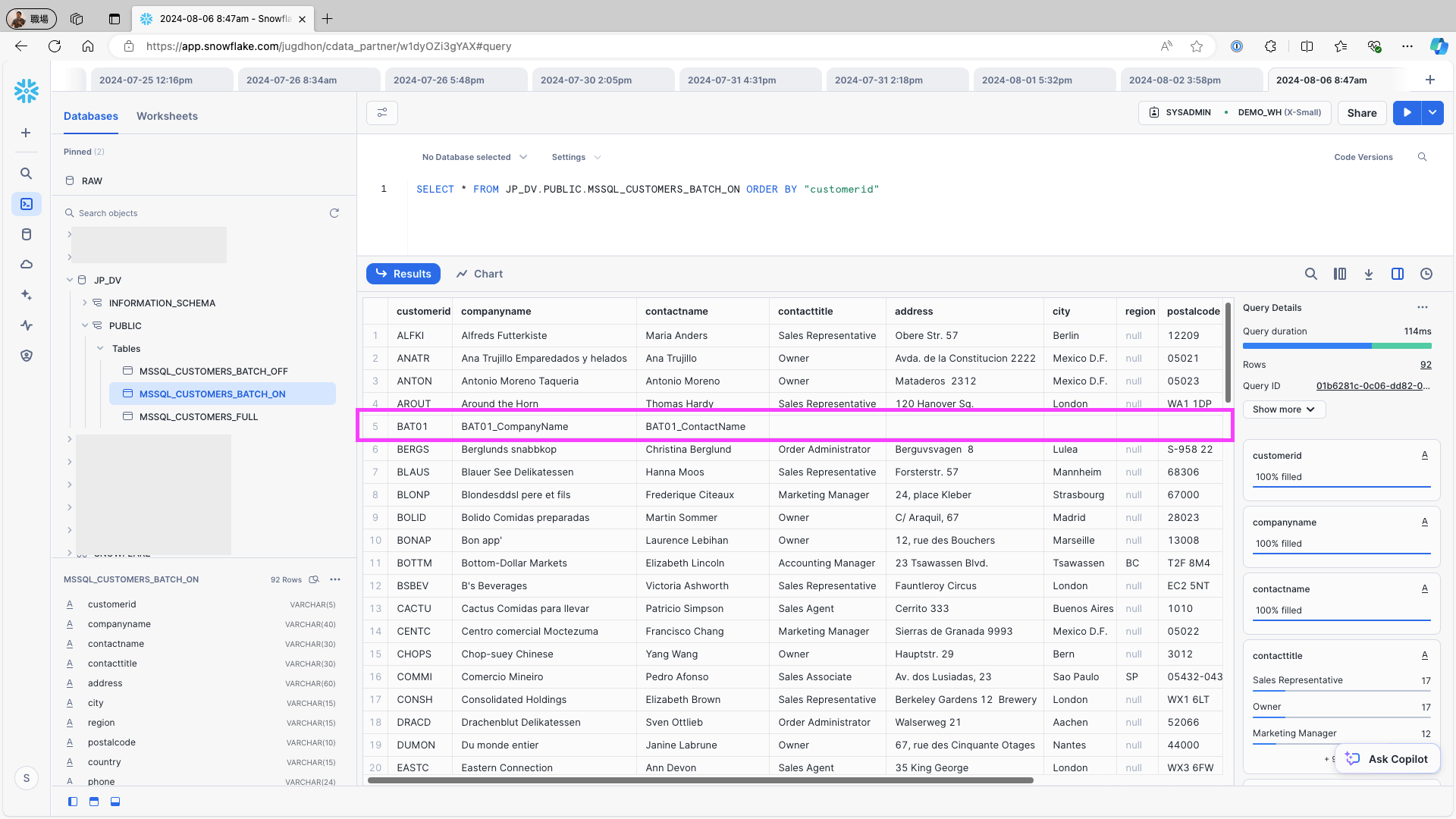
History Update
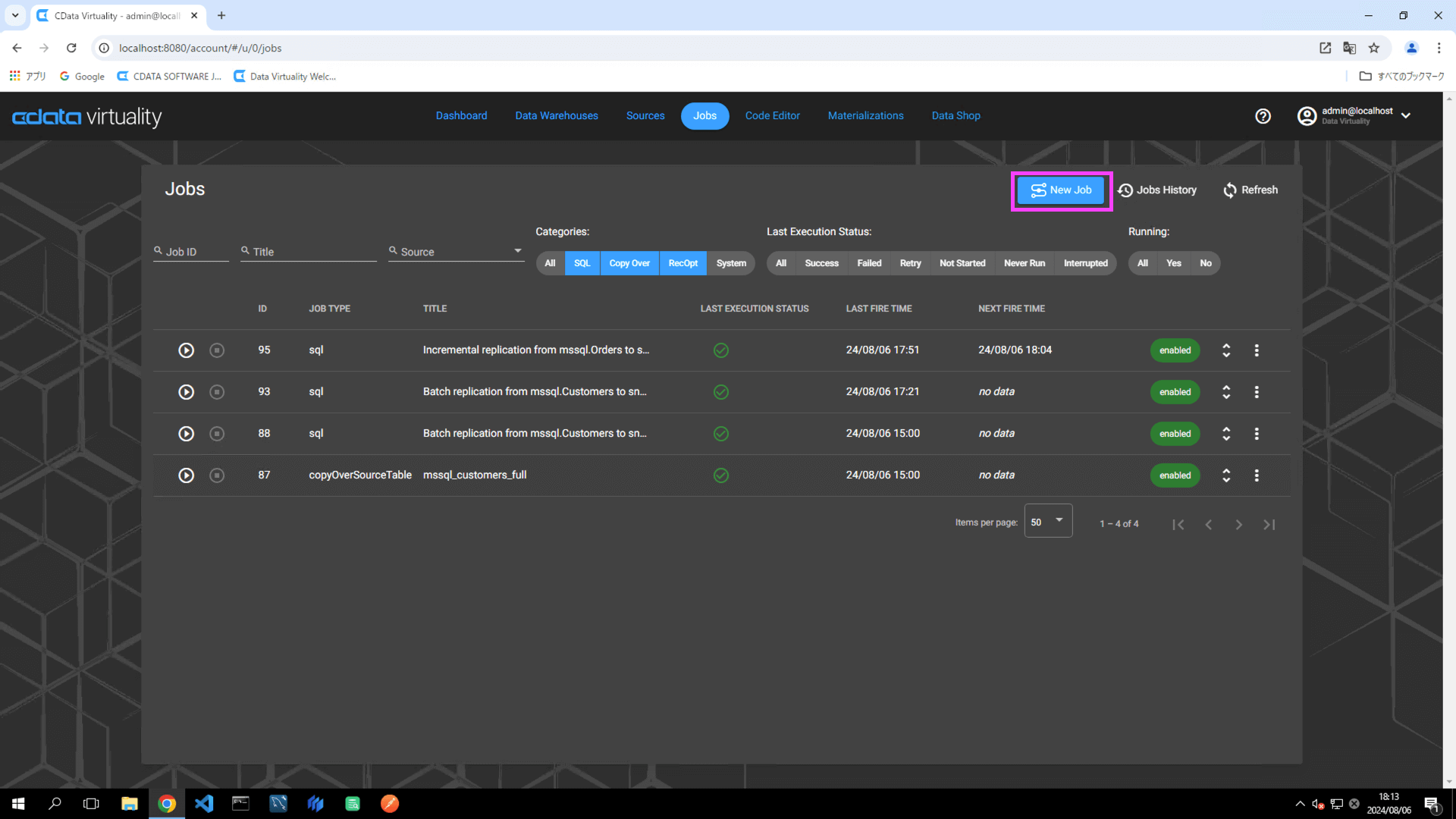
Jobs を開き、New Job ボタンをクリックします:
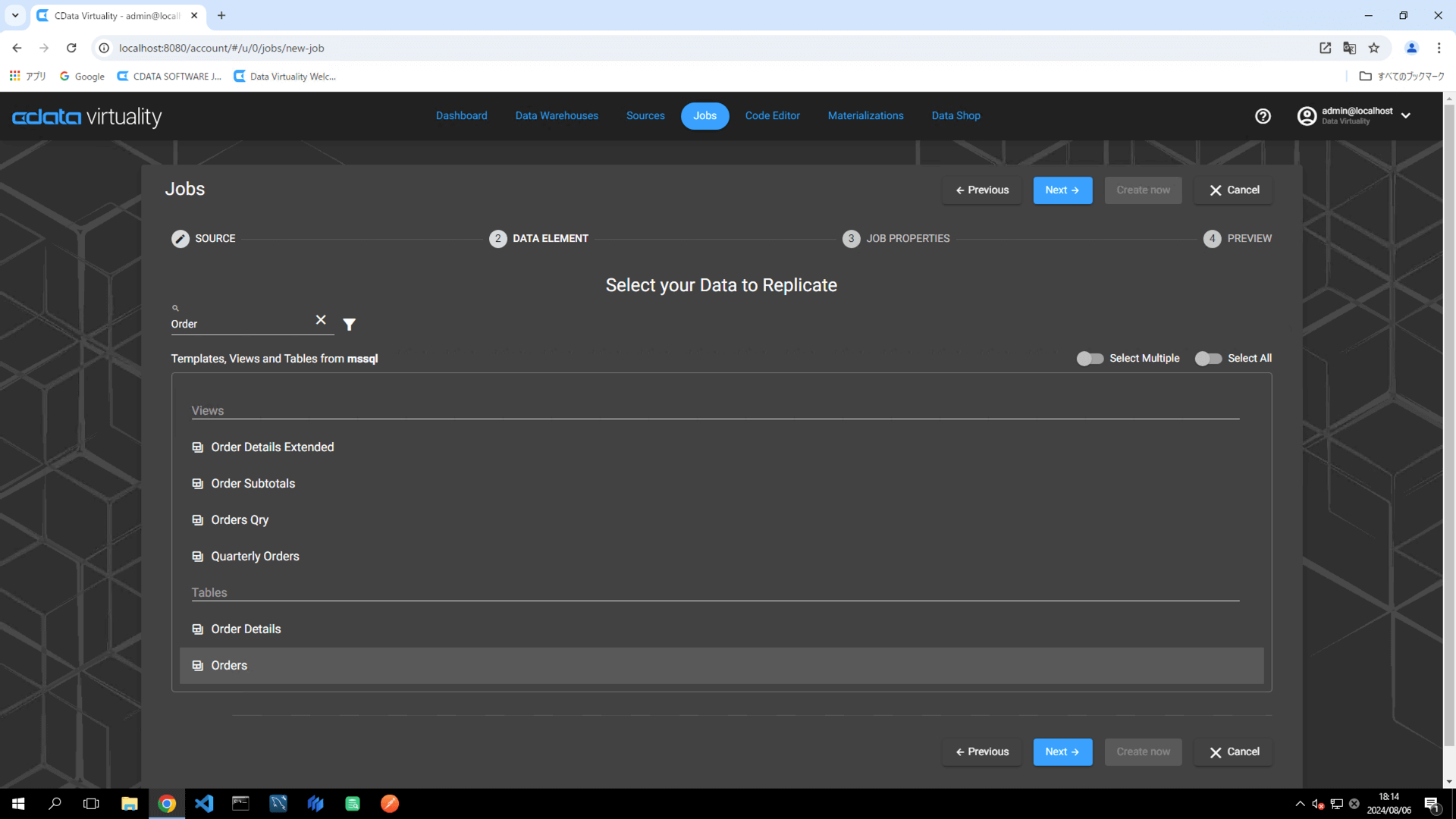
Select your Data to Replicate 画面で、レプリケートするテーブルを選択し、Next ボタンをクリックします:
For this example, the Orders table in Microsoft SQL Server is selected.
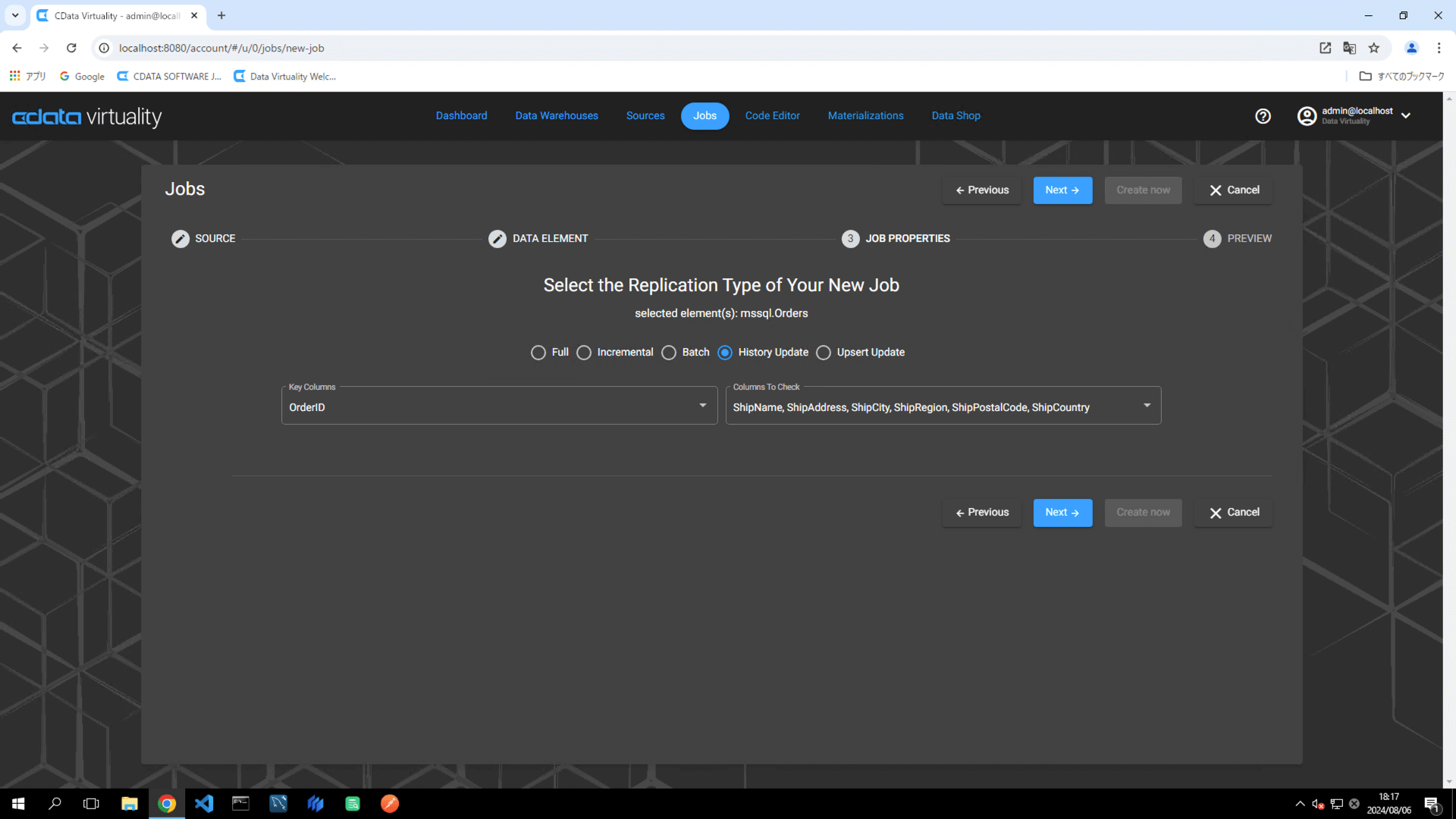
レプリケーション中の更新を正確に追跡するためには、以下が必要です:
Key Column:レコードを一意に特定するフィールド(例:OrderID)
Columns To Check:データの変更を監視するフィールド(例:Ship で始まる複数のフィールド)。
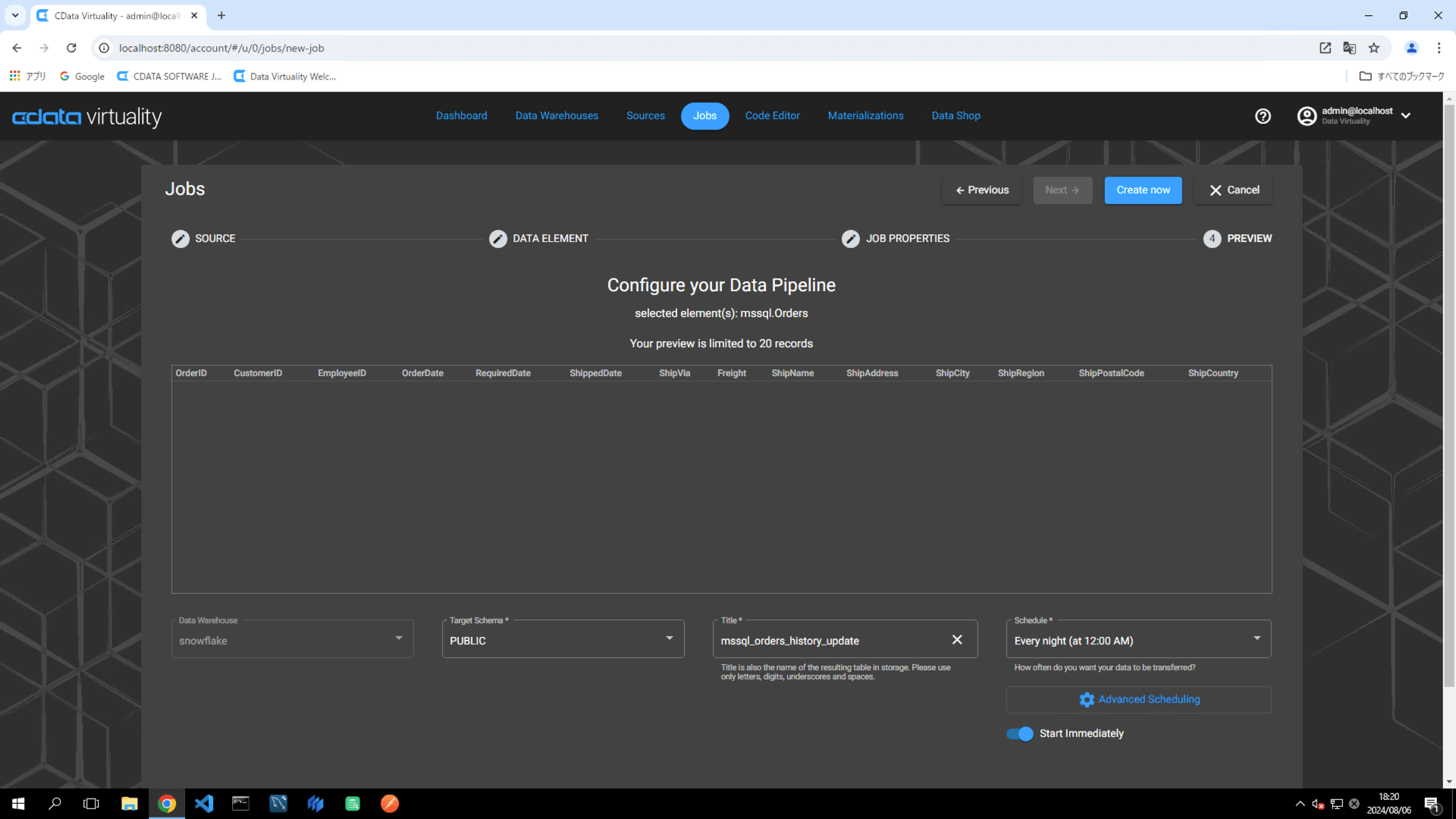
パイプライン構成に以下の要素を設定します:
Data Warehouse:対象のデータウェアハウスを選択します。
Target Schema:対象スキーマを指定します。
Title:パイプラインの名前を
mssql_orders_history_updateに変更します。Schedule:希望の実行スケジュールを設定します。
Start Immediately:すぐに実行する場合はトグルをON にします。
より柔軟なスケジュール設定を行うには、Advanced Scheduling ボタンをクリックします。
Create now ボタンをクリックしてレプリケーションジョブを実行します。
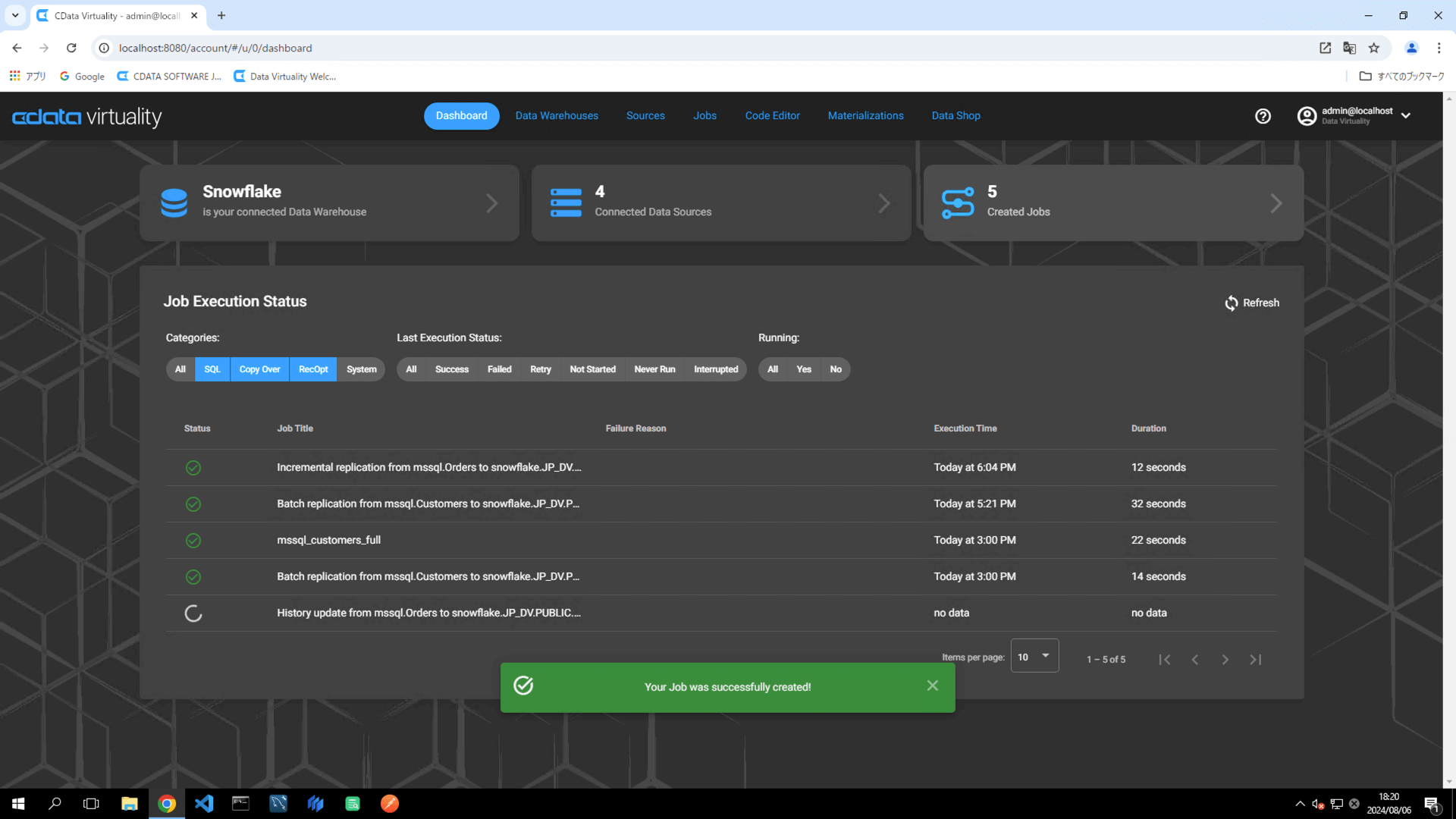
Dashboard 画面が開きます。緑色のバーが、ジョブが正常に作成されたことを示します:
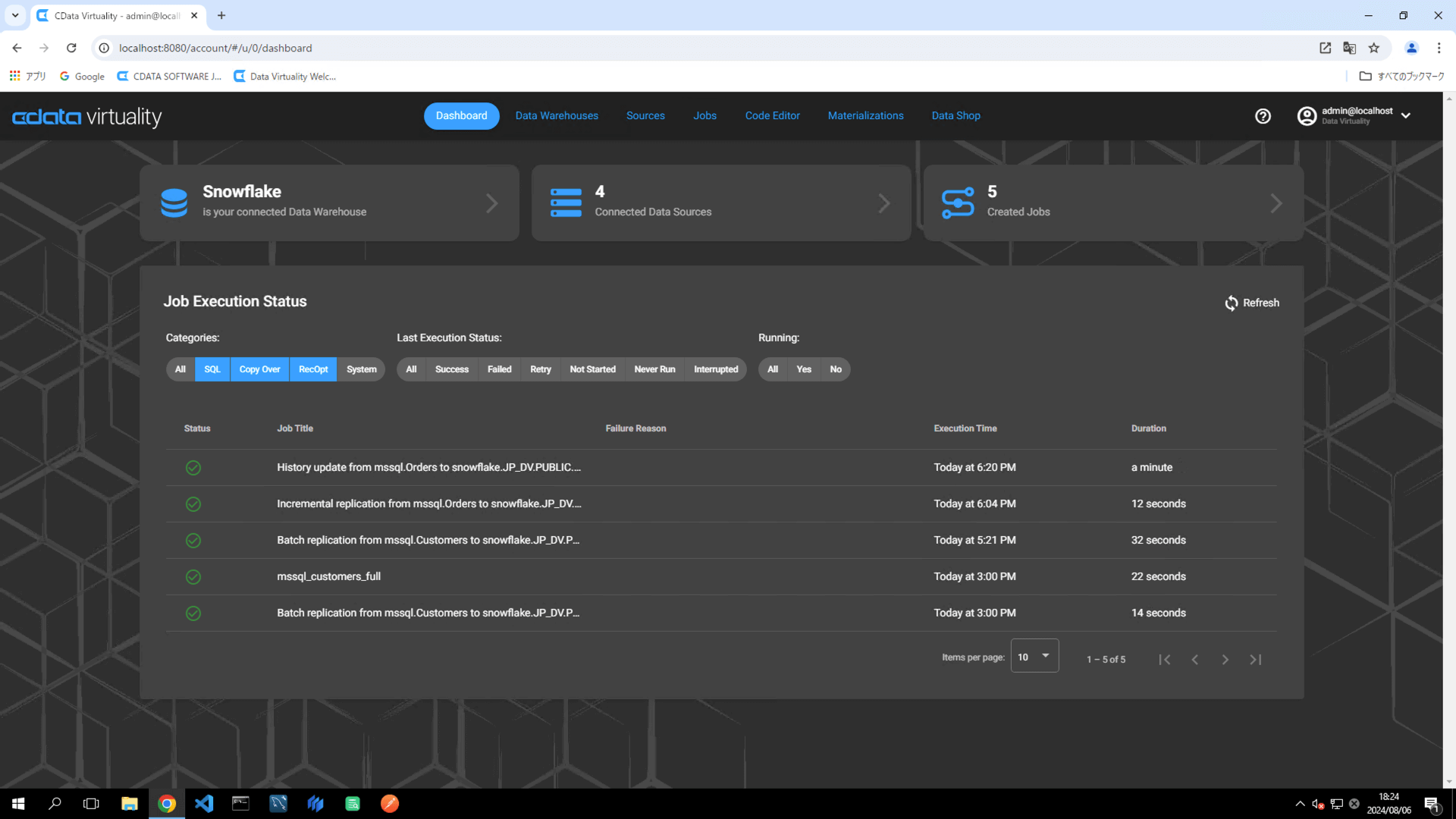
ジョブが実行されたら、Dashboard画面のStatus がSuccessful になっていることを確認します。ステータスが自動的に更新されない場合は、Refresh ボタンをクリックして画面を更新してください:
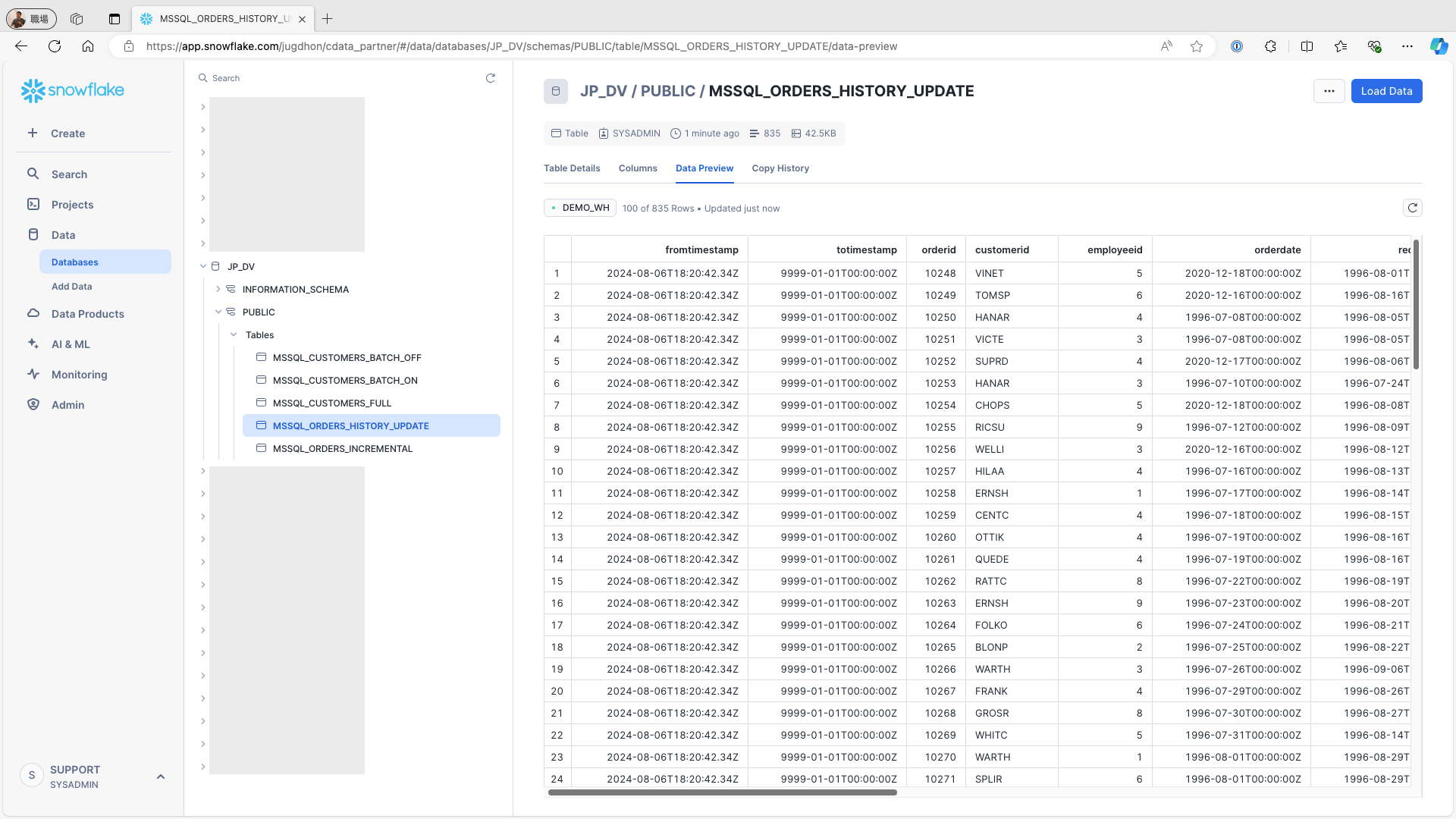
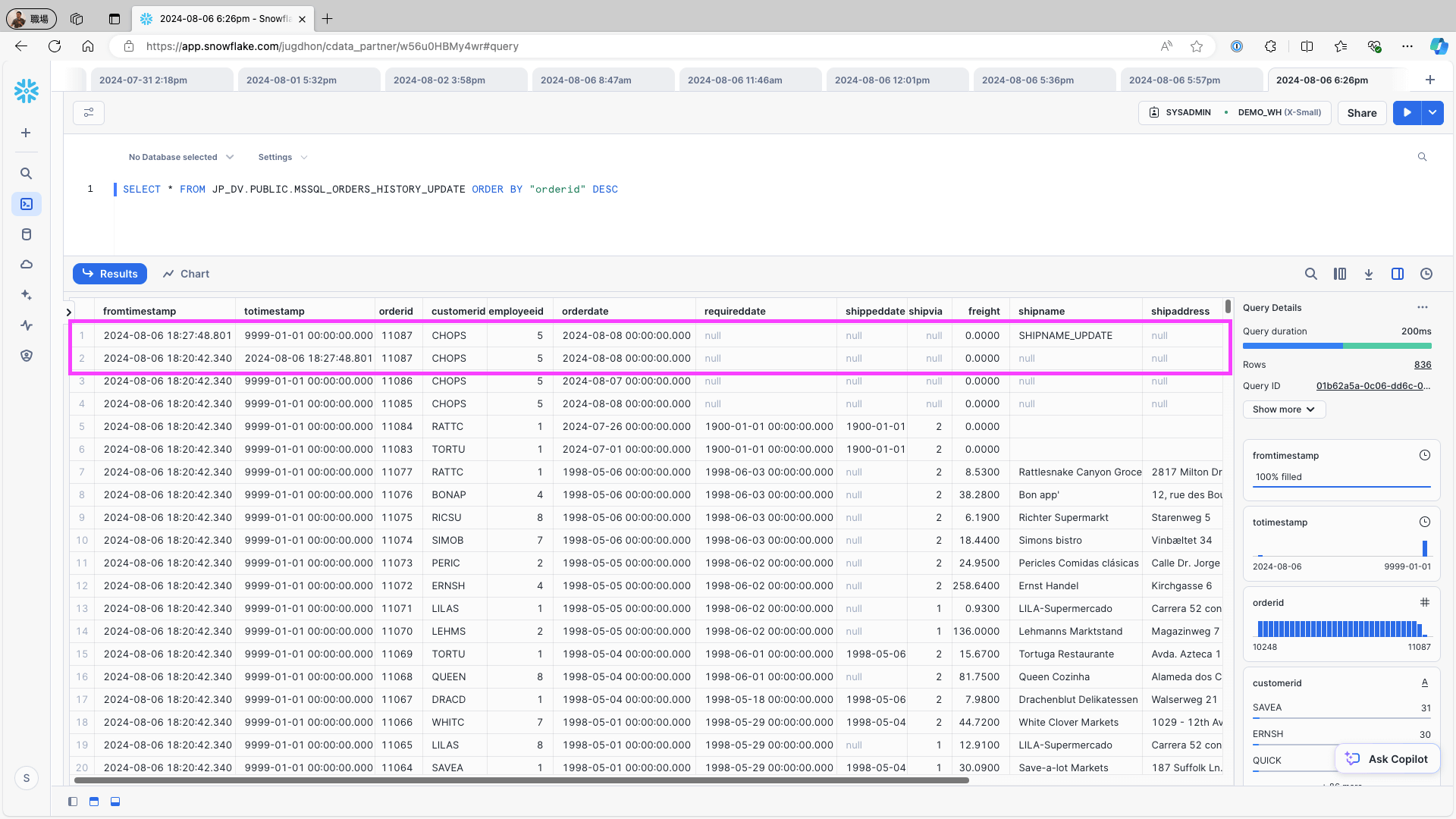
Snowflake にアクセスし、fromtimestamp およびtotimestamp フィールドがテーブルに追加されていることを確認します。レコードが正しく格納されていることを確認します:
データソース内の1レコード(例:Microsoft SQL Server のOrders テーブル)を変更するには、次のクエリを使用してレプリケーションジョブを再実行します:
UPDATE Orders SET shipname = 'SHIPNAME_UPDATE' WHERE OrderID = 11087;Snowflake にアクセスし、レプリケーション先のテーブルを確認します。データソースのレコードの更新履歴が、レコードとして正しく作成されていることを確認します:
Upsert Update
Jobs を開き、New Job ボタンをクリックします:
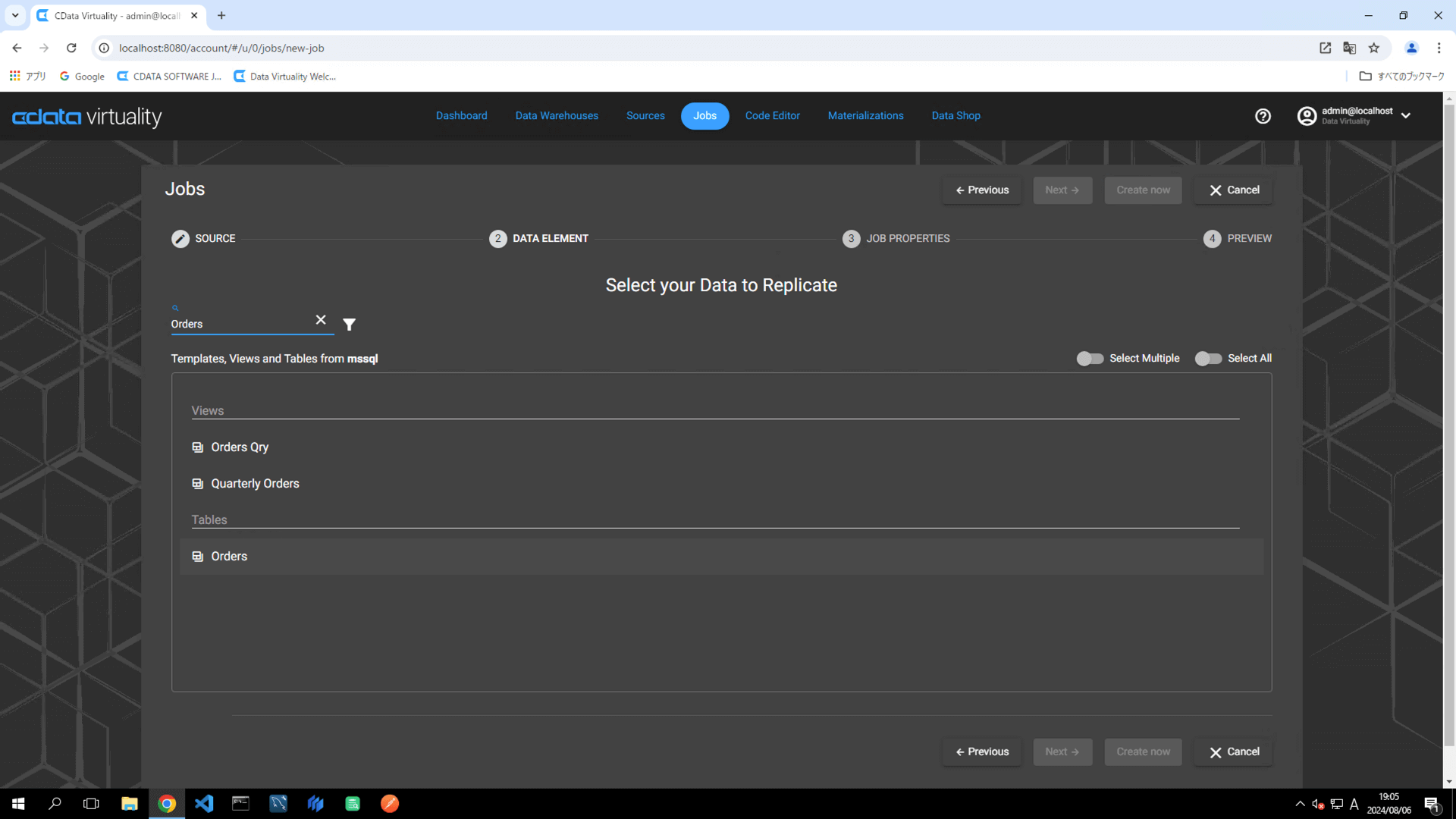
Select your Data to Replicate 画面で、レプリケートするテーブルを選択し、Next ボタンをクリックします:
For this example, the Orders table in Microsoft SQL Server is selected.
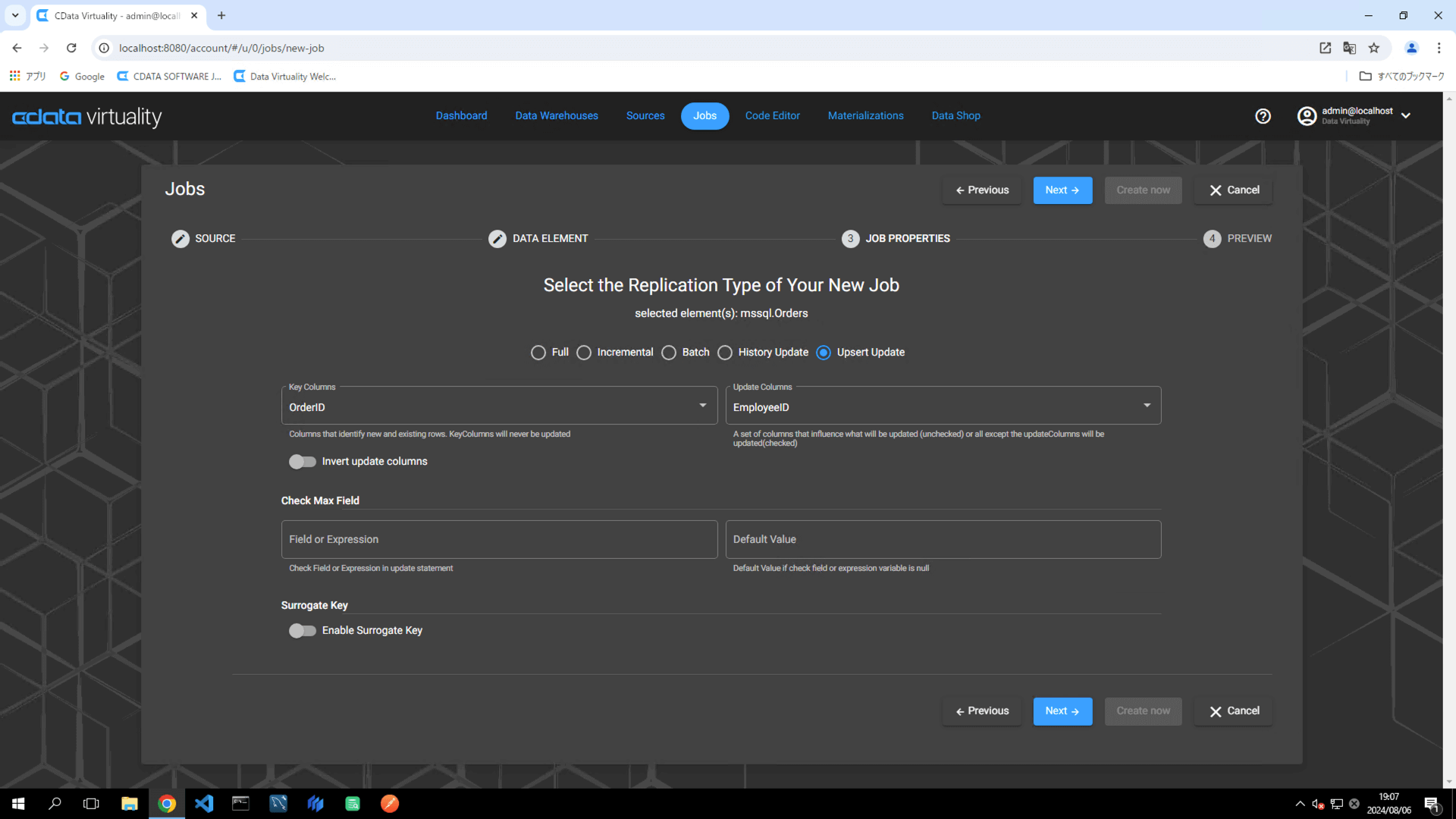
レプリケーション中の更新を正確に追跡するためには、以下が必要です:
Key Column:レコードを一意に特定するフィールド(例:OrderID)
Columns To Check:データの変更を監視するフィールド(例:EmployeeID)。
パイプライン構成に以下の要素を設定します:
Data Warehouse:対象のデータウェアハウスを選択します。
Target Schema:対象スキーマを指定します。
Title:パイプラインの名前を
mssql_orders_upsertに変更します。Schedule:希望の実行スケジュールを設定します。
Start Immediately:すぐに実行する場合はトグルをON にします。
より柔軟なスケジュール設定を行うには、Advanced Scheduling ボタンをクリックします。
Create now ボタンをクリックしてレプリケーションジョブを実行します:
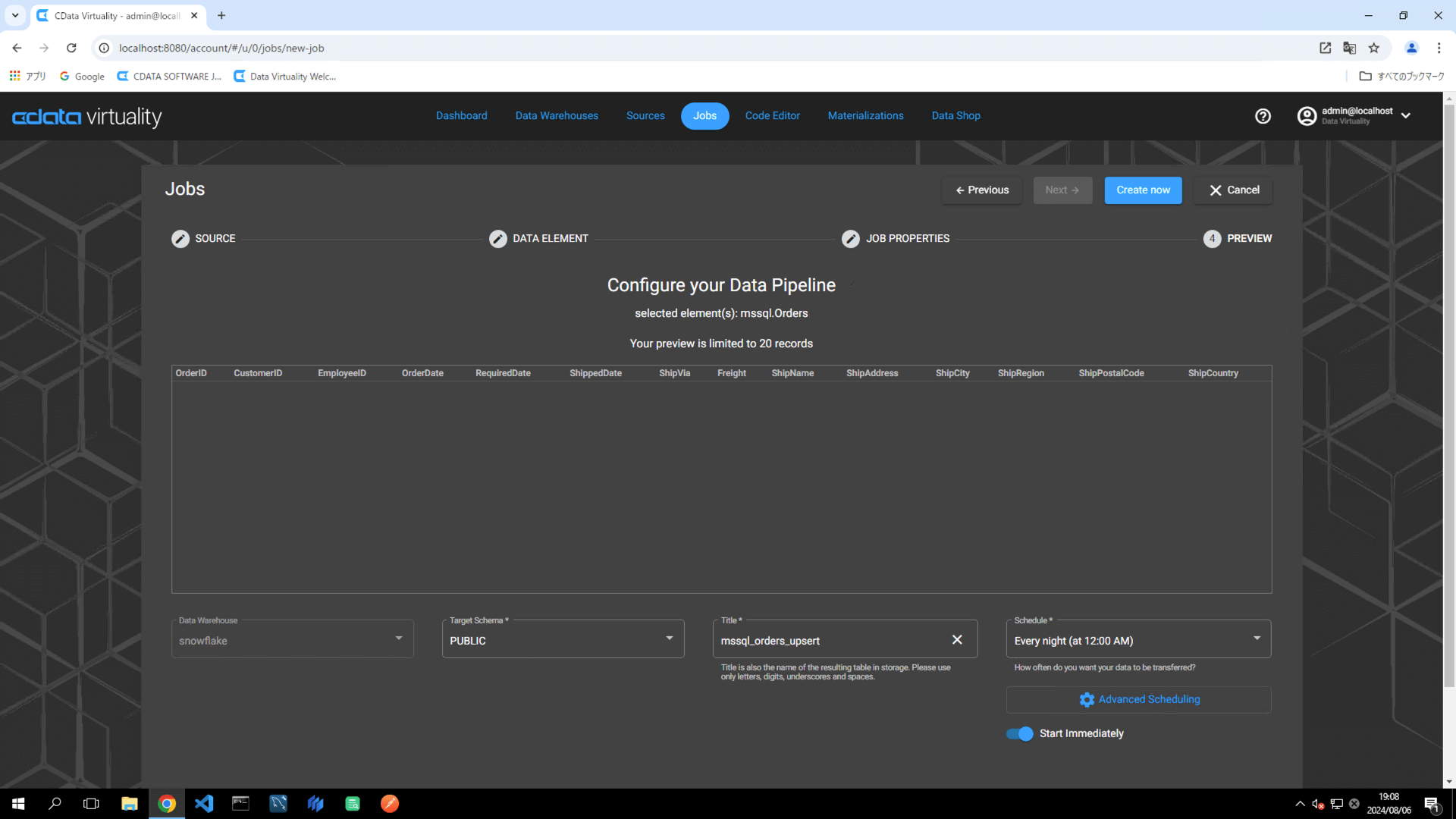
Dashboard 画面が開きます。緑色のバーが、ジョブが正常に作成されたことを示します:
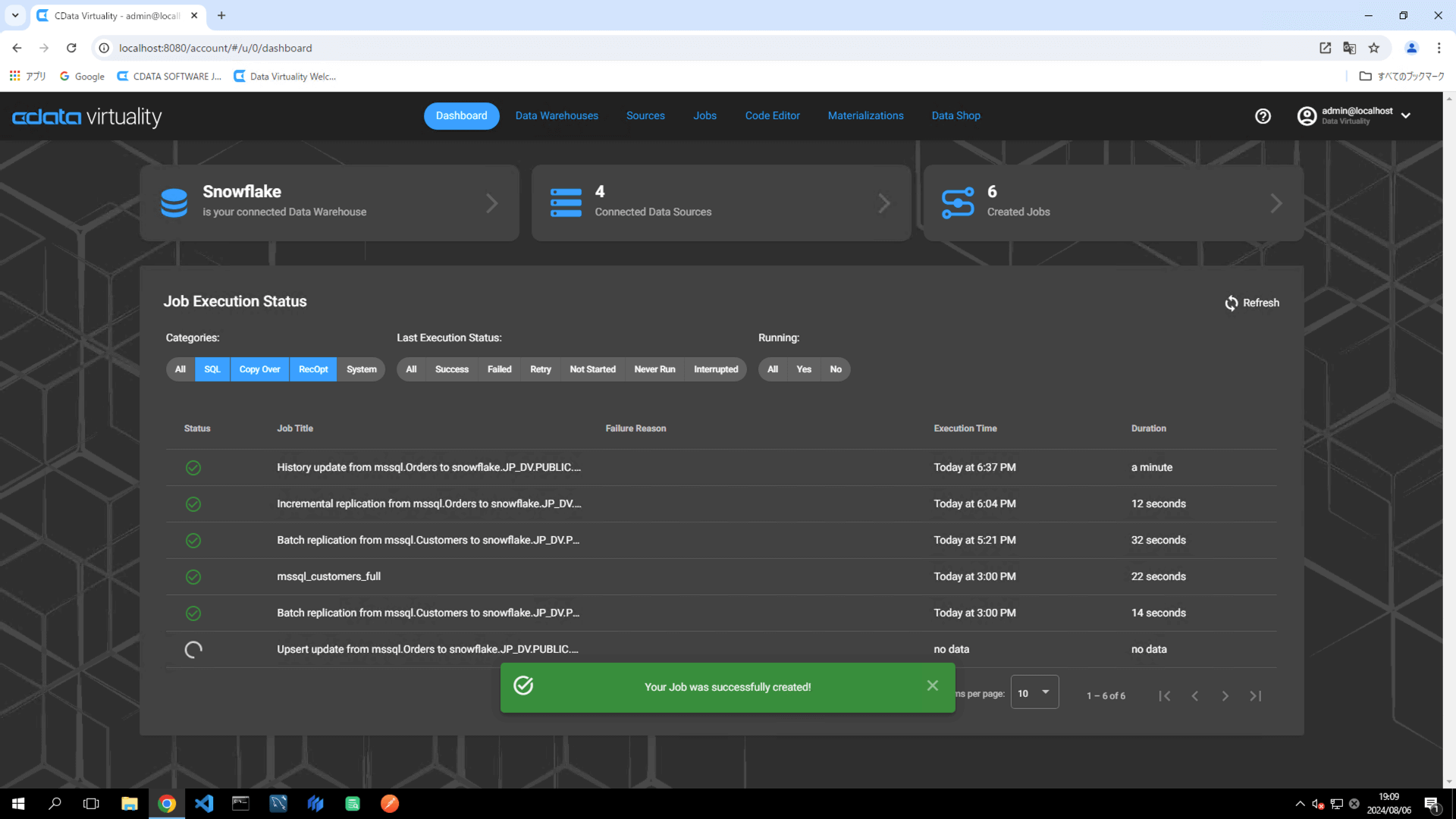
ジョブが実行されたら、Dashboard画面のStatus がSuccessful になっていることを確認します。ステータスが自動的に更新されない場合は、Refresh ボタンをクリックして画面を更新してください:
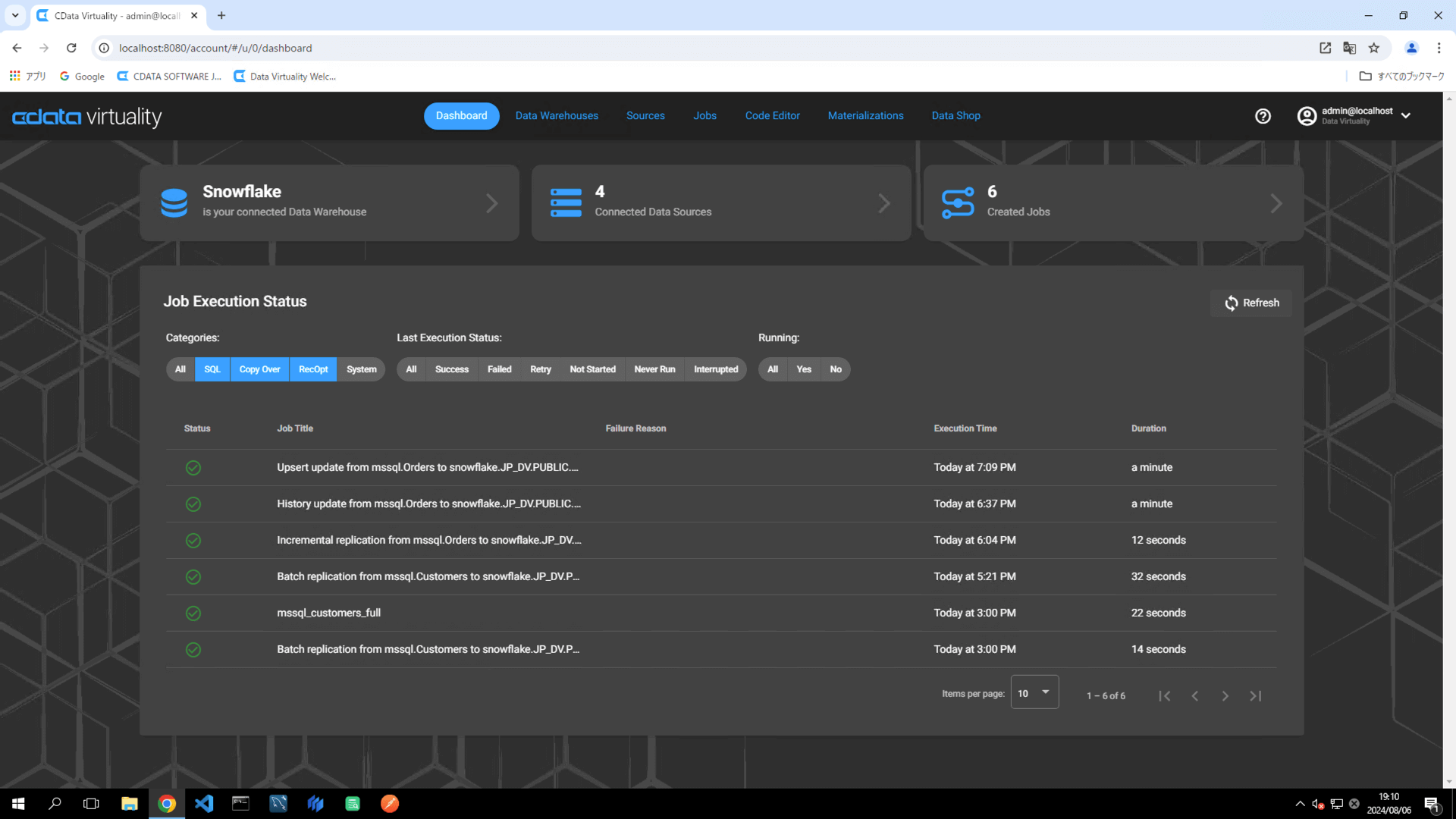
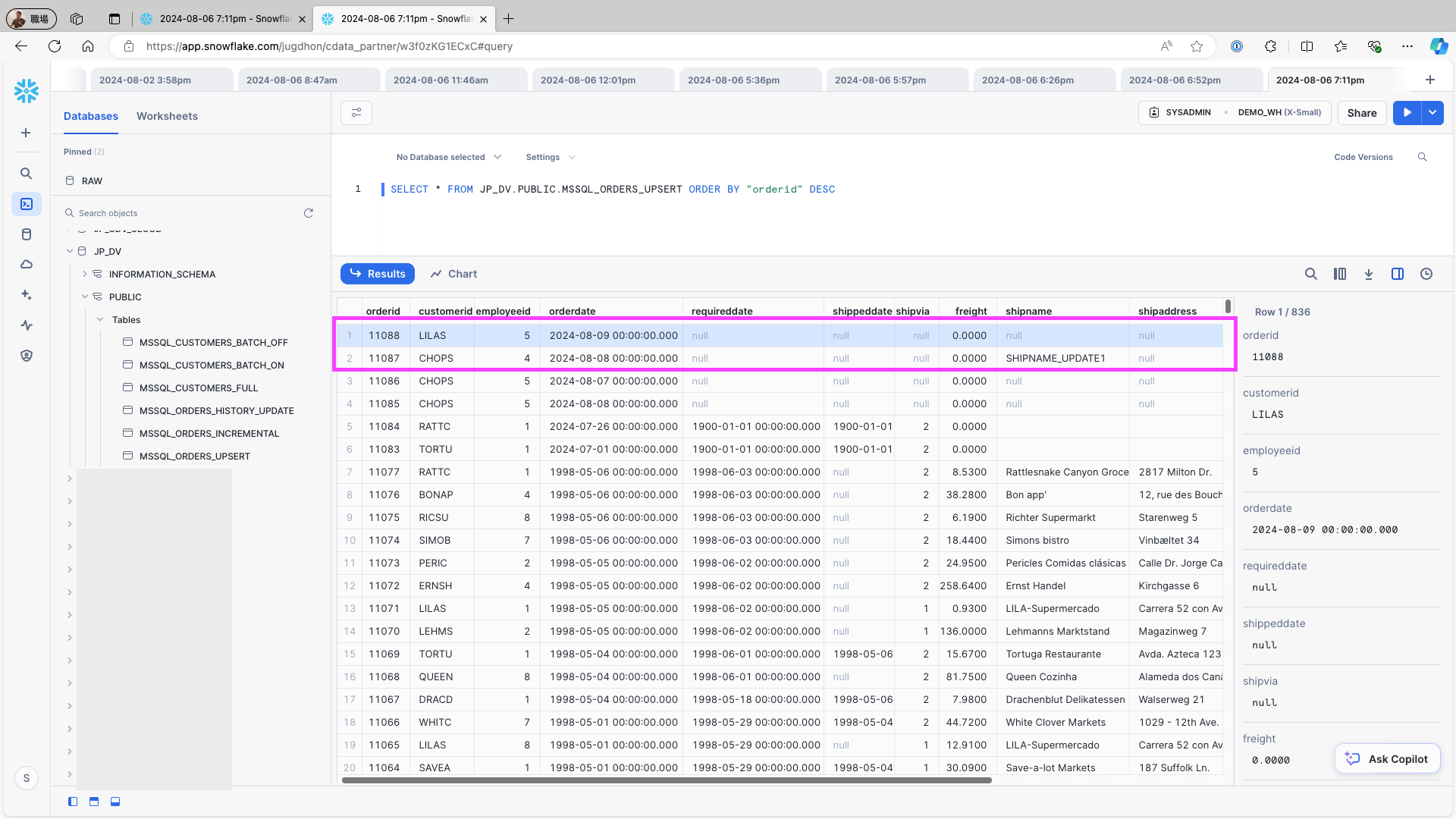
Snowflake にアクセスし、該当テーブルにデータが格納されていることを確認します:
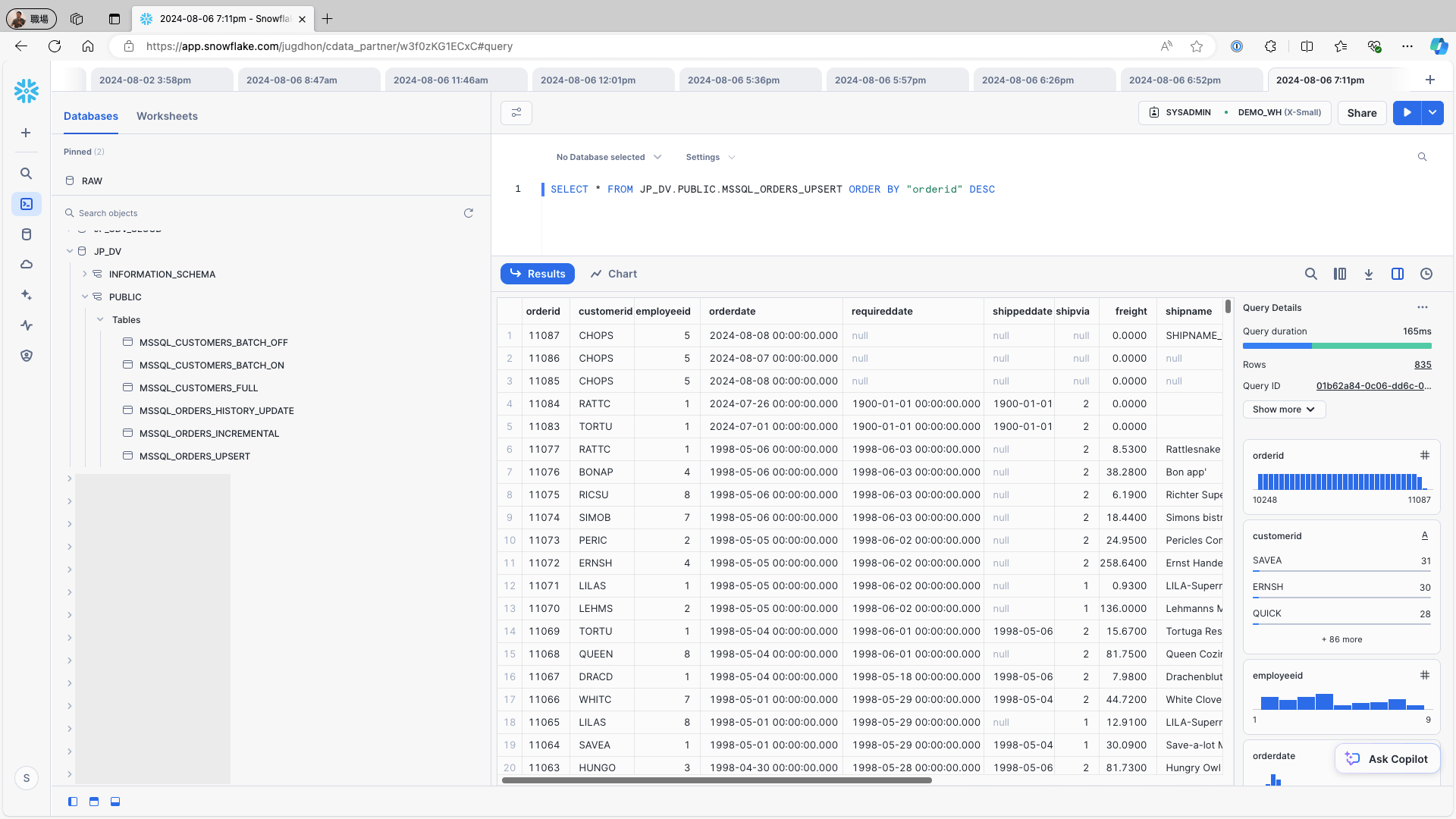
データソース内の1レコード(例:Microsoft SQL Server のOrders テーブル)を追加して変更するには、次のクエリを使用してレプリケーションジョブを再実行します:
INSERT INTO Orders (CustomerID, EmployeeID, OrderDate,ShipCountry) VALUES ('LILAS', 5, '2024/08/09', 'USA');UPDATE Orders SET employeeid = 4 WHERE OrderID = 11087;Snowflake にアクセスし、レプリケーション先のテーブルを確認します。データソースに新しく追加されたレコードと更新されたレコードが、レコードとして作成されていることを確認します:
See Also
Replication レプリケーションとその種類についての詳細はこちらをご覧ください